MoE-DP: An MoE-Enhanced Diffusion Policy for Robust Long-Horizon Robotic Manipulation with Skill Decomposition and Failure Recovery
作者: Baiye Cheng, Tianhai Liang, Suning Huang, Maanping Shao, Feihong Zhang, Botian Xu, Zhengrong Xue, Huazhe Xu
分类: cs.RO
发布日期: 2025-11-07
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出MoE-DP,通过专家混合增强扩散策略,提升长时程机器人操作的鲁棒性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 扩散策略 专家混合 鲁棒性 长时程任务 技能分解 视觉运动控制
📋 核心要点
- 现有扩散策略在长时程机器人任务中,难以从子任务失败中恢复,且学习到的视觉表征缺乏可解释性。
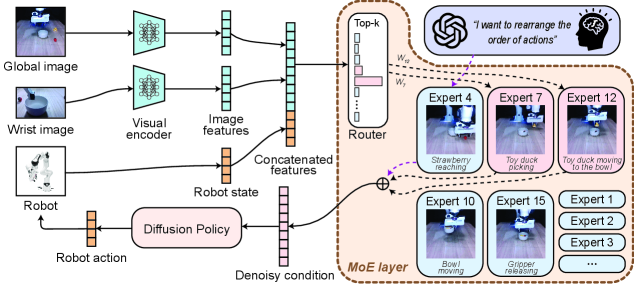
- MoE-DP在视觉编码器和扩散模型间引入专家混合层,将策略知识分解为多个专家,动态处理任务阶段。
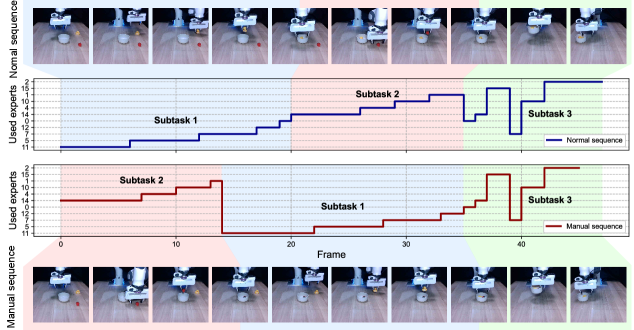
- 实验表明,MoE-DP在仿真和真实环境中均显著提升了长时程操作的鲁棒性,并学习到可解释的技能分解。
📝 摘要(中文)
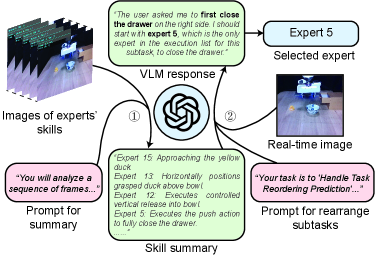
扩散策略在机器人视觉运动控制中表现出色,但对于长时程、多阶段任务中子任务失败的恢复能力不足,且学习到的观测表示难以解释。本文提出专家混合增强扩散策略(MoE-DP),核心思想是在视觉编码器和扩散模型之间插入一个专家混合(MoE)层。该层将策略的知识分解为一组专门的专家,动态激活以处理任务的不同阶段。大量实验表明,MoE-DP具有很强的抗干扰恢复能力,在鲁棒性方面显著优于标准基线。在6个长时程仿真任务中,在受干扰条件下,成功率平均相对提高了36%。这种增强的鲁棒性在真实世界中也得到了验证,MoE-DP也显示出显著的性能提升。此外,MoE-DP学习到可解释的技能分解,不同的专家对应于语义任务原语(例如,接近、抓取)。这种学习到的结构可用于推理时控制,允许重新排列子任务而无需任何重新训练。
🔬 方法详解
问题定义:论文旨在解决长时程机器人操作任务中,现有扩散策略鲁棒性不足的问题。具体而言,当机器人执行复杂任务时,如果某个子任务失败(例如,抓取失败),现有的扩散策略很难恢复并继续完成后续任务。此外,现有方法学习到的视觉表征通常是黑盒的,难以理解和解释。
核心思路:论文的核心思路是利用专家混合(MoE)层来增强扩散策略的鲁棒性和可解释性。MoE层可以将策略的知识分解为多个专门的专家,每个专家负责处理任务的不同阶段或子任务。通过动态激活不同的专家,策略可以更好地适应任务的变化,并从子任务失败中恢复。此外,学习到的专家可以对应于语义任务原语,从而提高策略的可解释性。
技术框架:MoE-DP的整体框架包括视觉编码器、MoE层和扩散模型。首先,视觉编码器将原始图像转换为潜在表示。然后,MoE层根据潜在表示动态激活不同的专家。每个专家都是一个小型神经网络,负责预测动作。最后,扩散模型根据激活的专家的输出生成最终的动作。在训练过程中,论文使用了一种混合损失函数,包括动作预测损失和专家激活损失。动作预测损失用于训练专家,专家激活损失用于鼓励专家学习不同的技能。
关键创新:MoE-DP的关键创新在于将专家混合层引入到扩散策略中。这种方法可以有效地提高策略的鲁棒性和可解释性。与传统的扩散策略相比,MoE-DP可以更好地适应任务的变化,并从子任务失败中恢复。此外,MoE-DP学习到的专家可以对应于语义任务原语,从而提高策略的可解释性。这种可解释性使得用户可以更容易地理解策略的行为,并进行调试和改进。
关键设计:MoE层包含多个专家,每个专家都是一个小型神经网络。论文使用了Gumbel-Softmax技巧来动态激活不同的专家。Gumbel-Softmax技巧可以使得专家激活过程可微,从而可以使用梯度下降法进行训练。此外,论文还使用了一种专家激活损失来鼓励专家学习不同的技能。专家激活损失的目标是使得每个专家在不同的状态下被激活。论文还探索了不同的专家数量和网络结构,最终选择了一个在性能和计算成本之间取得平衡的配置。
