End-to-End Dexterous Arm-Hand VLA Policies via Shared Autonomy: VR Teleoperation Augmented by Autonomous Hand VLA Policy for Efficient Data Collection
作者: Yu Cui, Yujian Zhang, Lina Tao, Yang Li, Xinyu Yi, Zhibin Li
分类: cs.RO, cs.AI
发布日期: 2025-10-31 (更新: 2025-12-13)
💡 一句话要点
提出基于共享自主的灵巧臂手VLA策略,用于高效数据收集。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 灵巧操作 共享自主 VR遥操作 视觉语言动作模型 机器人学习
📋 核心要点
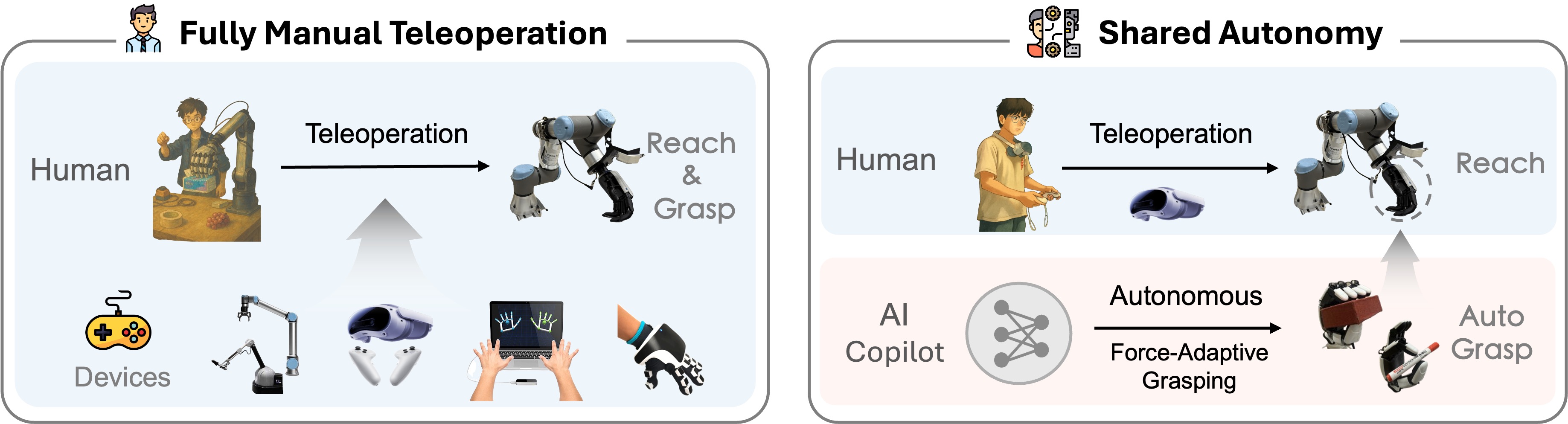
- 现有灵巧操作数据收集方法面临瓶颈,手动遥操作负担过重,自动规划动作不自然,限制了VLA模型的扩展性。
- 提出共享自主框架,结合VR遥操作的手臂宏观控制和自主DexGrasp-VLA策略的手部微观控制,降低认知负荷。
- 实验证明该框架能高效生成高质量臂手协同数据,训练的VLA策略在多样对象上达到90%的成功率。
📝 摘要(中文)
本文提出了一种共享自主框架,旨在解决通用机器人实现类人灵巧操作的难题。该框架利用视觉-语言-动作(VLA)模型从演示中学习技能,并通过共享自主策略克服高质量训练数据稀缺的限制。该方法将控制分为宏观和微观运动:人类操作员通过VR遥操作引导机器人手臂姿态,而自主的DexGrasp-VLA策略利用实时触觉和视觉反馈处理精细的手部控制。这种分工显著降低了认知负荷,并能够高效收集高质量的臂手协同演示数据。利用这些数据,训练了一个端到端的VLA策略,并使用新颖的臂手特征增强模块来捕获宏观和微观运动的不同和共享表示,从而实现更自然的协调。纠正性遥操作系统支持通过人机协作的失败恢复来实现策略的持续改进。实验表明,该框架以最少的人力生成高质量数据,并在各种对象(包括未见过的实例)上实现了90%的成功率。全面的评估验证了该系统在开发灵巧操作能力方面的有效性。
