Running VLAs at Real-time Speed
作者: Yunchao Ma, Yizhuang Zhou, Yunhuan Yang, Tiancai Wang, Haoqiang Fan
分类: cs.RO
发布日期: 2025-10-30
备注: Code is available at https://github.com/Dexmal/realtime-vla
🔗 代码/项目: GITHUB
💡 一句话要点
提出加速策略,单GPU实现30Hz多视角VLA实时运行,赋能动态机器人任务
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作 VLA 实时机器人控制 模型优化 GPU加速
📋 核心要点
- 大型VLA模型计算开销大,难以应用于需要实时响应的动态机器人任务。
- 通过一系列优化策略,消除VLA模型推理中的性能瓶颈,实现实时运行。
- 实验表明,优化后的pi0策略在抓取下落的笔的任务中成功率达到100%。
📝 摘要(中文)
本文展示了如何使用单个消费级GPU,以30Hz的帧率和高达480Hz的轨迹频率运行pi0级别的多视角VLA。这使得以前被认为大型VLA模型无法实现的动态和实时任务成为可能。为了实现这一目标,我们引入了一系列策略来消除模型推理中的开销。真实世界的实验表明,采用我们策略的pi0策略在抓取下落的笔的任务中实现了100%的成功率。基于这些结果,我们进一步提出了一个完整的流式推理框架,用于VLA的实时机器人控制。代码可在https://github.com/Dexmal/realtime-vla 获取。
🔬 方法详解
问题定义:现有的大型视觉语言动作(VLA)模型,例如基于Transformer的模型,计算复杂度高,推理速度慢,难以满足实时机器人控制的需求。尤其是在动态环境中,机器人需要快速感知环境变化并做出反应,对VLA模型的推理速度提出了更高的要求。现有方法难以在消费级GPU上实现VLA模型的实时运行,限制了其在动态机器人任务中的应用。
核心思路:本文的核心思路是通过一系列优化策略,降低VLA模型推理过程中的计算开销,从而在单个消费级GPU上实现实时运行。这些策略旨在消除模型推理中的性能瓶颈,例如减少不必要的计算、优化数据传输等,从而提高整体推理速度。
技术框架:论文提出了一个完整的流式推理框架,用于VLA的实时机器人控制。该框架包含以下主要模块:1) 多视角图像输入:从多个摄像头获取环境图像;2) VLA模型推理:使用优化后的VLA模型进行推理,生成动作指令;3) 机器人控制:根据动作指令控制机器人执行相应的动作。整个框架采用流式处理方式,保证了实时性。
