Using VLM Reasoning to Constrain Task and Motion Planning
作者: Muyang Yan, Miras Mengdibayev, Ardon Floros, Weihang Guo, Lydia E. Kavraki, Zachary Kingston
分类: cs.RO
发布日期: 2025-10-29
备注: 8 pages, 7 figures, 1 table. Submitted to ICRA 2026
💡 一句话要点
VIZ-COAST:利用视觉语言模型推理约束任务与运动规划,提升规划效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 任务与运动规划 视觉语言模型 机器人 常识推理 约束规划
📋 核心要点
- 现有任务与运动规划方法在细化失败后才添加约束,导致大量无效搜索。
- VIZ-COAST利用视觉语言模型的常识推理能力,提前识别并约束不可行的任务计划。
- 实验表明,VIZ-COAST能有效减少规划时间,甚至消除细化失败,并具有良好的泛化性。
📝 摘要(中文)
在任务与运动规划(TAMP)中,高层任务规划在世界的抽象表示上进行,以便在长时程机器人问题中实现高效搜索。然而,这些任务层计划的可行性依赖于抽象表示向下细化为连续运动的能力。当一个领域的可细化性较差时,表面上有效的任务层计划最终可能在运动规划期间失败,需要重新规划,从而导致整体性能下降。先前的工作通过将细化问题编码为约束来剪枝不可行的任务计划来缓解这个问题。然而,这些方法仅在细化失败时才添加约束,在不可行的分支上花费了大量的搜索精力。我们提出了VIZ-COAST,一种利用大型预训练视觉语言模型的常识空间推理能力,先验地识别向下细化问题的方法,从而绕过了在规划期间修复这些失败的需要。在两个具有挑战性的TAMP领域进行的实验表明,我们的方法能够从图像和领域描述中提取合理的约束,从而大大减少了规划时间,并且在某些情况下,完全消除了向下细化失败,推广到更广泛领域中的各种实例。
