Language-Conditioned Representations and Mixture-of-Experts Policy for Robust Multi-Task Robotic Manipulation
作者: Xiucheng Zhang, Yang Jiang, Hongwei Qing, Jiashuo Bai
分类: cs.RO, cs.LG
发布日期: 2025-10-28
备注: 8 pages
💡 一句话要点
提出LCVR和LMoE-DP框架,提升多任务机器人操作的鲁棒性和效率
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多任务学习 机器人操作 模仿学习 语言条件 混合专家模型
📋 核心要点
- 多任务机器人操作面临感知模糊和任务冲突的挑战,现有模仿学习方法难以有效处理。
- 论文提出LCVR和LMoE-DP框架,利用语言指令消除歧义,并使用专家模型处理不同的动作分布。
- 实验表明,该框架在真实机器人任务中显著提升了成功率,优于现有先进基线方法。
📝 摘要(中文)
本文提出了一种结合语言条件视觉表征(LCVR)模块和语言条件混合专家密度策略(LMoE-DP)的框架,用于解决模仿学习中多任务机器人操作的感知模糊和任务冲突问题。LCVR通过将视觉特征与语言指令对齐,消除了感知歧义,从而区分视觉上相似的任务。为了缓解任务冲突,LMoE-DP采用稀疏专家架构来专门处理不同的多模态动作分布,并通过梯度调制进行稳定。在真实机器人基准测试中,LCVR分别将带有Transformer的动作分块(ACT)和扩散策略(DP)的成功率提高了33.75%和25%。完整的框架实现了79%的平均成功率,比先进的基线高出21%。该研究表明,结合语义对齐和专家专业化能够实现鲁棒、高效的多任务操作。
🔬 方法详解
问题定义:多任务机器人操作中,由于感知模糊(例如,视觉上相似但语义不同的任务)和任务冲突(不同任务需要不同的动作策略)的存在,传统的模仿学习方法难以取得良好的效果。现有的方法通常难以区分视觉上相似的任务,并且在学习多种动作策略时容易发生冲突,导致性能下降。
