Alpamayo-R1: Bridging Reasoning and Action Prediction for Generalizable Autonomous Driving in the Long Tail
作者: NVIDIA, :, Yan Wang, Wenjie Luo, Junjie Bai, Yulong Cao, Tong Che, Ke Chen, Yuxiao Chen, Jenna Diamond, Yifan Ding, Wenhao Ding, Liang Feng, Greg Heinrich, Jack Huang, Peter Karkus, Boyi Li, Pinyi Li, Tsung-Yi Lin, Dongran Liu, Ming-Yu Liu, Langechuan Liu, Zhijian Liu, Jason Lu, Yunxiang Mao, Pavlo Molchanov, Lindsey Pavao, Zhenghao Peng, Mike Ranzinger, Ed Schmerling, Shida Shen, Yunfei Shi, Sarah Tariq, Ran Tian, Tilman Wekel, Xinshuo Weng, Tianjun Xiao, Eric Yang, Xiaodong Yang, Yurong You, Xiaohui Zeng, Wenyuan Zhang, Boris Ivanovic, Marco Pavone
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-30 (更新: 2026-01-07)
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
Alpamayo-R1:融合因果推理与轨迹预测,提升长尾场景下自动驾驶泛化性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 因果推理 视觉语言模型 强化学习 轨迹规划 长尾场景 决策智能
📋 核心要点
- 现有端到端自动驾驶方法在长尾场景中泛化性不足,缺乏因果理解和稀疏监督。
- Alpamayo-R1融合因果推理与轨迹规划,构建视觉-语言-动作模型,提升复杂场景决策能力。
- 实验表明,AR1在规划精度和安全性方面显著提升,并在真实道路测试中验证了实时性能。
📝 摘要(中文)
本文提出Alpamayo-R1 (AR1),一种视觉-语言-动作模型(VLA),它将因果链推理与轨迹规划相结合,用于解决复杂驾驶场景。该方法包含三个关键创新:(1) 通过混合自动标注和人工参与流程构建的因果链(CoC)数据集,该数据集包含决策依据和因果关联的推理轨迹,并与驾驶行为对齐;(2) 一个模块化的VLA架构,结合了为物理AI预训练的视觉-语言模型Cosmos-Reason,以及一个基于扩散的轨迹解码器,该解码器可以实时生成动态可行的轨迹;(3) 一个多阶段训练策略,使用监督微调来激发推理能力,并使用强化学习(RL)来加强推理-动作一致性并优化推理质量。在具有挑战性的案例中,AR1的规划准确率比仅使用轨迹的基线提高了12%,在闭环仿真中,近距离接触率降低了35%。强化学习后训练使推理质量提高了45%,推理-动作一致性提高了37%。模型规模从0.5B扩展到7B参数显示出持续的改进。车载道路测试证实了实时性能(99毫秒延迟)和成功的城市部署。通过将可解释的推理与精确控制相结合,AR1展示了一条通往L4级自动驾驶的实用路径。模型权重和推理代码已开源。
🔬 方法详解
问题定义:自动驾驶系统在长尾场景下,由于数据稀疏和缺乏对场景的因果理解,导致泛化能力差,容易出现安全问题。现有端到端方法难以处理这些复杂和罕见的驾驶情况,需要更强的推理能力和更有效的数据利用方式。
核心思路:通过引入因果推理,使自动驾驶系统能够理解场景中的因果关系,从而做出更合理的决策。同时,利用视觉-语言模型提取场景信息,并结合强化学习来优化推理过程,确保推理与行动的一致性。这种方法旨在提高系统在复杂和长尾场景下的泛化能力和安全性。
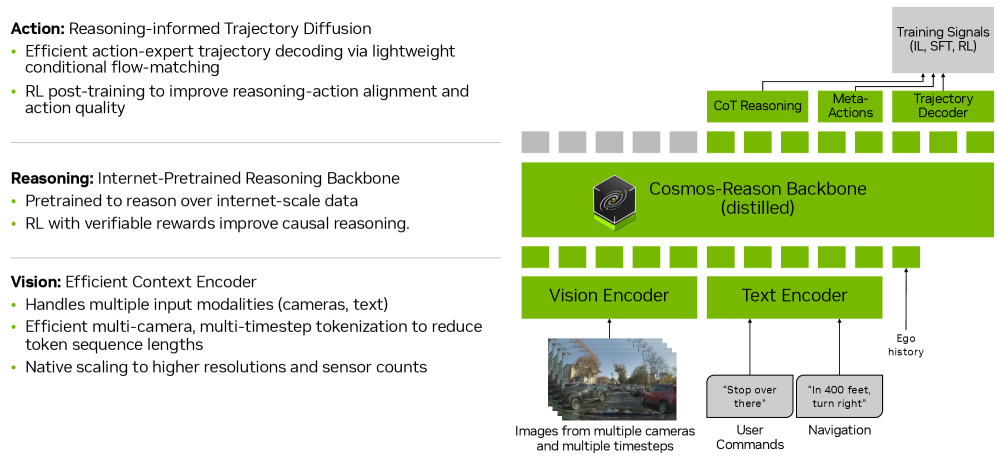
技术框架:Alpamayo-R1 (AR1) 包含三个主要模块:(1) 因果链 (CoC) 数据集,用于训练模型的推理能力;(2) 模块化的视觉-语言-动作 (VLA) 架构,由 Cosmos-Reason (视觉-语言模型) 和扩散轨迹解码器组成;(3) 多阶段训练策略,包括监督微调和强化学习。Cosmos-Reason负责提取视觉和语言特征,扩散轨迹解码器生成可行的轨迹,多阶段训练策略用于优化推理和行动的一致性。
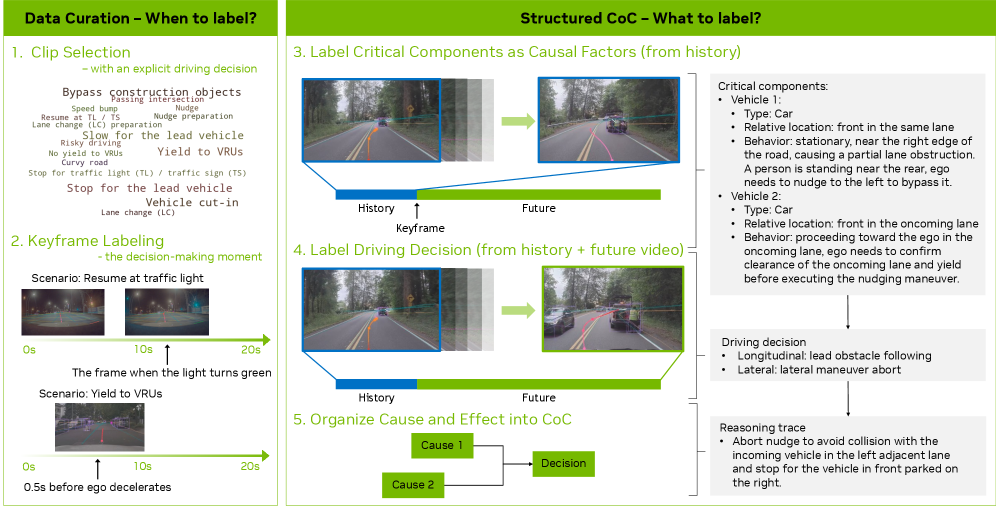
关键创新:该方法的核心创新在于将因果推理与轨迹规划相结合,并提出了一个用于训练因果推理的CoC数据集。与传统的端到端方法相比,AR1能够显式地进行推理,并利用强化学习来优化推理过程,从而提高系统的泛化能力和安全性。CoC数据集的构建方式也较为新颖,采用了混合自动标注和人工参与的流程。
