A Multi-Modal Neuro-Symbolic Approach for Spatial Reasoning-Based Visual Grounding in Robotics
作者: Simindokht Jahangard, Mehrzad Mohammadi, Abhinav Dhall, Hamid Rezatofighi
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-10-30
💡 一句话要点
提出一种多模态神经符号方法,用于机器人中基于空间推理的视觉定位
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位 空间推理 神经符号方法 多模态融合 机器人 场景图 全景图像 3D点云
📋 核心要点
- 现有视觉语言模型在空间推理方面存在不足,主要原因是其隐式推理方式和对图像的过度依赖。
- 论文提出一种神经符号框架,融合全景图像和3D点云,显式建模空间和逻辑关系,提升推理能力。
- 实验表明,该方法在拥挤环境中表现出优越的性能和可靠性,且保持轻量级设计,适合机器人应用。
📝 摘要(中文)
视觉推理,特别是空间推理,是一项具有挑战性的认知任务,它需要理解物体关系及其在复杂环境中的交互,尤其是在机器人领域。现有的视觉语言模型(VLMs)擅长感知任务,但由于其隐式的、相关性驱动的推理以及仅仅依赖于图像,因此在细粒度的空间推理方面表现不佳。我们提出了一种新颖的神经符号框架,该框架集成了全景图像和3D点云信息,结合神经感知与符号推理,以显式地建模空间和逻辑关系。我们的框架包括一个用于检测实体和提取属性的感知模块,以及一个构建结构化场景图以支持精确、可解释查询的推理模块。在JRDB-Reasoning数据集上的评估表明,我们的方法在拥挤的人工环境中表现出卓越的性能和可靠性,同时保持了适用于机器人和具身人工智能应用的轻量级设计。
🔬 方法详解
问题定义:论文旨在解决机器人领域中视觉定位任务对细粒度空间推理的挑战。现有视觉语言模型虽然在感知任务上表现良好,但由于其隐式推理和对图像的单一依赖,难以处理复杂的空间关系,尤其是在拥挤和复杂环境中,定位精度和可靠性受到限制。
核心思路:论文的核心思路是将神经感知与符号推理相结合,利用神经感知模块提取视觉信息,然后通过符号推理模块显式地建模和推理空间关系。这种结合方式旨在克服传统视觉语言模型的局限性,提高空间推理的准确性和可解释性。
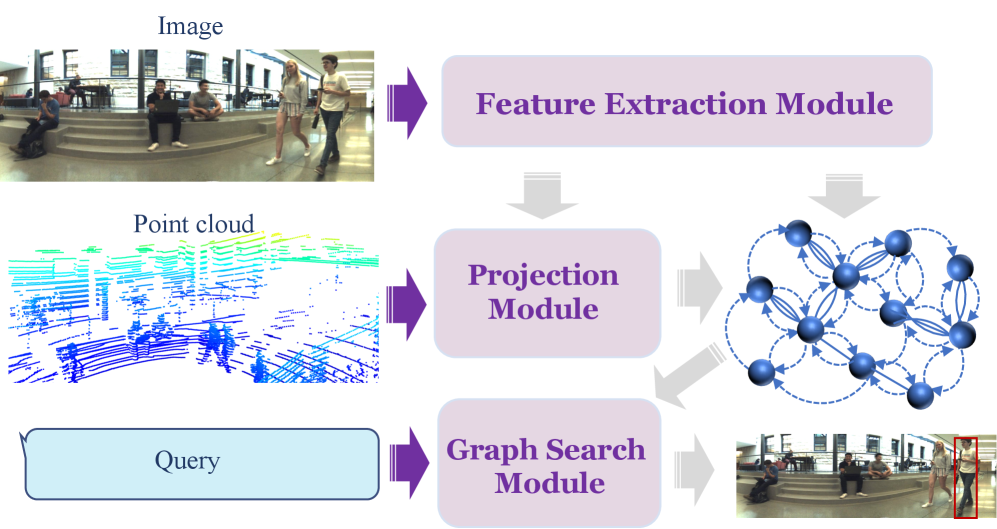
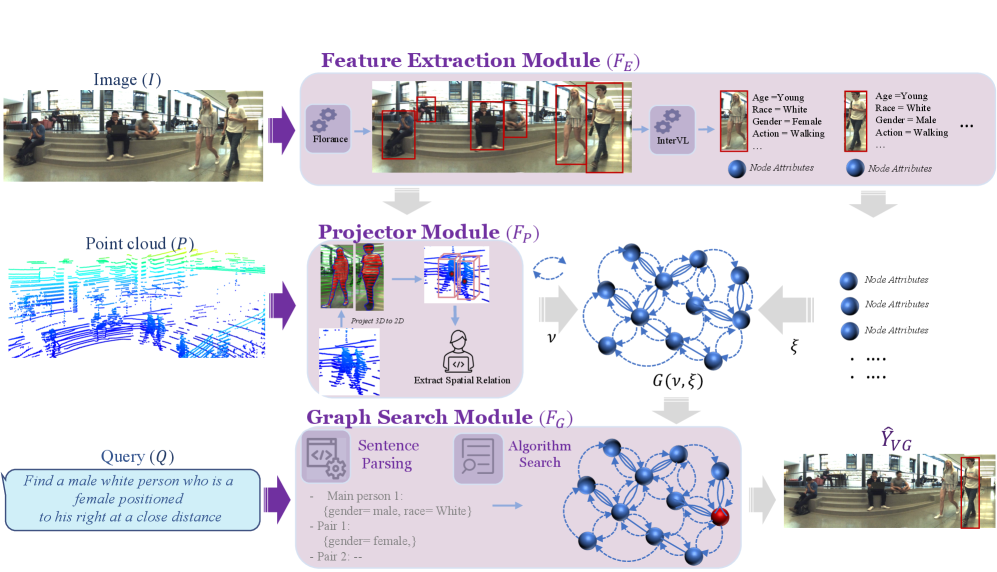
技术框架:该框架包含两个主要模块:感知模块和推理模块。感知模块负责从全景图像和3D点云中检测实体(例如物体和人)并提取它们的属性(例如位置、大小、类别)。推理模块则利用感知模块的输出,构建一个结构化的场景图,其中节点表示实体,边表示实体之间的空间和逻辑关系。用户可以通过查询场景图来执行空间推理任务,例如“找到在桌子上的红色物体”。
关键创新:该方法最重要的创新点在于将神经感知与符号推理显式地结合起来。与传统的端到端视觉语言模型不同,该方法通过构建场景图来显式地表示和推理空间关系,从而提高了推理的可解释性和准确性。此外,该方法同时利用全景图像和3D点云信息,从而能够更全面地理解场景。
