Towards Quadrupedal Jumping and Walking for Dynamic Locomotion using Reinforcement Learning
作者: Jørgen Anker Olsen, Lars Rønhaug Pettersen, Kostas Alexis
分类: cs.RO
发布日期: 2025-10-28
备注: 8 pages
💡 一句话要点
提出基于课程学习的强化学习框架,实现四足机器人动态跳跃与行走
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 强化学习 课程学习 动态运动 跳跃 行走 Sim2Real
📋 核心要点
- 现有四足机器人动态运动控制方法依赖人工设计的复杂控制器或轨迹优化,泛化性和鲁棒性不足。
- 利用课程强化学习,结合奖励函数设计和参考状态初始化,加速策略学习,实现高性能跳跃和行走。
- 实验表明,该方法在真实机器人上实现了厘米级精度的1.25米水平跳跃和1米垂直跳跃,并具备全向跳跃能力。
📝 摘要(中文)
本文提出了一种基于课程学习的强化学习框架,用于训练机器人`Olympus'精确且高性能的跳跃策略。针对垂直和水平跳跃,开发了独立的策略,并采用了一种简单而有效的策略。首先,利用抛物线运动定律来密集化固有的稀疏跳跃奖励。其次,采用参考状态初始化方案来加速动态跳跃行为的探索,而无需依赖参考轨迹。此外,本文还提出了一种行走策略,当与跳跃策略相结合时,可实现通用且动态的运动能力。全面的测试验证了在各种地形表面上的行走性能以及超过先前工作的跳跃性能,有效地弥合了Sim2Real差距。实验验证表明,水平跳跃距离可达1.25米,精度达到厘米级,垂直跳跃距离可达1.0米。此外,我们表明,只需进行少量修改,所提出的方法即可用于学习全向跳跃。
🔬 方法详解
问题定义:四足机器人动态运动控制,特别是跳跃,是一个具有挑战性的问题。现有的方法通常依赖于人工设计的复杂控制器或轨迹优化,这些方法泛化能力差,难以适应不同的环境和任务。此外,从仿真到真实的迁移(Sim2Real)也面临挑战,因为仿真环境难以完全模拟真实世界的复杂性。
核心思路:本文的核心思路是利用强化学习,通过与环境的交互来学习最优的跳跃和行走策略。为了加速学习过程并提高策略的性能,采用了课程学习的方法,逐步增加任务的难度。此外,还设计了特定的奖励函数和参考状态初始化方案,以引导智能体探索有效的跳跃行为。
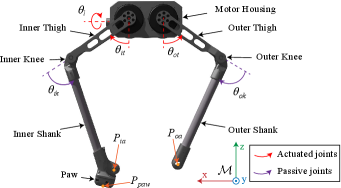
技术框架:整体框架包括以下几个主要模块:1) 状态表示:将机器人的关节角度、速度等信息作为状态输入。2) 动作空间:定义机器人可以执行的动作,例如关节力矩。3) 奖励函数:设计奖励函数来鼓励机器人完成跳跃和行走任务,包括跳跃距离、高度、落地精度等指标。4) 强化学习算法:使用PPO等强化学习算法来训练策略。5) 课程学习:逐步增加任务的难度,例如从简单的垂直跳跃到复杂的水平跳跃。6) 参考状态初始化:通过参考状态初始化,加速探索过程。
关键创新:本文的关键创新在于:1) 提出了一种基于课程学习的强化学习框架,可以有效地训练四足机器人的跳跃和行走策略。2) 设计了一种新的奖励函数,利用抛物线运动定律来密集化稀疏奖励,从而加速学习过程。3) 提出了一种参考状态初始化方案,可以加速动态跳跃行为的探索,而无需依赖参考轨迹。
关键设计:奖励函数的设计至关重要,本文使用了基于抛物线运动定律的奖励函数,鼓励机器人达到期望的跳跃距离和高度。参考状态初始化方案通过在训练初期提供一些接近最优的初始状态,来引导智能体探索有效的跳跃行为。网络结构方面,使用了多层感知机(MLP)作为策略网络和价值网络。此外,还使用了Adam优化器来训练网络。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在真实机器人`Olympus'上实现了厘米级精度的1.25米水平跳跃和1米垂直跳跃,超过了以往的研究成果。通过少量修改,该方法还可用于学习全向跳跃。此外,实验还验证了该方法在不同地形上的行走能力,表明其具有良好的泛化性和鲁棒性。
🎯 应用场景
该研究成果可应用于搜救、勘探、物流等领域。具备动态跳跃和行走能力的四足机器人能够适应复杂地形,执行人类难以完成的任务。例如,在灾难现场进行搜索和救援,在崎岖的山区进行勘探,或在仓库中进行高效的物流运输。未来,该技术有望进一步提升机器人的自主性和适应性,使其在更多领域发挥作用。
📄 摘要(原文)
This paper presents a curriculum-based reinforcement learning framework for training precise and high-performance jumping policies for the robot `Olympus'. Separate policies are developed for vertical and horizontal jumps, leveraging a simple yet effective strategy. First, we densify the inherently sparse jumping reward using the laws of projectile motion. Next, a reference state initialization scheme is employed to accelerate the exploration of dynamic jumping behaviors without reliance on reference trajectories. We also present a walking policy that, when combined with the jumping policies, unlocks versatile and dynamic locomotion capabilities. Comprehensive testing validates walking on varied terrain surfaces and jumping performance that exceeds previous works, effectively crossing the Sim2Real gap. Experimental validation demonstrates horizontal jumps up to 1.25 m with centimeter accuracy and vertical jumps up to 1.0 m. Additionally, we show that with only minor modifications, the proposed method can be used to learn omnidirectional jumping.