Real-DRL: Teach and Learn in Reality
作者: Yanbing Mao, Yihao Cai, Lui Sha
分类: cs.RO, cs.AI
发布日期: 2025-10-30
备注: 37 pages
💡 一句话要点
Real-DRL框架:在真实系统中实现安全自主学习的深度强化学习
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 安全自主系统 Sim2Real 机器人控制 物理模型 教学式学习 运行时学习 安全关键系统
📋 核心要点
- 现有DRL方法在安全关键系统中难以直接应用,主要挑战在于Sim2Real差距和对未知风险的应对能力。
- Real-DRL框架通过引入PHY-Teacher进行安全指导和实时干预,结合Trigger机制协调学习过程,保障系统安全性。
- 实验表明,Real-DRL在真实四足机器人和仿真环境中均表现出良好的安全性和性能,验证了其有效性。
📝 摘要(中文)
本文提出了一种名为Real-DRL的框架,用于安全攸关的自主系统。该框架支持深度强化学习(DRL)智能体在真实环境中进行运行时学习,从而开发出安全且高性能的动作策略,并将安全性置于首位。Real-DRL包含三个交互组件:DRL-Student、PHY-Teacher和Trigger。DRL-Student是一个DRL智能体,它在双重自学习和教学式学习范式以及实时安全信息批采样方面进行了创新。PHY-Teacher是一种基于物理模型的动作策略设计,专注于安全关键功能,并实时修补以支持DRL-Student的教学式学习和真实系统的安全。Trigger管理DRL-Student和PHY-Teacher之间的交互。Real-DRL能够有效应对未知风险和Sim2Real差距带来的安全挑战,并具有安全性保证、自动分层学习(安全优先,然后是高性能学习)以及安全信息批采样等特点,以解决由极端情况引起的学习经验不平衡问题。在真实四足机器人、NVIDIA Isaac Gym中的四足机器人和倒立摆系统上的实验,以及对比和消融研究,证明了Real-DRL的有效性和独特功能。
🔬 方法详解
问题定义:现有深度强化学习方法在安全关键的自主系统中应用时,面临着Sim2Real差距带来的挑战,即在仿真环境中训练的策略难以直接迁移到真实物理系统中。此外,真实系统运行过程中可能出现未知的风险,导致智能体做出不安全的行为。因此,如何在真实系统中安全地训练DRL智能体,使其能够学习到安全且高性能的动作策略,是一个亟待解决的问题。
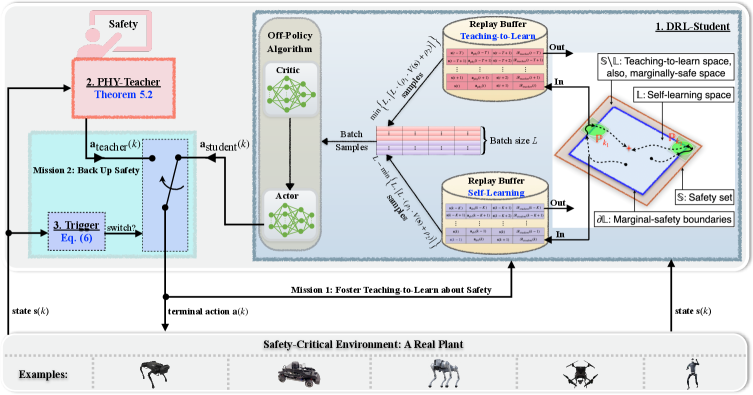
核心思路:Real-DRL的核心思路是引入一个基于物理模型的“教师”(PHY-Teacher),该教师专注于安全关键功能,并能够实时地对DRL智能体(DRL-Student)进行指导和干预。通过这种“教学式学习”范式,DRL-Student可以在保证安全的前提下,逐步学习到高性能的动作策略。同时,一个“触发器”(Trigger)负责管理DRL-Student和PHY-Teacher之间的交互,确保在必要时启动安全干预。
技术框架:Real-DRL框架包含三个主要组件:DRL-Student、PHY-Teacher和Trigger。DRL-Student是一个标准的DRL智能体,负责探索和学习动作策略。PHY-Teacher是一个基于物理模型的安全策略,负责在DRL-Student的行为可能导致不安全状态时进行干预。Trigger负责监控DRL-Student的状态,并在必要时激活PHY-Teacher。整个学习过程可以看作是DRL-Student在PHY-Teacher的指导下,逐步学习并改进其动作策略的过程。
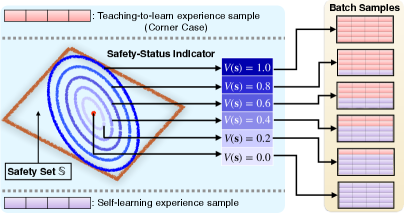
关键创新:Real-DRL的关键创新在于引入了PHY-Teacher进行安全指导和实时干预。与传统的DRL方法相比,Real-DRL能够更好地应对Sim2Real差距和未知风险,从而在真实系统中实现安全自主学习。此外,Real-DRL还采用了安全信息批采样技术,以解决由极端情况引起的学习经验不平衡问题。
关键设计:PHY-Teacher的设计基于物理模型,其目标是确保系统的安全性。具体的实现方式取决于具体的应用场景。例如,在四足机器人控制中,PHY-Teacher可以设计为一种简单的步态控制策略,确保机器人不会摔倒。Trigger的设计也需要根据具体的应用场景进行调整。例如,可以设置一些安全阈值,当DRL-Student的状态超过这些阈值时,Trigger就会激活PHY-Teacher。