核心思路:论文的核心思路是利用语言指令作为额外的语义信息来消除感知歧义,并使用混合专家模型来专门处理不同的动作策略。通过将视觉信息与语言指令对齐,模型可以更好地区分不同的任务。同时,混合专家模型可以学习到不同的动作分布,从而缓解任务冲突。
技术框架:该框架主要包含两个模块:语言条件视觉表征(LCVR)模块和语言条件混合专家密度策略(LMoE-DP)模块。LCVR模块负责将视觉特征与语言指令对齐,生成语言条件下的视觉表征。LMoE-DP模块则利用这些表征来学习动作策略,其中混合专家模型用于处理不同的动作分布。整个框架的流程是:首先,输入视觉信息和语言指令;然后,LCVR模块生成语言条件下的视觉表征;最后,LMoE-DP模块根据这些表征生成动作。
关键创新:该论文的关键创新在于将语言信息融入到视觉表征中,从而消除了感知歧义。此外,使用混合专家模型来处理不同的动作分布也是一个重要的创新点。与现有方法相比,该方法能够更好地区分视觉上相似的任务,并且能够更有效地学习多种动作策略。
关键设计:LCVR模块的具体实现方式未知,但其核心思想是将视觉特征与语言指令对齐。LMoE-DP模块使用稀疏专家架构,每个专家负责处理特定的动作分布。梯度调制用于稳定训练过程。具体的损失函数和网络结构细节未知。
🖼️ 关键图片
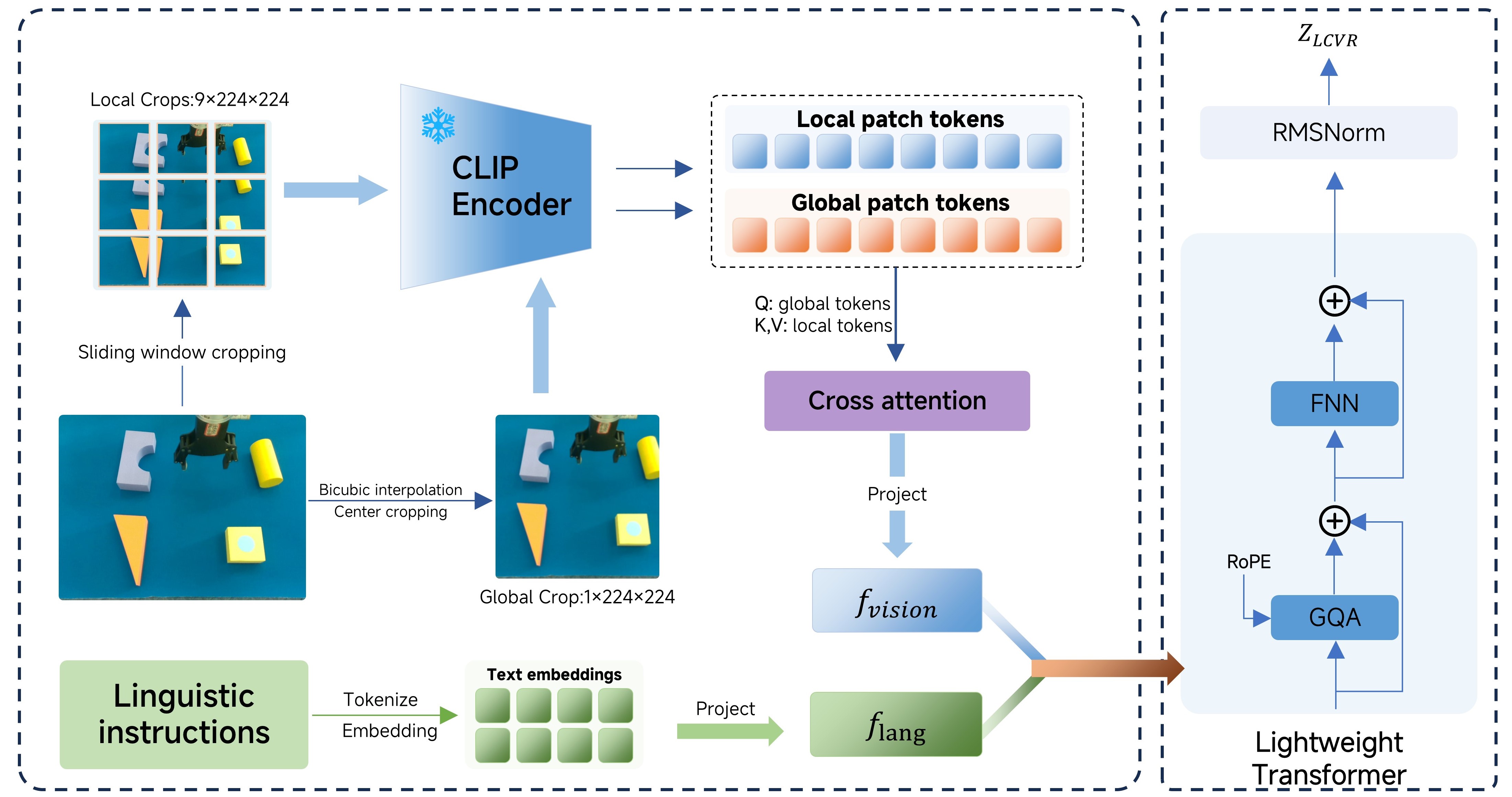
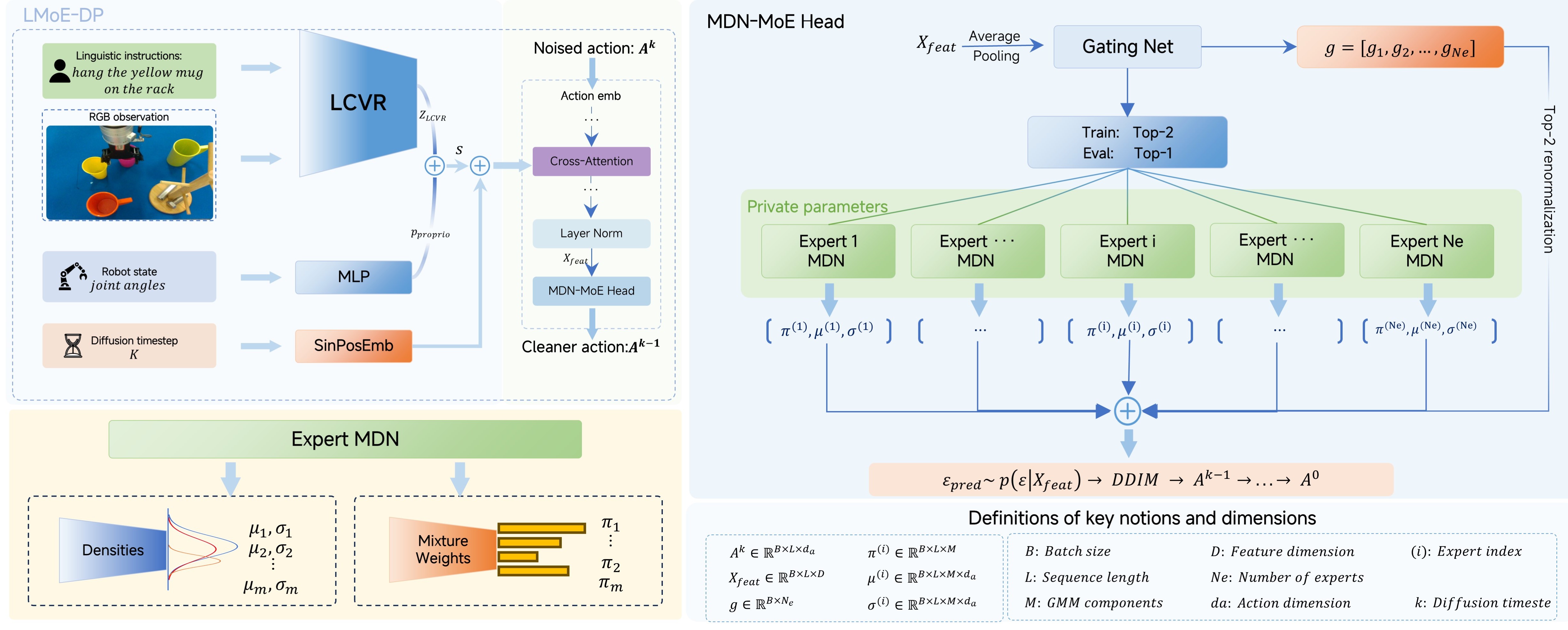

📊 实验亮点
实验结果表明,LCVR模块分别将ACT和DP的成功率提高了33.75%和25%。完整的框架实现了79%的平均成功率,比先进的基线高出21%。这些数据表明,该框架在多任务机器人操作方面具有显著的优势,能够有效地解决感知模糊和任务冲突问题。
🎯 应用场景
该研究成果可应用于各种需要多任务机器人操作的场景,例如智能制造、家庭服务、医疗辅助等。通过提升机器人的操作鲁棒性和效率,可以实现更智能、更灵活的自动化解决方案,从而提高生产效率和服务质量。未来,该技术有望进一步扩展到更复杂的机器人任务和环境。
📄 摘要(原文)
Perceptual ambiguity and task conflict limit multitask robotic manipulation via imitation learning. We propose a framework combining a Language-Conditioned Visual Representation (LCVR) module and a Language-conditioned Mixture-ofExperts Density Policy (LMoE-DP). LCVR resolves perceptual ambiguities by grounding visual features with language instructions, enabling differentiation between visually similar tasks. To mitigate task conflict, LMoE-DP uses a sparse expert architecture to specialize in distinct, multimodal action distributions, stabilized by gradient modulation. On real-robot benchmarks, LCVR boosts Action Chunking with Transformers (ACT) and Diffusion Policy (DP) success rates by 33.75% and 25%, respectively. The full framework achieves a 79% average success, outperforming the advanced baseline by 21%. Our work shows that combining semantic grounding and expert specialization enables robust, efficient multi-task manipulation