关键创新:最重要的技术创新点在于一系列针对VLA模型推理的优化策略,这些策略能够显著降低计算开销,提高推理速度。这些策略可能包括但不限于:模型剪枝、量化、算子融合、内存优化等。与现有方法相比,本文的创新之处在于能够将大型VLA模型部署到消费级GPU上,并实现实时运行,从而赋能动态机器人任务。
关键设计:具体的技术细节未知,但可以推测可能包括:针对特定硬件架构的优化、定制化的算子实现、高效的内存管理策略、以及针对VLA模型特点的剪枝或量化方案。损失函数和网络结构可能沿用现有VLA模型的设计,但会针对实时性进行调整。
🖼️ 关键图片
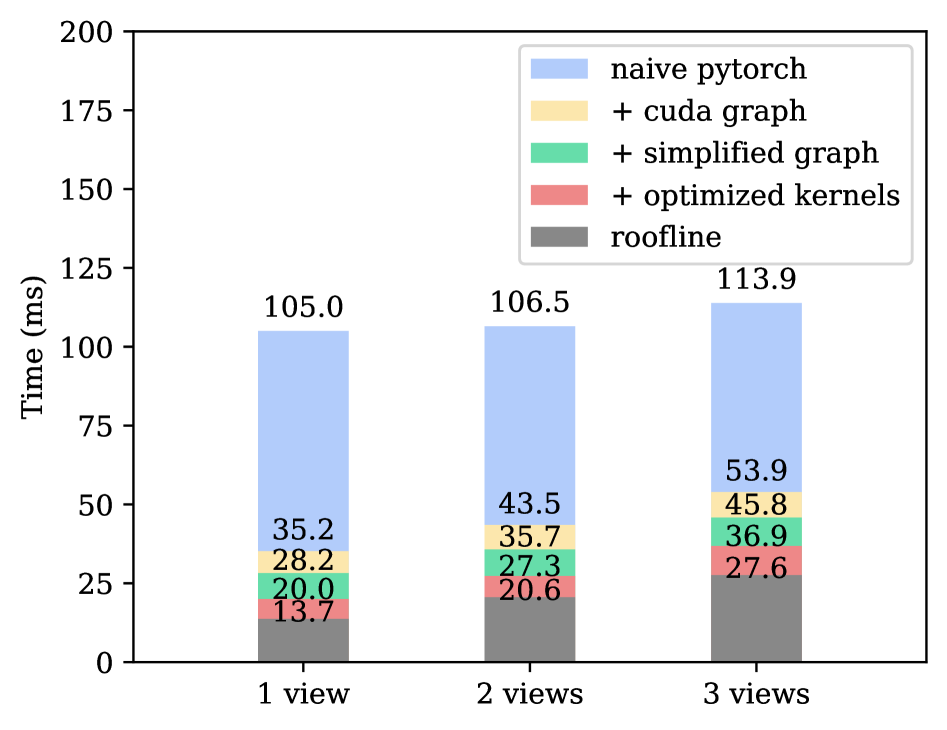
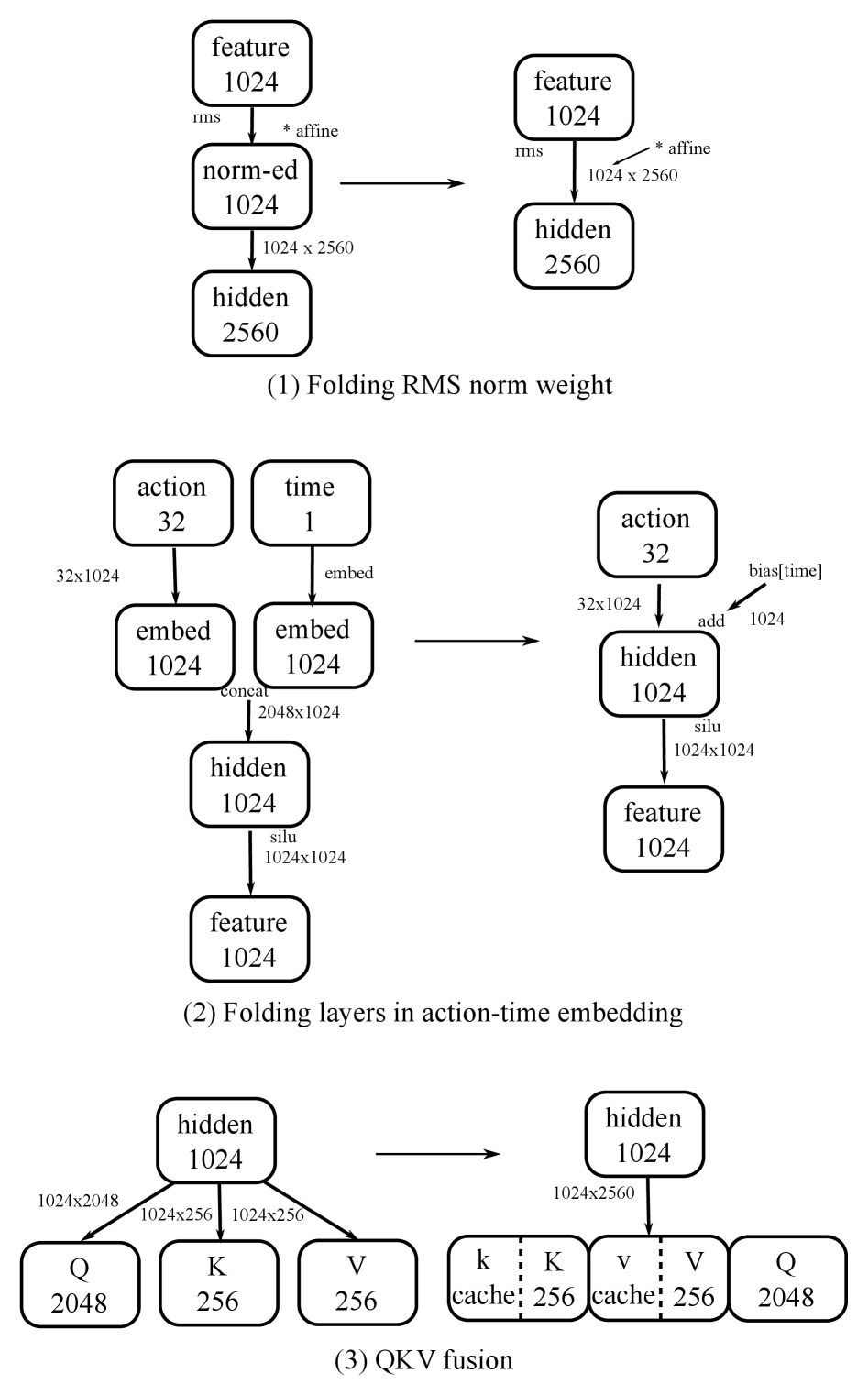

📊 实验亮点
实验结果表明,采用本文提出的优化策略,pi0策略在抓取下落的笔的任务中实现了100%的成功率。此外,该方法能够在单个消费级GPU上以30Hz的帧率和高达480Hz的轨迹频率运行pi0级别的多视角VLA,显著提升了VLA模型的推理速度。
🎯 应用场景
该研究成果可广泛应用于需要实时响应的动态机器人任务,例如:高速抓取、动态避障、人机协作等。通过将大型VLA模型部署到消费级GPU上,降低了硬件成本,使得更多机器人应用成为可能。未来,该技术有望推动机器人智能化水平的提升,促进机器人在工业、服务等领域的广泛应用。
📄 摘要(原文)
In this paper, we show how to run pi0-level multi-view VLA at 30Hz frame rate and at most 480Hz trajectory frequency using a single consumer GPU. This enables dynamic and real-time tasks that were previously believed to be unattainable by large VLA models. To achieve it, we introduce a bag of strategies to eliminate the overheads in model inference. The real-world experiment shows that the pi0 policy with our strategy achieves a 100% success rate in grasping a falling pen task. Based on the results, we further propose a full streaming inference framework for real-time robot control of VLA. Code is available at https://github.com/Dexmal/realtime-vla.