EveryDayVLA: A Vision-Language-Action Model for Affordable Robotic Manipulation
作者: Samarth Chopra, Alex McMoil, Ben Carnovale, Evan Sokolson, Rajkumar Kubendran, Samuel Dickerson
分类: cs.RO, cs.CV
发布日期: 2025-11-07
备注: Submitted to ICRA 2026
💡 一句话要点
EveryDayVLA:低成本机器人操作的视觉-语言-动作模型
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人操作 低成本机器人 自适应规划 运动不确定性
📋 核心要点
- 现有VLA模型依赖昂贵硬件,难以处理复杂场景,限制了其应用。
- EveryDayVLA采用低成本机械臂和统一模型,实现离散与连续动作的联合输出。
- 自适应水平集成模型监控运动不确定性,触发重规划,提升安全性和可靠性。
📝 摘要(中文)
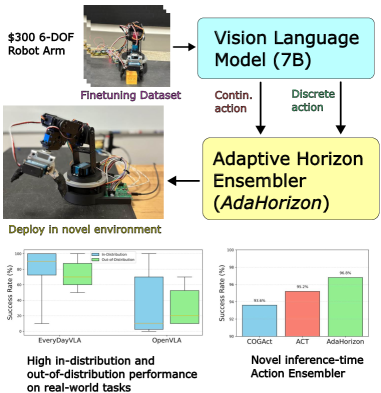
视觉-语言-动作(VLA)模型能够将视觉输入和语言指令直接映射到机器人动作,但它们通常依赖于昂贵的硬件,并且难以应对新颖或杂乱的场景。我们提出了EveryDayVLA,一种6自由度机械臂,其组装成本低于300美元,能够处理适度的有效载荷和工作空间。一个统一的模型联合输出离散和连续动作,并且我们的自适应水平集成模型监控运动不确定性,以触发即时重新规划,从而实现安全可靠的操作。在LIBERO上,EveryDayVLA达到了最先进的成功率,并且在真实世界测试中,其在同分布数据上优于先前方法49%,在异分布数据上优于先前方法34.9%。通过将最先进的VLA与具有成本效益的硬件相结合,EveryDayVLA普及了对机器人基础模型的使用,并为在家庭和研究实验室中的经济使用铺平了道路。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型通常依赖于昂贵的机器人硬件,这限制了它们在资源有限的环境中的应用。此外,这些模型在面对新颖或杂乱的真实世界场景时,性能往往会显著下降,缺乏足够的泛化能力。因此,需要一种能够在低成本硬件上运行,并且在复杂环境中具有鲁棒性的VLA模型。
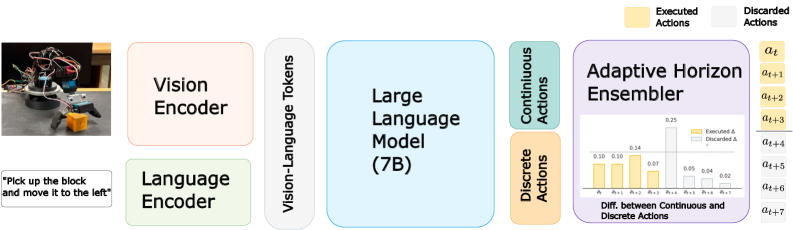
核心思路:EveryDayVLA的核心思路是结合低成本的机器人硬件和一个能够有效处理视觉和语言输入的VLA模型。通过优化硬件设计,降低了机器人的整体成本,使其更容易被广泛采用。同时,通过设计一个能够联合输出离散和连续动作的统一模型,提高了机器人的控制精度和灵活性。此外,引入自适应水平集成模型来监控运动不确定性,并在必要时触发重新规划,从而确保机器人的安全可靠运行。
技术框架:EveryDayVLA的整体框架包括三个主要组成部分:低成本的6自由度机械臂、视觉-语言-动作模型以及自适应水平集成模块。机械臂负责执行具体的动作,视觉-语言-动作模型负责根据视觉输入和语言指令生成动作指令,自适应水平集成模块负责监控运动不确定性并触发重新规划。整个系统通过ROS(机器人操作系统)进行集成和控制。
关键创新:EveryDayVLA的关键创新在于以下几个方面:1)低成本的硬件设计,使得VLA模型能够在更广泛的场景中应用;2)统一的动作输出模型,能够同时控制离散和连续动作,提高了机器人的控制精度和灵活性;3)自适应水平集成模块,能够有效监控运动不确定性,并在必要时触发重新规划,提高了机器人的安全性和可靠性。
关键设计:EveryDayVLA的关键设计包括:1)机械臂的结构设计,采用模块化设计,降低了制造成本;2)视觉-语言-动作模型的网络结构,采用Transformer架构,能够有效处理视觉和语言输入;3)自适应水平集成模块的算法设计,采用卡尔曼滤波等方法来估计运动不确定性,并根据不确定性的大小来调整规划的水平。
🖼️ 关键图片

📊 实验亮点
EveryDayVLA在LIBERO数据集上达到了最先进的成功率。在真实世界测试中,EveryDayVLA在同分布数据上比现有方法提高了49%,在异分布数据上提高了34.9%。这些结果表明,EveryDayVLA在真实世界环境中具有很强的鲁棒性和泛化能力,证明了其低成本硬件和先进算法的有效性。
🎯 应用场景
EveryDayVLA具有广泛的应用前景,包括家庭服务机器人、教育机器人、小型制造自动化等。其低成本的特性使得它能够被广泛应用于资源有限的环境中,例如家庭和小型企业。此外,该模型还可以作为机器人研究的基础平台,促进机器人技术的进一步发展。未来,EveryDayVLA有望成为普及机器人技术的关键推动力。
📄 摘要(原文)
While Vision-Language-Action (VLA) models map visual inputs and language instructions directly to robot actions, they often rely on costly hardware and struggle in novel or cluttered scenes. We introduce EverydayVLA, a 6-DOF manipulator that can be assembled for under $300, capable of modest payloads and workspace. A single unified model jointly outputs discrete and continuous actions, and our adaptive-horizon ensemble monitors motion uncertainty to trigger on-the-fly re-planning for safe, reliable operation. On LIBERO, EverydayVLA matches state-of-the-art success rates, and in real-world tests it outperforms prior methods by 49% in-distribution and 34.9% out-of-distribution. By combining a state-of-the-art VLA with cost-effective hardware, EverydayVLA democratizes access to a robotic foundation model and paves the way for economical use in homes and research labs alike. Experiment videos and details: https://everydayvla.github.io/