🖼️ 关键图片
📊 实验亮点
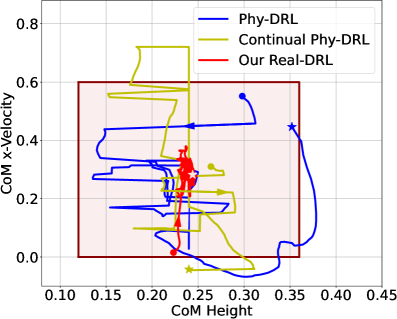
实验结果表明,Real-DRL在真实四足机器人和NVIDIA Isaac Gym仿真环境中均表现出良好的安全性和性能。与传统的DRL方法相比,Real-DRL能够更好地应对Sim2Real差距和未知风险,从而在真实系统中实现安全自主学习。消融研究也验证了PHY-Teacher和安全信息批采样技术对Real-DRL性能的贡献。
🎯 应用场景
Real-DRL框架具有广泛的应用前景,尤其是在安全攸关的自主系统中,例如自动驾驶、机器人控制、航空航天等领域。该框架可以帮助这些系统在真实环境中安全地学习和改进其行为策略,从而提高其性能和可靠性。未来,Real-DRL可以进一步扩展到更复杂的系统和任务中,例如多智能体协作、人机交互等。
📄 摘要(原文)
This paper introduces the Real-DRL framework for safety-critical autonomous systems, enabling runtime learning of a deep reinforcement learning (DRL) agent to develop safe and high-performance action policies in real plants (i.e., real physical systems to be controlled), while prioritizing safety! The Real-DRL consists of three interactive components: a DRL-Student, a PHY-Teacher, and a Trigger. The DRL-Student is a DRL agent that innovates in the dual self-learning and teaching-to-learn paradigm and the real-time safety-informed batch sampling. On the other hand, PHY-Teacher is a physics-model-based design of action policies that focuses solely on safety-critical functions. PHY-Teacher is novel in its real-time patch for two key missions: i) fostering the teaching-to-learn paradigm for DRL-Student and ii) backing up the safety of real plants. The Trigger manages the interaction between the DRL-Student and the PHY-Teacher. Powered by the three interactive components, the Real-DRL can effectively address safety challenges that arise from the unknown unknowns and the Sim2Real gap. Additionally, Real-DRL notably features i) assured safety, ii) automatic hierarchy learning (i.e., safety-first learning and then high-performance learning), and iii) safety-informed batch sampling to address the learning experience imbalance caused by corner cases. Experiments with a real quadruped robot, a quadruped robot in NVIDIA Isaac Gym, and a cart-pole system, along with comparisons and ablation studies, demonstrate the Real-DRL's effectiveness and unique features.