Learning Generalizable Visuomotor Policy through Dynamics-Alignment
作者: Dohyeok Lee, Jung Min Lee, Munkyung Kim, Seokhun Ju, Jin Woo Koo, Kyungjae Lee, Dohyeong Kim, TaeHyun Cho, Jungwoo Lee
分类: cs.RO, cs.LG
发布日期: 2025-10-31
备注: 9 pages, 6 figures
💡 一句话要点
提出动力学对齐的Flow Matching策略,提升机器人视觉伺服策略的泛化性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 机器人学习 视觉伺服 行为克隆 动力学预测 泛化能力
📋 核心要点
- 现有行为克隆方法泛化性差,视频预测模型虽有进展,但动作无关动力学限制了其在精确操作任务中的应用。
- DAP方法的核心在于策略和动力学模型在动作生成过程中相互提供纠正反馈,实现自我纠正,提升泛化能力。
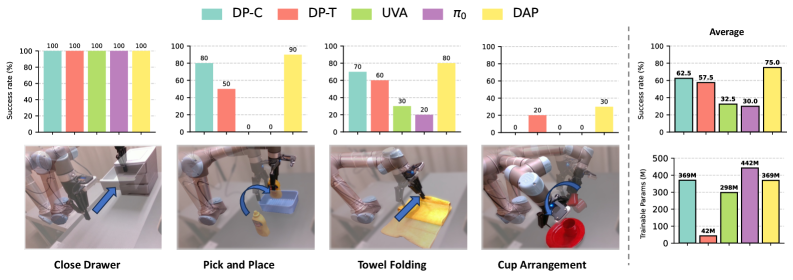
- 实验表明,DAP方法在真实机器人操作任务中,尤其是在OOD场景下,泛化性能优于其他基线方法。
📝 摘要(中文)
基于行为克隆的机器人学习方法由于专家演示数据覆盖范围有限,泛化能力较差。最近,利用视频预测模型的方法通过从大规模数据集中学习丰富的时空表示,展现了良好的前景。然而,这些模型学习到的动作无关动力学无法区分不同的控制输入,限制了其在精确操作任务中的应用,并且需要大量的预训练数据集。我们提出了一种动力学对齐的Flow Matching策略(DAP),将动力学预测集成到策略学习中。我们的方法引入了一种新颖的架构,其中策略和动力学模型在动作生成过程中提供相互纠正的反馈,从而实现自我纠正和改进的泛化能力。经验验证表明,在真实机器人操作任务中,该方法具有优于基线方法的泛化性能,尤其是在包括视觉干扰和光照变化等OOD场景中表现出强大的鲁棒性。
🔬 方法详解
问题定义:现有基于行为克隆的机器人学习方法,由于依赖有限的专家演示数据,在面对未见过的新场景时,泛化能力不足。虽然利用视频预测模型学习时空表示有所进展,但这些模型学习到的动力学是动作无关的,无法区分不同的控制输入,导致难以应用于需要精确控制的操作任务。此外,这些方法通常需要大规模的预训练数据集。
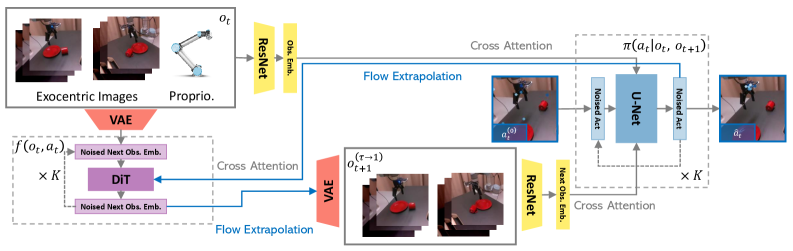
核心思路:DAP的核心思路是将动力学预测与策略学习紧密结合,通过策略模型和动力学模型之间的相互反馈,实现动作的自我纠正。策略模型负责生成动作,动力学模型预测该动作产生的状态变化,然后策略模型根据动力学模型的预测结果进行调整,从而提高动作的准确性和泛化能力。这种相互纠正的机制使得模型能够更好地适应未知的环境和任务。
技术框架:DAP包含策略模型和动力学模型两个主要模块。策略模型接收当前状态作为输入,输出动作。动力学模型接收当前状态和动作作为输入,预测下一个状态。策略模型和动力学模型之间通过Flow Matching机制进行连接,策略模型生成的动作会影响动力学模型的预测,而动力学模型的预测结果又会反过来影响策略模型的动作生成。整个框架通过端到端的方式进行训练,策略模型和动力学模型共同优化。
关键创新:DAP的关键创新在于将动力学预测与策略学习进行深度融合,通过策略模型和动力学模型之间的相互反馈,实现动作的自我纠正。这种方法不同于以往的动作无关动力学学习,能够更好地捕捉动作与状态变化之间的关系,从而提高策略的泛化能力。此外,DAP采用Flow Matching机制,使得策略模型和动力学模型能够有效地进行信息交互。