🔬 方法详解
问题定义:论文旨在解决通用机器人灵巧操作学习中高质量训练数据不足的问题。现有的数据收集方法,如纯手动遥操作,对操作员的认知负荷过高,难以长时间维持;而纯自动规划的方法,生成的动作往往不自然,缺乏人类操作的灵活性和适应性。
核心思路:论文的核心思路是采用共享自主的框架,将操作任务分解为宏观的手臂运动和微观的手部运动,分别由人类操作员和自主策略控制。人类操作员通过VR遥操作负责引导手臂的整体姿态,而自主策略则负责精细的手部动作,例如抓取和操作。这种分工可以有效降低人类操作员的认知负荷,同时利用自主策略的效率和一致性,从而高效地收集高质量的臂手协同操作数据。
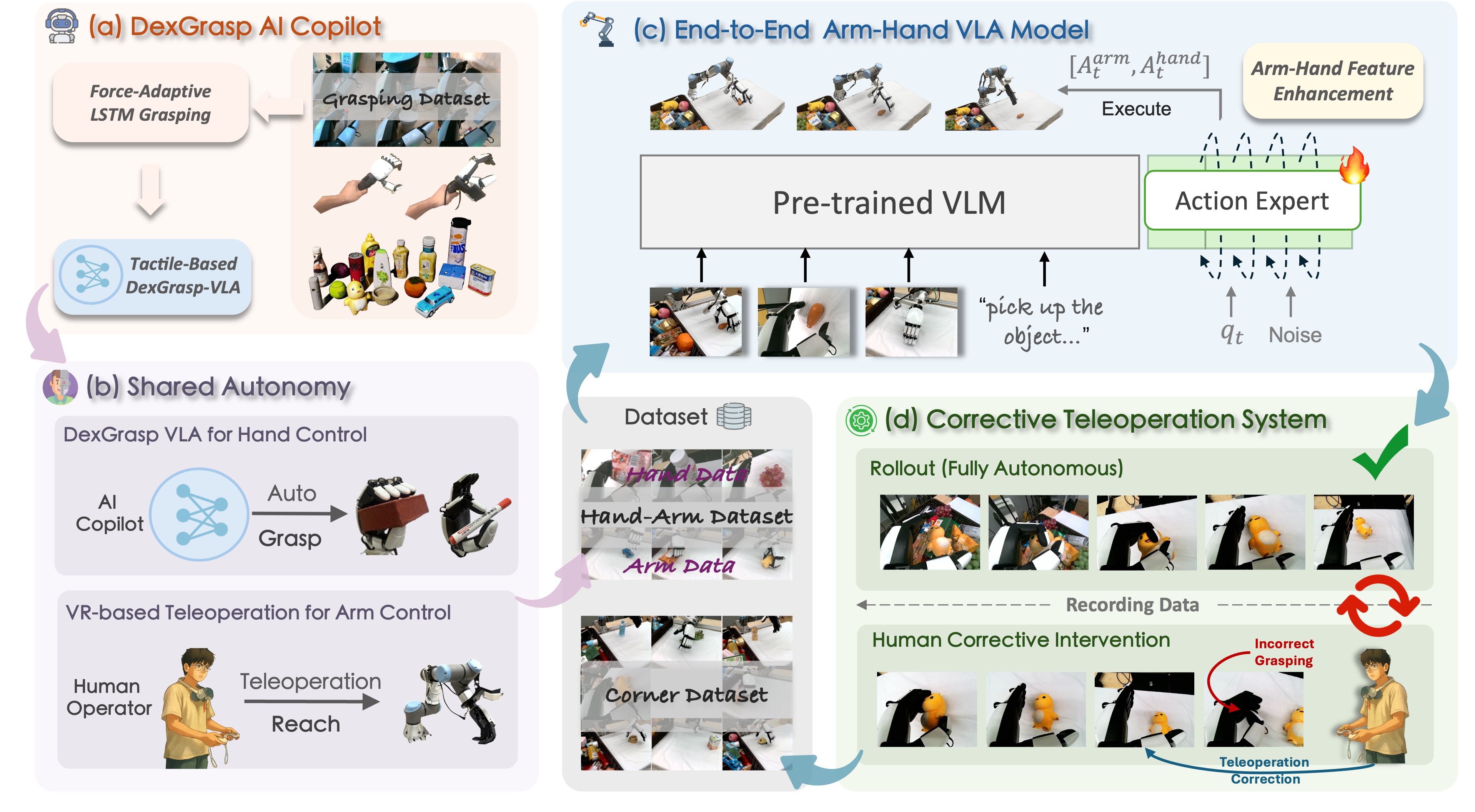
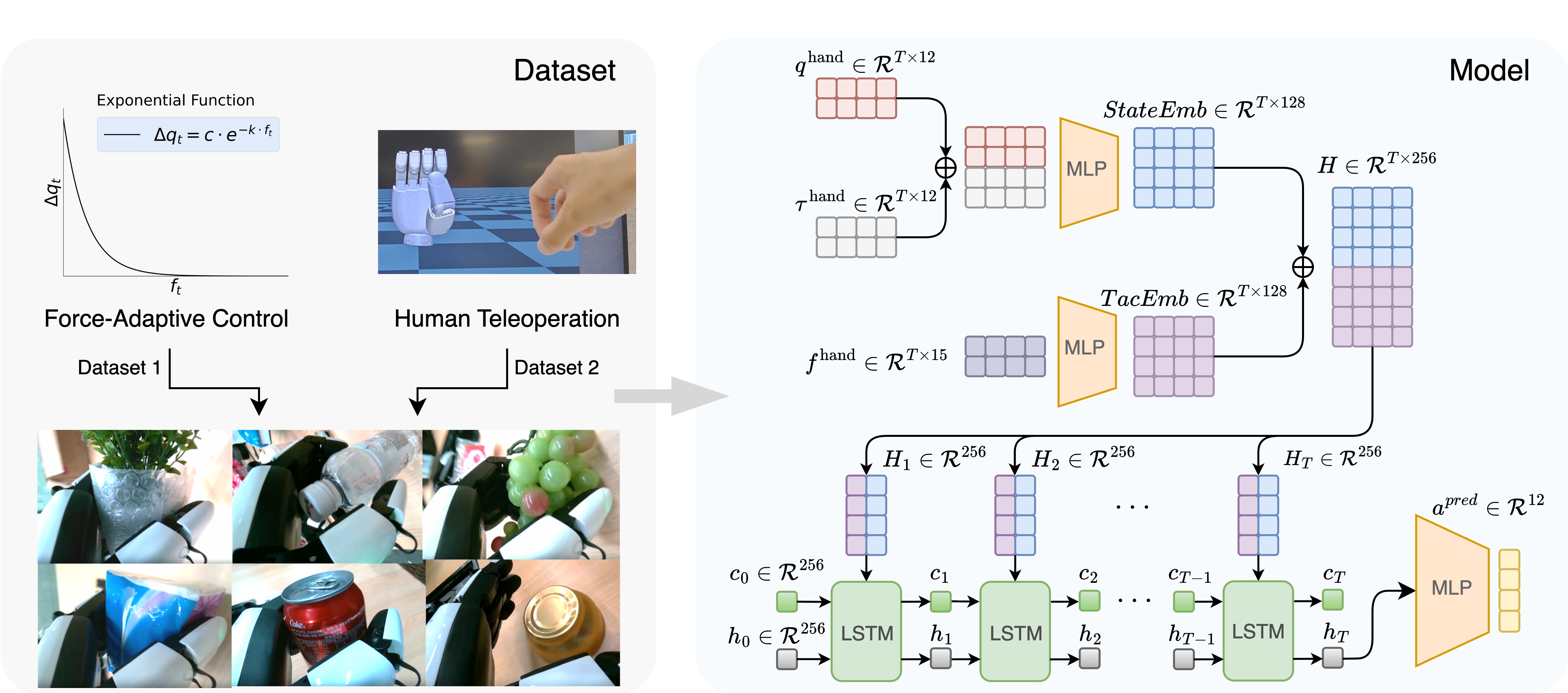
技术框架:整体框架包含三个主要部分:1) VR遥操作界面,用于人类操作员控制机器人的手臂姿态;2) 自主DexGrasp-VLA策略,负责根据视觉和触觉反馈控制机器人的手部动作;3) 臂手特征增强模块,用于融合手臂和手部的特征,提高VLA策略的性能。数据收集流程如下:人类操作员通过VR界面控制手臂移动到目标物体附近,然后自主DexGrasp-VLA策略接管手部控制,完成抓取和操作任务。如果操作失败,人类操作员可以通过纠正性遥操作进行干预,并重新启动自主策略。收集到的数据用于训练端到端的VLA策略。
关键创新:论文的关键创新在于共享自主框架和臂手特征增强模块。共享自主框架通过分工合作,实现了高效的数据收集和高质量的动作生成。臂手特征增强模块则通过捕获手臂和手部运动的不同和共享表示,提高了VLA策略的性能。此外,纠正性遥操作系统也允许持续的策略改进。
