Hybrid DQN-TD3 Reinforcement Learning for Autonomous Navigation in Dynamic Environments
作者: Xiaoyi He, Danggui Chen, Zhenshuo Zhang, Zimeng Bai
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-30
备注: 6 pages, 5 figures; ROS+Gazebo (TurtleBot3) implementation; evaluation with PathBench metrics; code (primary): https://github.com/MayaCHEN-github/HierarchicalRL-robot-navigation; mirror (for reproducibility): https://github.com/ShowyHe/DRL-robot-navigation
💡 一句话要点
提出混合DQN-TD3强化学习方法,用于动态环境中自主导航。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 自主导航 深度Q网络 TD3 分层控制 机器人 动态环境
📋 核心要点
- 现有方法在动态环境中自主导航面临挑战,难以兼顾全局规划和局部控制的平滑性。
- 采用分层强化学习框架,DQN负责高层决策,TD3负责底层控制,实现全局规划与局部控制的结合。
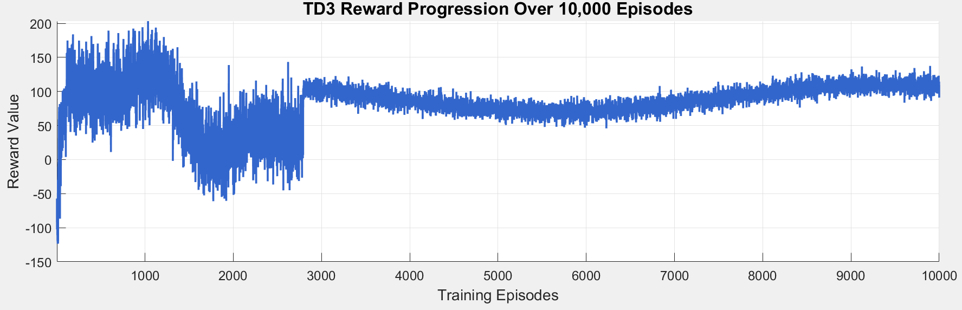
- 实验结果表明,该方法在成功率和样本效率方面优于单一算法和规则方法,并具有更好的泛化能力。
📝 摘要(中文)
本文提出了一种分层路径规划与控制框架,该框架结合了高层深度Q网络(DQN)用于离散子目标选择和低层双延迟深度确定性策略梯度(TD3)控制器用于连续动作控制。高层模块选择行为和子目标;低层模块执行平滑的速度指令。我们设计了一种实用的奖励塑造方案(方向、距离、避障、动作平滑性、碰撞惩罚、时间惩罚和进度),以及基于激光雷达的安全门,以防止不安全的运动。该系统在ROS + Gazebo(TurtleBot3)中实现,并使用PathBench指标(包括成功率、碰撞率、路径效率和重新规划效率)在动态和部分可观察的环境中进行评估。实验表明,与单一算法基线(单独的DQN或TD3)和基于规则的规划器相比,该方法提高了成功率和样本效率,更好地泛化到未见过的障碍物配置,并减少了突发的控制变化。代码和评估脚本可在项目存储库中找到。
🔬 方法详解
问题定义:在动态和部分可观测环境中,自主导航需要同时考虑全局路径规划和局部运动控制。传统的基于规则的规划器难以适应复杂环境,而单一的强化学习算法可能存在样本效率低、泛化能力差或控制不平滑等问题。
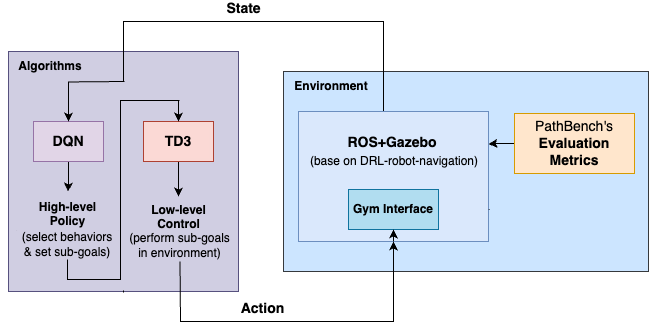
核心思路:采用分层强化学习的思想,将导航任务分解为高层决策和低层控制两个部分。高层DQN负责选择离散的子目标,引导机器人朝向目标区域;低层TD3负责根据当前状态和高层目标,输出连续的控制指令,实现平滑的运动控制。这种分层结构能够有效降低问题的复杂度,提高学习效率和泛化能力。
技术框架:整体框架包含两个主要模块:高层DQN模块和低层TD3模块。高层DQN模块接收环境状态(例如,激光雷达数据),输出离散的动作,代表选择的子目标。低层TD3模块接收环境状态和高层DQN的输出,输出连续的控制指令(例如,线速度和角速度)。此外,还包括奖励塑造模块和安全门模块,用于引导学习过程和防止不安全行为。
关键创新:该方法的核心创新在于将DQN和TD3两种强化学习算法结合起来,利用DQN的离散动作空间处理高层决策,利用TD3的连续动作空间处理低层控制。这种混合方法能够充分发挥两种算法的优势,提高导航性能。此外,奖励塑造方案和安全门模块的设计也对提高学习效率和安全性起到了重要作用。
关键设计:奖励函数的设计至关重要,包括方向奖励、距离奖励、避障奖励、动作平滑性奖励、碰撞惩罚、时间惩罚和进度奖励。这些奖励项共同引导机器人学习到安全、高效的导航策略。安全门模块基于激光雷达数据,实时检测潜在的碰撞风险,并阻止不安全的动作。DQN和TD3的网络结构采用深度神经网络,通过经验回放和目标网络等技术提高学习的稳定性和效率。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该混合DQN-TD3方法在动态环境中实现了更高的成功率和样本效率,优于单独使用DQN或TD3的基线方法,以及基于规则的规划器。具体而言,该方法能够更好地泛化到未见过的障碍物配置,并减少了突发的控制变化,从而提高了导航的平滑性和安全性。PathBench指标的评估结果也验证了该方法的有效性。
🎯 应用场景
该研究成果可应用于各种需要自主导航的机器人系统,例如服务机器人、物流机器人、无人驾驶车辆等。通过结合全局规划和局部控制,该方法能够使机器人在复杂、动态的环境中安全、高效地完成导航任务,具有重要的实际应用价值和广阔的应用前景。
📄 摘要(原文)
This paper presents a hierarchical path-planning and control framework that combines a high-level Deep Q-Network (DQN) for discrete sub-goal selection with a low-level Twin Delayed Deep Deterministic Policy Gradient (TD3) controller for continuous actuation. The high-level module selects behaviors and sub-goals; the low-level module executes smooth velocity commands. We design a practical reward shaping scheme (direction, distance, obstacle avoidance, action smoothness, collision penalty, time penalty, and progress), together with a LiDAR-based safety gate that prevents unsafe motions. The system is implemented in ROS + Gazebo (TurtleBot3) and evaluated with PathBench metrics, including success rate, collision rate, path efficiency, and re-planning efficiency, in dynamic and partially observable environments. Experiments show improved success rate and sample efficiency over single-algorithm baselines (DQN or TD3 alone) and rule-based planners, with better generalization to unseen obstacle configurations and reduced abrupt control changes. Code and evaluation scripts are available at the project repository.