Towards a Multi-Embodied Grasping Agent
作者: Roman Freiberg, Alexander Qualmann, Ngo Anh Vien, Gerhard Neumann
分类: cs.RO
发布日期: 2025-10-31 (更新: 2025-12-19)
备注: 8 pages, 3 figures
💡 一句话要点
提出一种数据高效的、基于流的、等变抓取合成架构,用于多具身抓取任务。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 多具身抓取 等变神经网络 基于流的模型 抓取合成 机器人抓取
📋 核心要点
- 现有抓取方法难以处理不同夹爪设计,且依赖大规模数据,限制了其通用性和实用性。
- 论文提出一种基于流的等变抓取架构,仅依赖几何信息,高效学习不同夹爪的抓取策略。
- 该方法在包含多种夹爪和场景的数据集上验证,实现了更平滑的学习和更快的推理速度。
📝 摘要(中文)
本文提出了一种面向多具身抓取的通用方法,旨在开发能够适应不同夹爪设计的通用抓取策略。现有方法通常隐式地学习机器人的运动学结构,并且面临大规模数据难以获取的挑战。本文提出了一种数据高效的、基于流的、等变抓取合成架构,该架构能够处理具有不同自由度的各种夹爪类型,并成功利用潜在的运动学模型,仅从夹爪和场景几何信息中推导出所有必要的信息。与以往的等变抓取方法不同,我们将所有模块从头开始移植到JAX,并提供了一个具有场景、夹爪和抓取批处理能力的模型,从而实现更平滑的学习、更高的性能和更快的推理速度。我们的数据集包含从类人手到平行偏航夹爪等多种夹爪,包括25,000个场景和2000万个抓取。
🔬 方法详解
问题定义:现有方法在多具身抓取任务中,难以泛化到不同的夹爪设计。它们通常需要大量的训练数据来学习每个夹爪的运动学结构,这使得它们在数据稀缺的情况下表现不佳。此外,隐式地学习运动学结构也限制了模型的解释性和可控性。
核心思路:本文的核心思路是利用等变神经网络来显式地建模抓取任务中的几何关系,并结合基于流的模型来生成抓取姿态。通过这种方式,模型可以仅从夹爪和场景的几何信息中推导出抓取姿态,而无需依赖大量的训练数据。此外,等变性保证了模型对于输入几何变换的鲁棒性。
技术框架:该架构包含以下主要模块:1) 特征提取模块,用于提取夹爪和场景的几何特征;2) 等变图神经网络,用于建模夹爪和场景之间的关系;3) 基于流的抓取姿态生成器,用于生成抓取姿态。整个流程是,首先将夹爪和场景的几何信息输入到特征提取模块中,然后使用等变图神经网络来建模它们之间的关系,最后使用基于流的抓取姿态生成器来生成抓取姿态。
关键创新:最重要的技术创新点在于将等变神经网络和基于流的模型结合起来,用于抓取姿态的生成。与以往的等变抓取方法不同,该方法从头开始使用JAX实现,并支持场景、夹爪和抓取的批处理,从而提高了学习效率和推理速度。
关键设计:该模型使用等变卷积神经网络来提取夹爪和场景的几何特征。等变图神经网络使用消息传递机制来建模夹爪和场景之间的关系。基于流的抓取姿态生成器使用RealNVP架构来实现。损失函数包括抓取质量损失和抓取姿态损失。模型使用Adam优化器进行训练。
🖼️ 关键图片
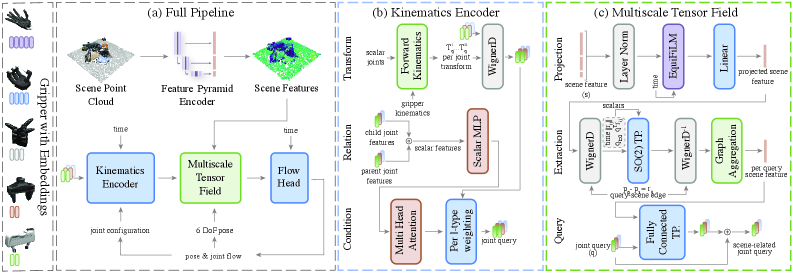

📊 实验亮点
该方法在包含多种夹爪和场景的数据集上进行了评估,结果表明该方法能够有效地生成高质量的抓取姿态。与现有的方法相比,该方法在数据效率、抓取成功率和推理速度方面都有显著的提升。具体性能数据未知,但论文强调了更平滑的学习和更快的推理速度。
🎯 应用场景
该研究成果可应用于机器人自动化、智能制造、家庭服务等领域。例如,机器人可以利用该方法自动适应不同的夹爪,从而完成各种复杂的抓取任务。在智能制造中,该方法可以用于自动化装配和物料搬运。在家庭服务中,机器人可以利用该方法帮助人们完成各种家务。
📄 摘要(原文)
Multi-embodiment grasping focuses on developing approaches that exhibit generalist behavior across diverse gripper designs. Existing methods often learn the kinematic structure of the robot implicitly and face challenges due to the difficulty of sourcing the required large-scale data. In this work, we present a data-efficient, flow-based, equivariant grasp synthesis architecture that can handle different gripper types with variable degrees of freedom and successfully exploit the underlying kinematic model, deducing all necessary information solely from the gripper and scene geometry. Unlike previous equivariant grasping methods, we translated all modules from the ground up to JAX and provide a model with batching capabilities over scenes, grippers, and grasps, resulting in smoother learning, improved performance and faster inference time. Our dataset encompasses grippers ranging from humanoid hands to parallel yaw grippers and includes 25,000 scenes and 20 million grasps.