关键设计:DexGrasp-VLA策略的具体实现细节未知,但可以推测其可能包含视觉和触觉信息的编码器、语言指令的编码器以及动作解码器。臂手特征增强模块的具体网络结构也未知,但其目标是学习手臂和手部特征的联合表示。损失函数的设计可能包括模仿学习损失、强化学习损失以及其他辅助损失,以提高策略的泛化能力和鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该框架能够以最少的人力生成高质量的臂手协同数据,并且训练得到的VLA策略在各种对象(包括未见过的实例)上实现了90%的成功率。这表明该方法在数据效率和策略泛化能力方面具有显著优势。具体的性能提升数据和对比基线信息未知。
🎯 应用场景
该研究成果可应用于各种需要灵巧操作的机器人任务,例如:工业自动化中的装配、医疗手术中的辅助操作、家庭服务中的物品整理等。通过高效的数据收集和策略学习,可以降低机器人部署的成本和难度,使其能够更好地适应复杂和动态的环境,从而提升机器人的实用性和智能化水平。
📄 摘要(原文)
Achieving human-like dexterous manipulation remains a major challenge for general-purpose robots. While Vision-Language-Action (VLA) models show potential in learning skills from demonstrations, their scalability is limited by scarce high-quality training data. Existing data collection methods face inherent constraints: manual teleoperation overloads human operators, while automated planning often produces unnatural motions. We propose a Shared Autonomy framework that divides control between macro and micro motions. A human operator guides the robot's arm pose through intuitive VR teleoperation, while an autonomous DexGrasp-VLA policy handles fine-grained hand control using real-time tactile and visual feedback. This division significantly reduces cognitive load and enables efficient collection of high-quality coordinated arm-hand demonstrations. Using this data, we train an end-to-end VLA policy enhanced with our novel Arm-Hand Feature Enhancement module, which captures both distinct and shared representations of macro and micro movements for more natural coordination. Our Corrective Teleoperation system enables continuous policy improvement through human-in-the-loop failure recovery. Experiments demonstrate that our framework generates high-quality data with minimal manpower and achieves a 90% success rate across diverse objects, including unseen instances. Comprehensive evaluations validate the system's effectiveness in developing dexterous manipulation capabilities.