Hybrid Consistency Policy: Decoupling Multi-Modal Diversity and Real-Time Efficiency in Robotic Manipulation
作者: Qianyou Zhao, Yuliang Shen, Xuanran Zhai, Ce Hao, Duidi Wu, Jin Qi, Jie Hu, Qiaojun Yu
分类: cs.RO
发布日期: 2025-10-30
💡 一句话要点
提出混合一致性策略HCP,解耦机器人操作中的多模态多样性和实时效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 模仿学习 扩散模型 一致性模型 实时控制
📋 核心要点
- 基于扩散模型的模仿学习在视觉运动策略中表现出色,但难以兼顾快速采样和多模态行为。
- HCP通过短时随机过程加单步一致性跳跃,以及时变一致性蒸馏,实现了多模态性和实时性的解耦。
- 实验表明,HCP在保证精度的同时显著降低了延迟,为机器人策略提供了更优的精度-效率权衡。
📝 摘要(中文)
在视觉运动策略学习中,基于扩散的模仿学习因其捕获多样化行为的能力而被广泛采用。然而,构建在普通和随机去噪过程之上的方法难以同时实现快速采样和强大的多模态性。为了解决这些挑战,我们提出了混合一致性策略(HCP)。HCP运行一个短的随机前缀,直到一个自适应切换时间,然后应用一个单步一致性跳跃来生成最终动作。为了对齐这种单跳生成,HCP执行时变一致性蒸馏,它结合了轨迹一致性目标(保持相邻预测的连贯性)和去噪匹配目标(提高局部保真度)。在模拟和真实机器人实验中,具有25个SDE步骤加一次跳跃的HCP在精度和模式覆盖率方面接近80步DDPM教师,同时显著降低了延迟。这些结果表明,多模态性不需要缓慢的推理,并且切换时间将模式保留与速度解耦。它为机器人策略产生了一种实用的精度-效率权衡。
🔬 方法详解
问题定义:现有基于扩散模型的视觉运动策略学习方法,虽然能够捕捉到多模态行为,但在推理速度上存在瓶颈。传统的去噪扩散概率模型(DDPM)和随机微分方程(SDE)方法需要大量的迭代步骤才能生成高质量的动作,这限制了它们在实时机器人控制中的应用。因此,如何在保证策略多样性的同时,提高推理效率,是本论文要解决的核心问题。
核心思路:论文的核心思路是将扩散过程分解为两个阶段:一个短时随机前缀和一个单步一致性跳跃。短时随机前缀用于探索动作空间,捕捉多模态行为;单步一致性跳跃则利用一致性模型,直接从当前状态预测最终动作,从而加速推理过程。通过这种混合策略,HCP旨在解耦多模态多样性和实时效率,实现两者之间的平衡。
技术框架:HCP的整体框架包括以下几个主要模块:1) 短时随机微分方程(SDE)过程:用于生成初始的动作序列,捕捉策略的多样性。2) 自适应切换时间:根据当前状态动态地决定何时从SDE过程切换到一致性跳跃。3) 一致性模型:用于执行单步一致性跳跃,直接预测最终动作。4) 时变一致性蒸馏:用于训练一致性模型,使其能够模仿SDE过程的行为,并保持轨迹的连贯性。
关键创新:HCP的关键创新在于混合一致性策略,它将扩散过程分解为随机探索和一致性预测两个阶段,并通过自适应切换时间将两者连接起来。这种设计允许HCP在保证策略多样性的同时,显著提高推理速度。此外,时变一致性蒸馏方法也保证了一致性模型能够有效地模仿SDE过程的行为,并保持轨迹的连贯性。
