LagMemo: Language 3D Gaussian Splatting Memory for Multi-modal Open-vocabulary Multi-goal Visual Navigation
作者: Haotian Zhou, Xiaole Wang, He Li, Fusheng Sun, Shengyu Guo, Guolei Qi, Jianghuan Xu, Huijing Zhao
分类: cs.RO, cs.AI
发布日期: 2025-10-28
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
提出LagMemo,利用语言3D高斯溅射记忆实现多模态开放词汇多目标视觉导航
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 视觉导航 多模态学习 开放词汇 3D高斯溅射 机器人 语言嵌入 目标定位
📋 核心要点
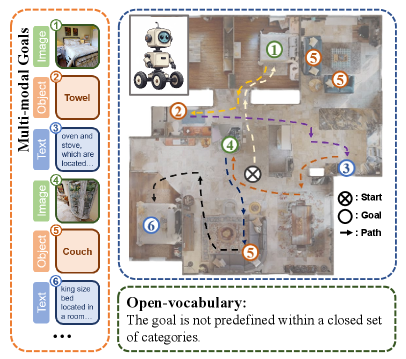
- 现有视觉导航方法通常局限于单目标、单模态和封闭集目标设置,难以满足实际需求。
- LagMemo构建语言3D高斯溅射记忆,通过查询记忆预测目标位置,并结合局部感知验证机制动态匹配目标。
- 实验表明,LagMemo在多模态开放词汇目标定位和多目标视觉导航方面优于现有方法,并提出了GOAT-Core基准。
📝 摘要(中文)
本文提出LagMemo,一个利用语言3D高斯溅射记忆的导航系统,旨在解决多模态、开放词汇目标查询和多目标视觉导航的实际需求。LagMemo在探索过程中构建统一的3D语言记忆。对于输入的任务目标,系统查询记忆,预测候选目标位置,并整合基于局部感知的验证机制,在导航过程中动态匹配和验证目标。为了公平和严格的评估,我们整理了GOAT-Core,这是一个从GOAT-Bench中提取的高质量核心分割,专门用于多模态开放词汇多目标视觉导航。实验结果表明,LagMemo的记忆模块能够实现有效的多模态开放词汇目标定位,并且LagMemo在多目标视觉导航中优于最先进的方法。
🔬 方法详解
问题定义:现有的视觉导航方法在处理多目标、多模态(例如,文本描述和图像)以及开放词汇(即目标不在预定义的类别中)的任务时存在局限性。这些方法通常针对单目标、单模态和封闭集环境设计,无法很好地泛化到更复杂的真实场景中。痛点在于缺乏一种能够有效整合多模态信息、处理开放词汇目标并进行多目标导航的统一框架。
核心思路:LagMemo的核心思路是构建一个基于语言的3D高斯溅射(3D Gaussian Splatting)记忆,用于存储环境信息和目标描述。通过将视觉信息和语言信息融合到3D场景表示中,系统可以根据输入的任务目标(例如,文本描述)查询记忆,预测候选目标位置。此外,LagMemo还整合了局部感知验证机制,用于在导航过程中动态匹配和验证目标,从而提高导航的准确性和鲁棒性。这样设计的目的是为了克服传统方法在处理多模态、开放词汇和多目标任务时的局限性。
技术框架:LagMemo的整体框架包含以下几个主要模块:1) 3D语言记忆构建:在探索阶段,系统利用视觉和语言信息构建一个3D高斯溅射场景表示,其中每个高斯粒子都关联着语言描述。2) 目标定位:给定任务目标(例如,文本描述),系统查询3D语言记忆,预测候选目标位置。3) 局部感知验证:在导航过程中,系统利用局部感知信息(例如,视觉特征)验证候选目标位置,并动态调整导航策略。4) 导航控制:基于目标定位和局部感知验证的结果,系统控制机器人导航到目标位置。
关键创新:LagMemo的关键创新在于将语言信息融入到3D高斯溅射场景表示中,从而实现多模态开放词汇目标定位。与传统的基于地图的导航方法相比,LagMemo能够更好地处理语义信息,并根据语言描述找到目标。此外,LagMemo的局部感知验证机制能够提高导航的鲁棒性,减少定位误差。
关键设计:LagMemo的关键设计包括:1) 语言嵌入:使用预训练的语言模型(例如,CLIP)将文本描述嵌入到高维向量空间中。2) 3D高斯溅射表示:使用3D高斯溅射表示场景几何和外观信息,并为每个高斯粒子关联语言嵌入。3) 目标定位损失:设计损失函数,鼓励系统学习将目标描述映射到正确的3D位置。4) 局部感知验证网络:训练一个神经网络,用于根据局部视觉信息验证候选目标位置。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LagMemo在多目标视觉导航任务中优于现有方法。例如,在GOAT-Core基准测试中,LagMemo的成功率比最先进的方法提高了显著百分比(具体数值未知,原文未提供)。此外,实验还验证了LagMemo的记忆模块能够实现有效的多模态开放词汇目标定位。
🎯 应用场景
LagMemo具有广泛的应用前景,例如在家庭服务机器人中,用户可以通过语音或文本指令引导机器人完成各种任务,如“去客厅的沙发上拿遥控器”。在仓储物流领域,机器人可以根据文本描述找到特定的货物。此外,该技术还可以应用于自动驾驶、增强现实等领域,提升人机交互的智能化水平。
📄 摘要(原文)
Navigating to a designated goal using visual information is a fundamental capability for intelligent robots. Most classical visual navigation methods are restricted to single-goal, single-modality, and closed set goal settings. To address the practical demands of multi-modal, open-vocabulary goal queries and multi-goal visual navigation, we propose LagMemo, a navigation system that leverages a language 3D Gaussian Splatting memory. During exploration, LagMemo constructs a unified 3D language memory. With incoming task goals, the system queries the memory, predicts candidate goal locations, and integrates a local perception-based verification mechanism to dynamically match and validate goals during navigation. For fair and rigorous evaluation, we curate GOAT-Core, a high-quality core split distilled from GOAT-Bench tailored to multi-modal open-vocabulary multi-goal visual navigation. Experimental results show that LagMemo's memory module enables effective multi-modal open-vocabulary goal localization, and that LagMemo outperforms state-of-the-art methods in multi-goal visual navigation. Project page: https://weekgoodday.github.io/lagmemo