PFEA: An LLM-based High-Level Natural Language Planning and Feedback Embodied Agent for Human-Centered AI
作者: Wenbin Ding, Jun Chen, Mingjia Chen, Fei Xie, Qi Mao, Philip Dames
分类: cs.RO
发布日期: 2025-10-28
💡 一句话要点
PFEA:一种基于LLM的自然语言规划与反馈具身智能体,用于以人为本的AI
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能体 自然语言规划 视觉-语言模型 人机交互 任务规划
📋 核心要点
- 现有基于LLM的具身智能体难以在线规划和执行复杂的自然语言控制任务,限制了其在人机交互中的应用。
- 提出PFEA框架,包含语音交互、视觉-语言智能体和动作执行模块,实现更高效的自然语言任务规划与执行。
- 实验表明,PFEA在模拟和真实环境中,任务成功率比LLM+CLIP方法平均提高28%,显著提升了执行效果。
📝 摘要(中文)
大型语言模型(LLM)的快速发展标志着人工智能(AI)的重大突破,开创了以人为本的人工智能(HAI)的新时代。HAI旨在更好地服务于人类的福祉和需求,从而对机器人的智能水平提出了更高的要求,特别是在自然语言交互、复杂任务规划和执行等方面。由LLM驱动的智能体为实现HAI开辟了新的途径。然而,现有的基于LLM的具身智能体通常缺乏在线规划和执行复杂自然语言控制任务的能力。本文探讨了基于视觉-语言模型(VLM)的智能机器人操作智能体在物理世界中的实现。我们提出了一种新颖的机器人具身智能体框架,该框架包括人机语音交互模块、视觉-语言智能体模块和动作执行模块。视觉-语言智能体本身包括基于视觉的任务规划器、自然语言指令转换器和任务性能反馈评估器。实验结果表明,与仅依赖LLM+CLIP的方法相比,我们的智能体在模拟和真实环境中都实现了平均任务成功率提高28%,显著提高了高级自然语言指令任务的执行成功率。
🔬 方法详解
问题定义:现有基于大型语言模型(LLM)的具身智能体在处理复杂自然语言指令时,缺乏有效的在线规划和反馈机制,导致任务执行成功率较低。尤其是在真实物理环境中,由于感知噪声和动作不确定性,直接依赖LLM进行端到端控制往往难以达到理想效果。因此,如何提升具身智能体在复杂自然语言环境下的任务执行能力是一个关键问题。
核心思路:论文的核心思路是将复杂的自然语言任务分解为可执行的子任务序列,并引入视觉反馈机制来评估任务执行的中间状态,从而实现更鲁棒的任务规划和执行。通过结合视觉信息和语言理解,智能体可以更好地理解环境,并根据实际情况调整执行策略。这种分解和反馈的结合使得智能体能够更好地适应真实世界的复杂性和不确定性。
技术框架:PFEA框架主要包含三个模块:人机语音交互模块、视觉-语言智能体模块和动作执行模块。人机语音交互模块负责接收用户的自然语言指令。视觉-语言智能体模块是核心,它包含基于视觉的任务规划器、自然语言指令转换器和任务性能反馈评估器。任务规划器根据视觉信息和语言指令生成任务执行计划。指令转换器将高层指令转换为低层动作指令。反馈评估器根据视觉信息评估任务执行状态,并提供反馈信号。动作执行模块负责执行具体的机器人动作。
关键创新:该论文的关键创新在于提出了一个集成了视觉信息、自然语言理解和反馈机制的具身智能体框架。与传统的仅依赖LLM的端到端方法相比,PFEA框架通过显式的任务规划和反馈评估,提高了任务执行的鲁棒性和成功率。此外,该框架还能够处理更复杂的自然语言指令,并根据环境变化动态调整执行策略。
关键设计:在视觉-语言智能体模块中,任务规划器使用视觉信息来识别环境中的物体和状态,并结合自然语言指令生成任务执行计划。指令转换器使用预训练的语言模型将高层指令转换为低层动作指令。反馈评估器使用视觉信息来评估任务执行状态,并生成反馈信号,用于调整任务执行计划。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述。