🔬 方法详解
问题定义:任务与运动规划(TAMP)旨在解决机器人如何在复杂环境中完成长期任务的问题。现有方法通常在高层抽象空间进行任务规划,然后将抽象计划细化为具体的运动轨迹。然而,当抽象计划难以细化为可行运动时,会导致规划失败和大量重新规划,效率低下。现有方法主要在细化失败后才添加约束,无法避免前期无效搜索。
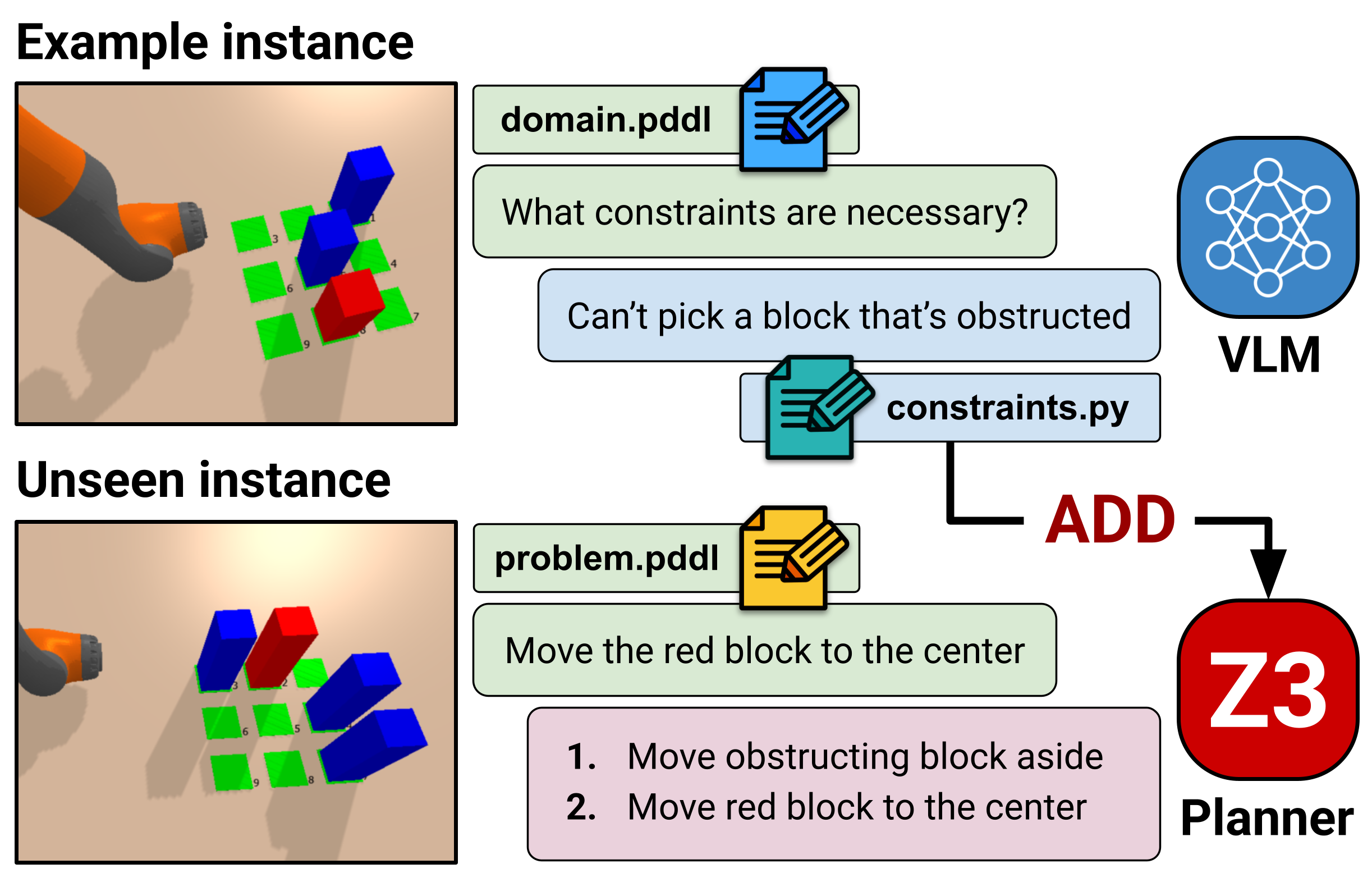
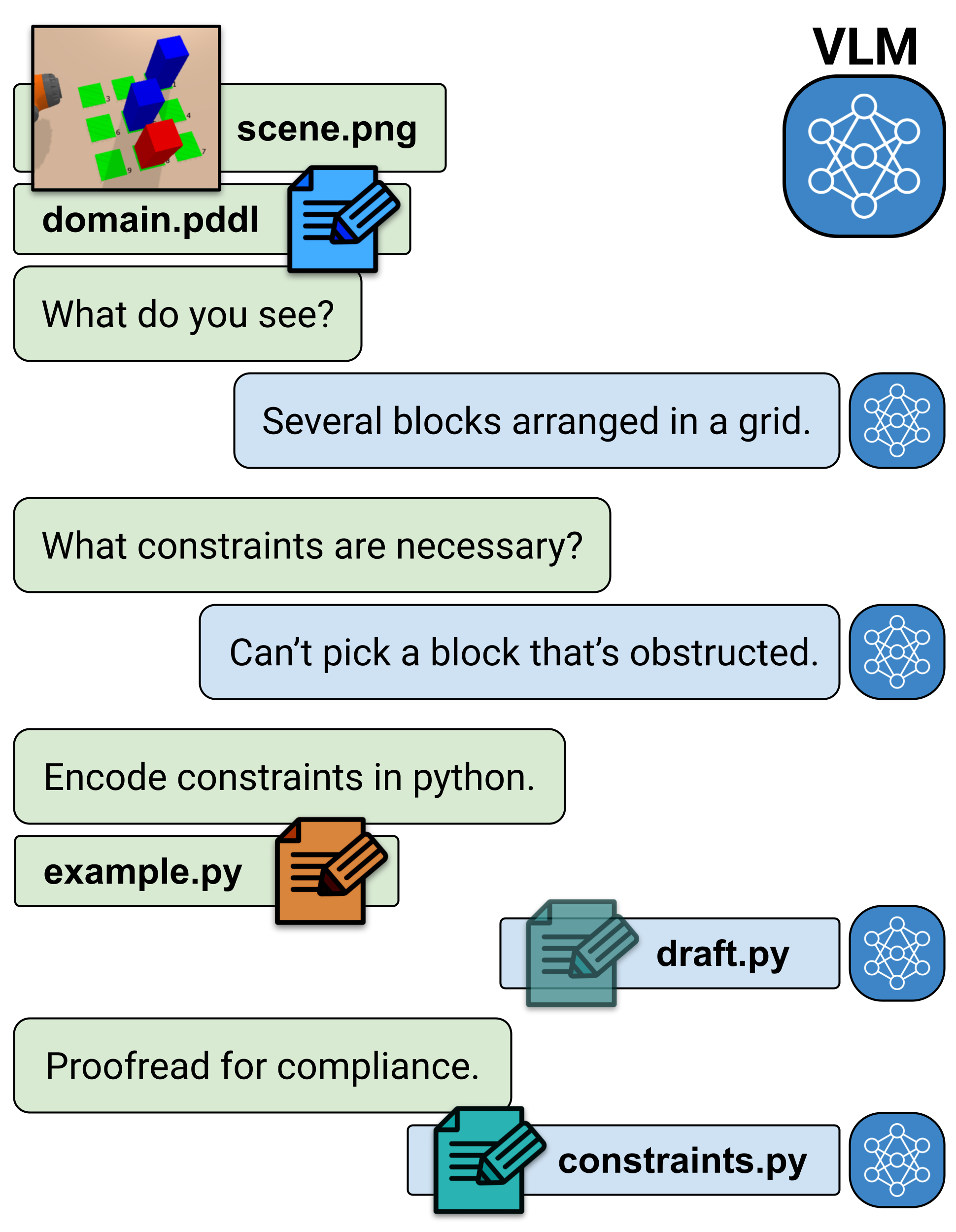
核心思路:VIZ-COAST的核心思想是利用预训练的视觉语言模型(VLM)的常识推理能力,在任务规划阶段预先识别并排除那些难以细化的抽象计划。通过分析环境图像和任务描述,VLM可以预测哪些动作序列可能导致碰撞、不可达等问题,从而生成约束条件,指导任务规划器避开这些潜在的失败路径。
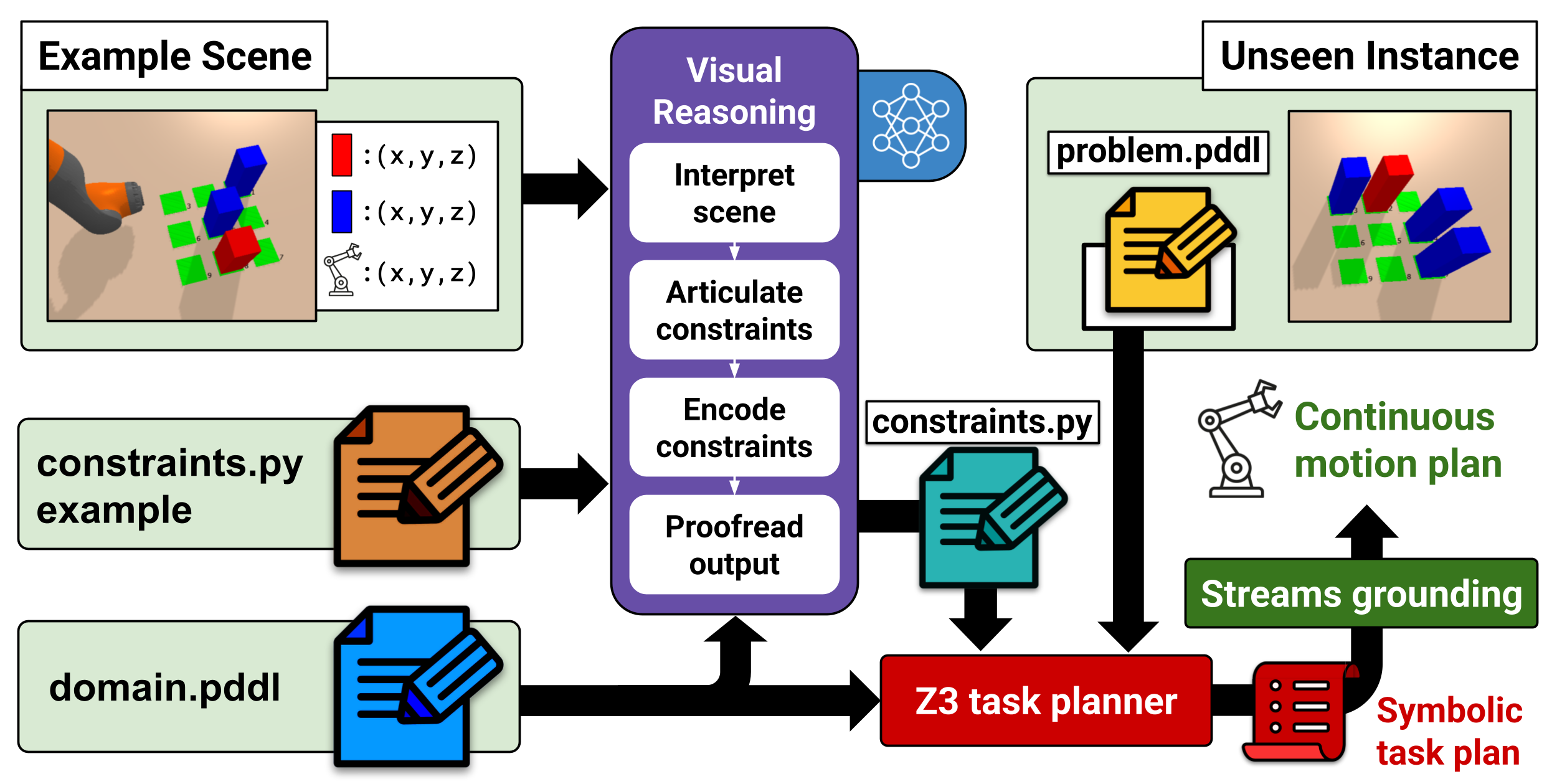
技术框架:VIZ-COAST的整体框架包含以下几个主要步骤:1) 场景理解:输入环境图像和任务描述,VLM对场景进行理解,提取关键对象和空间关系。2) 约束预测:VLM基于场景理解,预测哪些动作序列可能违反物理约束或导致细化失败。3) 约束集成:将VLM预测的约束条件集成到任务规划器中,指导其生成可行的抽象计划。4) 运动规划:将抽象计划细化为具体的运动轨迹。如果细化成功,则执行;否则,返回任务规划阶段,重新规划。
关键创新:VIZ-COAST的关键创新在于利用VLM的常识推理能力,实现了对任务规划的先验约束。与现有方法相比,VIZ-COAST无需等到细化失败才添加约束,而是提前预测潜在的失败路径,从而避免了大量的无效搜索。这种先验约束的方法可以显著提高任务与运动规划的效率和鲁棒性。