关键设计:DAP使用Flow Matching作为策略和动力学模型之间信息传递的桥梁。具体来说,策略模型输出的动作被视为动力学模型预测状态变化的一个条件。动力学模型预测的状态变化与实际状态变化之间的差异被用来指导策略模型的优化。损失函数包括策略损失和动力学损失两部分,策略损失鼓励策略模型生成能够实现期望状态变化的动作,动力学损失鼓励动力学模型准确预测状态变化。网络结构方面,策略模型和动力学模型可以采用各种常见的神经网络结构,如卷积神经网络、循环神经网络等。
🖼️ 关键图片
📊 实验亮点
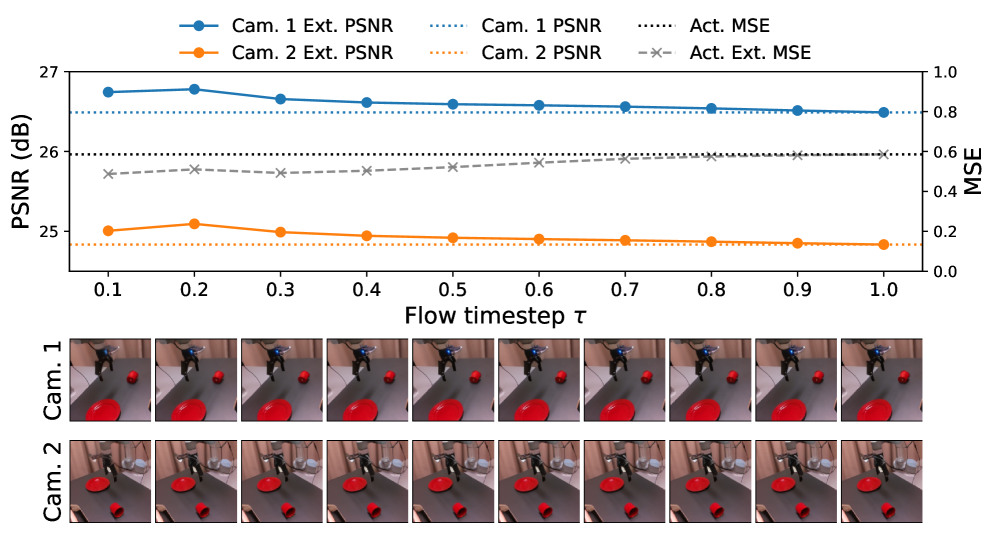
实验结果表明,DAP方法在真实机器人操作任务中,泛化性能优于其他基线方法。尤其是在视觉干扰(如遮挡、噪声)和光照变化等OOD场景下,DAP方法表现出更强的鲁棒性。具体性能数据在论文中给出,相较于传统方法有显著提升。
🎯 应用场景
该研究成果可应用于各种需要高精度和强泛化能力的机器人操作任务,例如工业自动化、医疗手术、家庭服务等。通过学习动力学对齐的策略,机器人能够更好地适应不同的环境和任务,提高操作的效率和安全性。此外,该方法还可以扩展到其他领域,如自动驾驶、游戏AI等。
📄 摘要(原文)
Behavior cloning methods for robot learning suffer from poor generalization due to limited data support beyond expert demonstrations. Recent approaches leveraging video prediction models have shown promising results by learning rich spatiotemporal representations from large-scale datasets. However, these models learn action-agnostic dynamics that cannot distinguish between different control inputs, limiting their utility for precise manipulation tasks and requiring large pretraining datasets. We propose a Dynamics-Aligned Flow Matching Policy (DAP) that integrates dynamics prediction into policy learning. Our method introduces a novel architecture where policy and dynamics models provide mutual corrective feedback during action generation, enabling self-correction and improved generalization. Empirical validation demonstrates generalization performance superior to baseline methods on real-world robotic manipulation tasks, showing particular robustness in OOD scenarios including visual distractions and lighting variations.