关键设计:HCP的关键设计包括:1) 自适应切换时间的计算方法,它基于当前状态的不确定性来决定何时切换到一致性跳跃。2) 时变一致性蒸馏的损失函数,它结合了轨迹一致性目标和去噪匹配目标,以提高一致性模型的性能。3) 一致性模型的网络结构,它需要能够有效地从当前状态预测最终动作。
🖼️ 关键图片


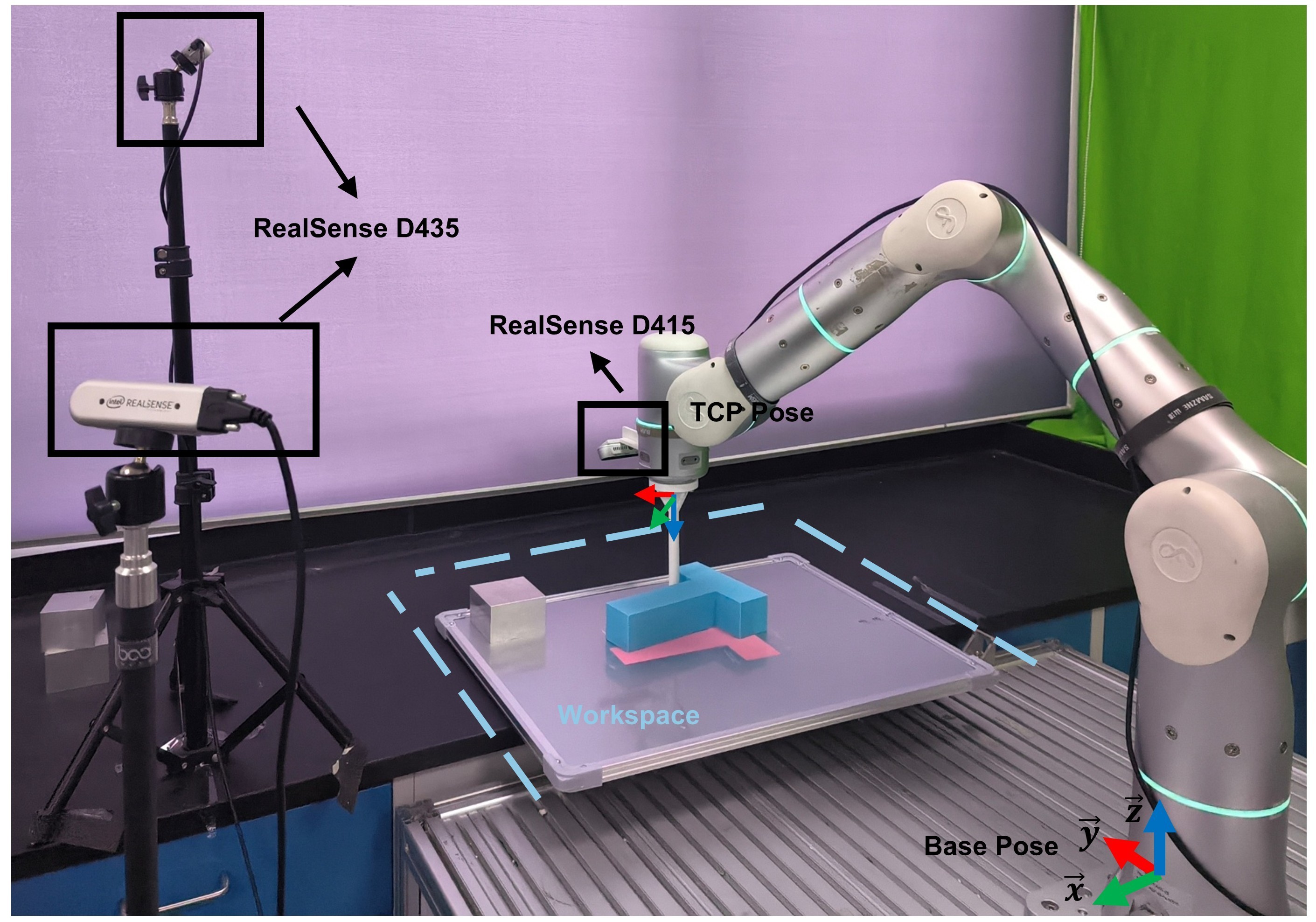
📊 实验亮点
实验结果表明,HCP在模拟和真实机器人实验中均取得了显著的性能提升。在精度和模式覆盖率方面,具有25个SDE步骤加一次跳跃的HCP接近80步DDPM教师的水平,同时显著降低了延迟。这表明HCP能够在保证策略多样性的同时,实现更快的推理速度,为机器人策略提供了一种实用的精度-效率权衡。
🎯 应用场景
HCP具有广泛的应用前景,可用于各种需要实时控制的机器人操作任务,例如:高速抓取、动态避障、人机协作等。该方法能够提高机器人在复杂环境中的适应性和灵活性,使其能够更好地完成各种任务。此外,HCP还可以应用于自动驾驶、游戏AI等领域,提升系统的智能化水平。
📄 摘要(原文)
In visuomotor policy learning, diffusion-based imitation learning has become widely adopted for its ability to capture diverse behaviors. However, approaches built on ordinary and stochastic denoising processes struggle to jointly achieve fast sampling and strong multi-modality. To address these challenges, we propose the Hybrid Consistency Policy (HCP). HCP runs a short stochastic prefix up to an adaptive switch time, and then applies a one-step consistency jump to produce the final action. To align this one-jump generation, HCP performs time-varying consistency distillation that combines a trajectory-consistency objective to keep neighboring predictions coherent and a denoising-matching objective to improve local fidelity. In both simulation and on a real robot, HCP with 25 SDE steps plus one jump approaches the 80-step DDPM teacher in accuracy and mode coverage while significantly reducing latency. These results show that multi-modality does not require slow inference, and a switch time decouples mode retention from speed. It yields a practical accuracy efficiency trade-off for robot policies.