关键设计:感知模块可能采用预训练的目标检测模型(例如YOLO或Faster R-CNN)来检测图像中的物体,并使用点云处理技术(例如PointNet或PointRCNN)来提取3D信息。推理模块可能使用知识图谱或逻辑编程语言来表示和推理场景图。具体的参数设置、损失函数和网络结构等技术细节在论文中可能没有详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
该方法在JRDB-Reasoning数据集上进行了评估,结果表明其在拥挤的人工环境中表现出卓越的性能和可靠性。具体的性能数据、对比基线和提升幅度等信息在摘要中没有明确给出,属于未知信息。但摘要强调了该方法在保持轻量级设计的同时,实现了优于现有方法的性能。
🎯 应用场景
该研究成果可应用于机器人导航、人机交互、智能监控等领域。例如,在机器人导航中,机器人可以利用该方法理解周围环境,规划安全路径;在人机交互中,机器人可以理解人类的指令,执行复杂的任务;在智能监控中,系统可以自动检测异常行为,并发出警报。该研究有望推动机器人和人工智能技术的发展,提高其在实际应用中的智能化水平。
📄 摘要(原文)
Visual reasoning, particularly spatial reasoning, is a challenging cognitive task that requires understanding object relationships and their interactions within complex environments, especially in robotics domain. Existing vision_language models (VLMs) excel at perception tasks but struggle with fine-grained spatial reasoning due to their implicit, correlation-driven reasoning and reliance solely on images. We propose a novel neuro_symbolic framework that integrates both panoramic-image and 3D point cloud information, combining neural perception with symbolic reasoning to explicitly model spatial and logical relationships. Our framework consists of a perception module for detecting entities and extracting attributes, and a reasoning module that constructs a structured scene graph to support precise, interpretable queries. Evaluated on the JRDB-Reasoning dataset, our approach demonstrates superior performance and reliability in crowded, human_built environments while maintaining a lightweight design suitable for robotics and embodied AI applications.