关键设计:VIZ-COAST的关键设计包括:1) VLM的选择:选择具有强大视觉理解和常识推理能力的VLM,例如CLIP或类似模型。2) 约束表示:将VLM预测的约束条件表示为逻辑规则或概率分布,以便与任务规划器集成。3) 约束权重:根据VLM的置信度,对约束条件赋予不同的权重,平衡约束的严格性和灵活性。4) 任务规划器集成:选择合适的任务规划器,例如STRIPS或PDDL,并修改其搜索算法,使其能够有效地利用VLM提供的约束条件。
🖼️ 关键图片
📊 实验亮点
在两个具有挑战性的TAMP领域进行的实验表明,VIZ-COAST能够从图像和领域描述中提取合理的约束,从而大大减少了规划时间。在某些情况下,VIZ-COAST完全消除了向下细化失败,并且能够推广到更广泛领域中的各种实例。具体性能提升数据未知,但结论是显著减少规划时间并消除细化失败。
🎯 应用场景
VIZ-COAST可应用于各种机器人任务与运动规划场景,例如家庭服务机器人、工业自动化、自动驾驶等。通过利用视觉语言模型的常识推理能力,可以提高机器人在复杂、非结构化环境中执行任务的效率和可靠性,降低人工干预的需求,加速机器人技术的普及和应用。
📄 摘要(原文)
In task and motion planning, high-level task planning is done over an abstraction of the world to enable efficient search in long-horizon robotics problems. However, the feasibility of these task-level plans relies on the downward refinability of the abstraction into continuous motion. When a domain's refinability is poor, task-level plans that appear valid may ultimately fail during motion planning, requiring replanning and resulting in slower overall performance. Prior works mitigate this by encoding refinement issues as constraints to prune infeasible task plans. However, these approaches only add constraints upon refinement failure, expending significant search effort on infeasible branches. We propose VIZ-COAST, a method of leveraging the common-sense spatial reasoning of large pretrained Vision-Language Models to identify issues with downward refinement a priori, bypassing the need to fix these failures during planning. Experiments on two challenging TAMP domains show that our approach is able to extract plausible constraints from images and domain descriptions, drastically reducing planning times and, in some cases, eliminating downward refinement failures altogether, generalizing to a diverse range of instances from the broader domain.