🖼️ 关键图片
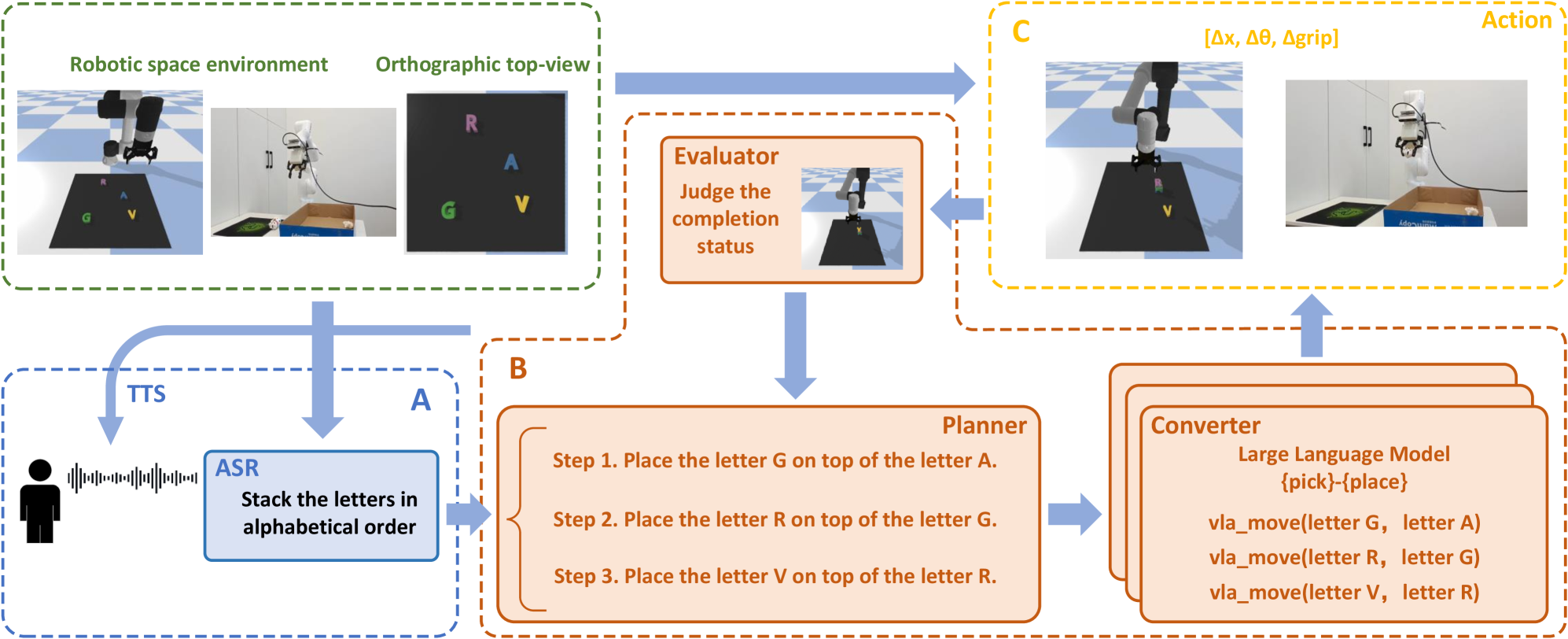


📊 实验亮点
实验结果表明,PFEA框架在模拟和真实环境中均取得了显著的性能提升。与仅依赖LLM+CLIP的方法相比,PFEA框架的任务成功率平均提高了28%。这表明PFEA框架在处理复杂自然语言指令任务时具有更强的鲁棒性和适应性。此外,实验还验证了PFEA框架在不同环境和任务下的泛化能力。
🎯 应用场景
该研究成果可广泛应用于家庭服务机器人、工业自动化、医疗辅助机器人等领域。例如,家庭服务机器人可以根据用户的自然语言指令完成复杂的家务任务,工业自动化机器人可以根据生产需求灵活调整生产流程,医疗辅助机器人可以协助医生进行手术操作。该研究有助于提升人机协作的效率和智能化水平,推动人工智能在实际生活中的应用。
📄 摘要(原文)
The rapid advancement of Large Language Models (LLMs) has marked a significant breakthrough in Artificial Intelligence (AI), ushering in a new era of Human-centered Artificial Intelligence (HAI). HAI aims to better serve human welfare and needs, thereby placing higher demands on the intelligence level of robots, particularly in aspects such as natural language interaction, complex task planning, and execution. Intelligent agents powered by LLMs have opened up new pathways for realizing HAI. However, existing LLM-based embodied agents often lack the ability to plan and execute complex natural language control tasks online. This paper explores the implementation of intelligent robotic manipulating agents based on Vision-Language Models (VLMs) in the physical world. We propose a novel embodied agent framework for robots, which comprises a human-robot voice interaction module, a vision-language agent module and an action execution module. The vision-language agent itself includes a vision-based task planner, a natural language instruction converter, and a task performance feedback evaluator. Experimental results demonstrate that our agent achieves a 28\% higher average task success rate in both simulated and real environments compared to approaches relying solely on LLM+CLIP, significantly improving the execution success rate of high-level natural language instruction tasks.