🖼️ 关键图片
📊 实验亮点
MoE-DP在6个长时程仿真任务中,在受干扰条件下,成功率平均相对提高了36%,显著优于标准基线。在真实世界实验中,MoE-DP也表现出显著的性能提升,验证了其鲁棒性。此外,MoE-DP学习到的专家对应于语义任务原语,例如接近、抓取,表明其具有可解释的技能分解能力。
🎯 应用场景
MoE-DP可应用于各种需要高鲁棒性和可解释性的机器人操作任务,例如:工业自动化、家庭服务机器人、医疗机器人等。通过学习可分解的技能,机器人可以更好地适应复杂环境,并从错误中恢复,从而提高工作效率和安全性。此外,该方法的可解释性有助于用户理解和调试机器人行为,促进人机协作。
📄 摘要(原文)
Diffusion policies have emerged as a powerful framework for robotic visuomotor control, yet they often lack the robustness to recover from subtask failures in long-horizon, multi-stage tasks and their learned representations of observations are often difficult to interpret. In this work, we propose the Mixture of Experts-Enhanced Diffusion Policy (MoE-DP), where the core idea is to insert a Mixture of Experts (MoE) layer between the visual encoder and the diffusion model. This layer decomposes the policy's knowledge into a set of specialized experts, which are dynamically activated to handle different phases of a task. We demonstrate through extensive experiments that MoE-DP exhibits a strong capability to recover from disturbances, significantly outperforming standard baselines in robustness. On a suite of 6 long-horizon simulation tasks, this leads to a 36% average relative improvement in success rate under disturbed conditions. This enhanced robustness is further validated in the real world, where MoE-DP also shows significant performance gains. We further show that MoE-DP learns an interpretable skill decomposition, where distinct experts correspond to semantic task primitives (e.g., approaching, grasping). This learned structure can be leveraged for inference-time control, allowing for the rearrangement of subtasks without any re-training.Our video and code are available at the https://moe-dp-website.github.io/MoE-DP-Website/.