关键设计:CoC数据集包含决策依据和因果关联的推理轨迹,并与驾驶行为对齐。Cosmos-Reason模型是为物理AI预训练的视觉-语言模型,能够提取丰富的场景信息。扩散轨迹解码器基于扩散模型,可以生成动态可行的轨迹。多阶段训练策略包括:首先使用监督微调来训练模型的推理能力,然后使用强化学习来优化推理-动作一致性,并提高推理质量。具体参数设置和损失函数细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
AR1在具有挑战性的案例中,规划准确率比仅使用轨迹的基线提高了12%,在闭环仿真中,近距离接触率降低了35%。强化学习后训练使推理质量提高了45%,推理-动作一致性提高了37%。模型规模从0.5B扩展到7B参数显示出持续的改进。车载道路测试证实了实时性能(99毫秒延迟)和成功的城市部署。
🎯 应用场景
该研究成果可应用于L4及以上级别的自动驾驶系统,尤其是在城市复杂交通环境和长尾场景下。通过提升自动驾驶系统的推理能力和安全性,可以减少交通事故,提高交通效率,并为无人配送、自动泊车等应用提供更可靠的技术支持。未来,该技术有望进一步推广到其他机器人领域,例如服务机器人和工业机器人。
📄 摘要(原文)
End-to-end architectures trained via imitation learning have advanced autonomous driving by scaling model size and data, yet performance remains brittle in safety-critical long-tail scenarios where supervision is sparse and causal understanding is limited. We introduce Alpamayo-R1 (AR1), a vision-language-action model (VLA) that integrates Chain of Causation reasoning with trajectory planning for complex driving scenarios. Our approach features three key innovations: (1) the Chain of Causation (CoC) dataset, built through a hybrid auto-labeling and human-in-the-loop pipeline producing decision-grounded, causally linked reasoning traces aligned with driving behaviors; (2) a modular VLA architecture combining Cosmos-Reason, a vision-language model pre-trained for Physical AI, with a diffusion-based trajectory decoder that generates dynamically feasible trajectories in real time; (3) a multi-stage training strategy using supervised fine-tuning to elicit reasoning and reinforcement learning (RL) to enforce reasoning-action consistency and optimize reasoning quality. AR1 achieves up to a 12% improvement in planning accuracy on challenging cases compared to a trajectory-only baseline, with a 35% reduction in close encounter rate in closed-loop simulation. RL post-training improves reasoning quality by 45% and reasoning-action consistency by 37%. Model scaling from 0.5B to 7B parameters shows consistent improvements. On-vehicle road tests confirm real-time performance (99 ms latency) and successful urban deployment. By bridging interpretable reasoning with precise control, AR1 demonstrates a practical path towards Level 4 autonomous driving. Model weights are available at https://huggingface.co/nvidia/Alpamayo-R1-10B with inference code at https://github.com/NVlabs/alpamayo.