Heuristic Adaptation of Potentially Misspecified Domain Support for Likelihood-Free Inference in Stochastic Dynamical Systems
作者: Georgios Kamaras, Craig Innes, Subramanian Ramamoorthy
分类: cs.RO, cs.LG
发布日期: 2025-10-30 (更新: 2025-11-11)
备注: 20 pages, 18 figures, algorithm lines cleveref fixed for pdflatex 2025
💡 一句话要点
提出三种启发式LFI变体,自适应调整领域支持,提升随机动力系统参数推断与策略学习效果。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无似然推断 领域自适应 随机动力系统 机器人操作 参数推断
📋 核心要点
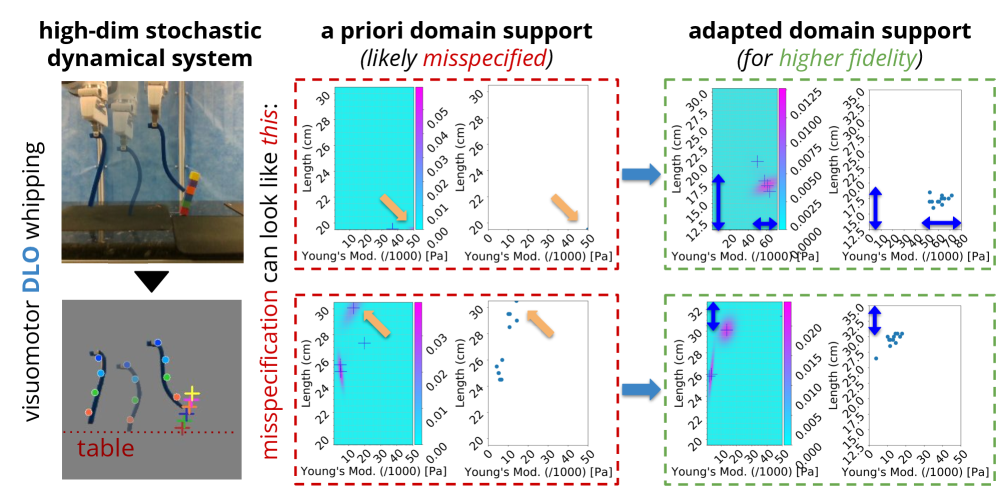
- 传统LFI方法依赖固定的采样支持域,当该支持域与真实分布不匹配时,会导致次优的后验推断结果。
- 论文提出EDGE、MODE和CENTRE三种启发式LFI变体,通过分析后验模式偏移,自适应调整采样支持域。
- 实验表明,该方法在随机动力系统和DLO操作任务中,能提升参数推断精度和策略学习的鲁棒性。
📝 摘要(中文)
在机器人领域,无似然推断(LFI)可以提供领域分布,从而在参数化的部署条件下调整学习到的智能体。LFI假设一个任意的采样支持域,该支持域在初始通用先验被迭代细化为更具描述性的后验时保持不变。然而,一个可能错误指定的支持域可能导致次优但错误确定的后验。为了解决这个问题,我们提出了三种启发式LFI变体:EDGE、MODE和CENTRE。每种方法都以其自身的方式解释推断步骤中的后验模式偏移,并在集成到LFI步骤中时,自适应地调整支持域以及后验推断。我们首先揭示了支持域错误指定的问题,并使用随机动力学基准评估了我们的启发式方法。然后,我们评估了启发式支持域自适应对动态可变形线性对象(DLO)操作任务的参数推断和策略学习的影响。推断结果可以对参数化的DLO进行更精细的长度和刚度分类。当将得到的后验用作基于模拟的策略学习的领域分布时,它们可以带来更强大的以对象为中心的智能体性能。
🔬 方法详解
问题定义:论文旨在解决无似然推断(LFI)中,由于预先设定的采样支持域(support)与真实参数分布不匹配,导致后验推断结果不准确的问题。现有LFI方法通常假设一个固定的支持域,这在实际应用中可能并不成立,尤其是在处理复杂或未知的动力系统时。这种错误指定的支持域会导致推断结果的偏差,进而影响下游任务的性能。
核心思路:论文的核心思路是根据LFI过程中后验分布的变化,动态地调整采样支持域。具体来说,通过观察后验分布的模式(mode)在迭代过程中的偏移,来判断当前支持域是否合理,并据此进行调整。这种自适应调整可以使采样更集中于真实参数分布的区域,从而提高推断的准确性。
技术框架:整体框架是在标准的LFI流程中,加入一个支持域自适应的模块。该模块在每次LFI迭代后,根据后验分布的模式偏移,使用三种不同的启发式方法(EDGE、MODE和CENTRE)来调整支持域的边界或中心。调整后的支持域将用于下一次LFI迭代的采样。整个流程包括:1) 初始化先验分布和支持域;2) 进行LFI迭代,包括采样、模拟和评估;3) 根据后验分布的模式偏移,使用启发式方法调整支持域;4) 重复步骤2和3,直到收敛。
关键创新:论文的关键创新在于提出了三种启发式方法(EDGE、MODE和CENTRE)来实现支持域的自适应调整。这三种方法分别从不同的角度解释后验模式偏移,并据此调整支持域的边界或中心。EDGE方法关注后验分布的边缘,MODE方法关注后验分布的模式本身,CENTRE方法关注后验分布的中心。这种自适应调整机制能够有效地应对支持域错误指定的问题,提高LFI的鲁棒性和准确性。
关键设计:三种启发式方法EDGE、MODE和CENTRE的具体实现细节是关键设计。EDGE方法通过扩展或收缩支持域的边界来适应后验分布的边缘。MODE方法通过将支持域的中心移动到后验分布的模式附近来提高采样效率。CENTRE方法则通过调整支持域的形状来更好地覆盖后验分布。这些方法的具体参数设置,如调整步长和阈值,需要根据具体问题进行调整。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的启发式LFI变体在随机动力系统和DLO操作任务中均取得了显著的性能提升。在DLO操作任务中,该方法能够更准确地推断DLO的长度和刚度参数,并显著提升基于模拟的策略学习的鲁棒性。具体而言,使用自适应支持域的LFI方法能够使智能体在不同DLO参数下的性能更加稳定。
🎯 应用场景
该研究成果可应用于机器人操作、控制和仿真等领域,尤其是在处理具有不确定性和复杂动力学的系统时。例如,可用于提高机器人对柔性物体的操作能力,或用于优化机器人控制器的参数。此外,该方法还可推广到其他需要参数推断的领域,如生物学、金融学等。
📄 摘要(原文)
In robotics, likelihood-free inference (LFI) can provide the domain distribution that adapts a learnt agent in a parametric set of deployment conditions. LFI assumes an arbitrary support for sampling, which remains constant as the initial generic prior is iteratively refined to more descriptive posteriors. However, a potentially misspecified support can lead to suboptimal, yet falsely certain, posteriors. To address this issue, we propose three heuristic LFI variants: EDGE, MODE, and CENTRE. Each interprets the posterior mode shift over inference steps in its own way and, when integrated into an LFI step, adapts the support alongside posterior inference. We first expose the support misspecification issue and evaluate our heuristics using stochastic dynamical benchmarks. We then evaluate the impact of heuristic support adaptation on parameter inference and policy learning for a dynamic deformable linear object (DLO) manipulation task. Inference results in a finer length and stiffness classification for a parametric set of DLOs. When the resulting posteriors are used as domain distributions for sim-based policy learning, they lead to more robust object-centric agent performance.