VOCALoco: Viability-Optimized Cost-aware Adaptive Locomotion
作者: Stanley Wu, Mohamad H. Danesh, Simon Li, Hanna Yurchyk, Amin Abyaneh, Anas El Houssaini, David Meger, Hsiu-Chin Lin
分类: cs.RO
发布日期: 2025-10-28
备注: Accepted in IEEE Robotics and Automation Letters (RAL), 2025. 8 pages, 9 figures
期刊: IEEE Robotics and Automation Letters, 2025
💡 一句话要点
VOCALoco:面向四足机器人,提出可行性优化和成本感知的自适应步态选择框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 步态选择 可行性优化 成本感知 自适应运动 深度强化学习 机器人控制
📋 核心要点
- 现有的腿式机器人运动方法依赖端到端深度强化学习,在安全性和可解释性方面存在局限性,尤其是在推广到新地形时。
- VOCALoco通过评估预训练运动策略的可行性和能耗,动态选择安全且节能的步态,从而适应不同的地形。
- 在楼梯运动任务中,VOCALoco在模拟和真实环境中均表现出优于传统端到端DRL策略的鲁棒性和安全性。
📝 摘要(中文)
本文提出了一种名为VOCALoco的模块化技能选择框架,用于动态调整腿式机器人的运动策略,使其能够适应不同的地形。与依赖端到端深度强化学习(DRL)的现有方法不同,VOCALoco通过预测执行的安全性和在固定规划范围内的预期运输成本,来评估预训练的运动策略的可行性和能耗。这种联合评估使得能够选择既安全又节能的策略,从而适应观察到的局部地形。我们在楼梯运动任务中评估了我们的方法,并在四足机器人的模拟和真实场景中展示了其性能。实验结果表明,与传统的端到端DRL策略相比,VOCALoco在楼梯上升和下降过程中实现了更高的鲁棒性和安全性。
🔬 方法详解
问题定义:现有基于端到端深度强化学习的腿式机器人运动控制方法,在泛化到新地形时存在安全性和可解释性问题。尤其是在复杂地形(如楼梯)上,难以保证运动过程的安全性,且策略的决策过程难以理解和调试。
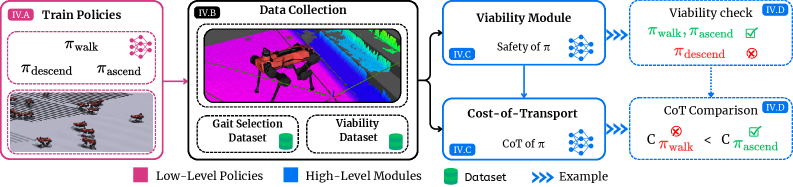
核心思路:VOCALoco的核心思路是将运动控制问题分解为步态选择和步态执行两个模块。通过预训练多个不同的步态策略,并根据当前环境信息(例如地形高度图)预测每个步态策略的安全性(可行性)和能耗(成本),然后选择一个既安全又节能的步态策略执行。
技术框架:VOCALoco框架包含以下几个主要模块:1) 感知模块:从传感器获取环境信息,例如地形高度图。2) 步态库:包含多个预训练的步态策略,每个策略对应一种特定的运动模式。3) 可行性预测模块:预测每个步态策略在当前环境下的执行安全性。4) 成本预测模块:预测每个步态策略在当前环境下的能耗。5) 步态选择模块:根据可行性和成本预测结果,选择一个最优的步态策略执行。6) 步态执行模块:执行选定的步态策略,控制机器人运动。
关键创新:VOCALoco的关键创新在于将运动控制问题分解为步态选择和步态执行两个模块,并引入了可行性和成本预测机制。这种模块化的设计提高了系统的可解释性和鲁棒性,使其能够更好地适应不同的地形。与端到端深度强化学习方法相比,VOCALoco不需要从头开始训练策略,而是可以利用预训练的步态库,从而降低了训练成本和风险。
关键设计:可行性预测模块和成本预测模块是VOCALoco的关键组成部分。可行性预测模块可以使用分类器或回归器来预测步态策略的安全性,例如预测机器人是否会摔倒。成本预测模块可以使用回归器来预测步态策略的能耗,例如预测机器人的电机功率消耗。步态选择模块可以使用加权和或多目标优化等方法,根据可行性和成本预测结果选择最优的步态策略。具体参数设置和网络结构在论文中可能包含更详细的描述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在楼梯攀爬任务中,VOCALoco相较于传统的端到端深度强化学习方法,在安全性和鲁棒性方面有显著提升。具体而言,VOCALoco能够更有效地避免机器人摔倒,并降低能量消耗。论文在模拟和真实机器人平台上验证了该方法的有效性。
🎯 应用场景
VOCALoco框架可应用于各种腿式机器人,使其能够在复杂地形(如楼梯、崎岖地面、障碍物)上安全高效地运动。该技术在搜索救援、物流运输、巡检维护等领域具有广泛的应用前景,能够提升机器人在非结构化环境中的自主作业能力,降低人工干预的需求。
📄 摘要(原文)
Recent advancements in legged robot locomotion have facilitated traversal over increasingly complex terrains. Despite this progress, many existing approaches rely on end-to-end deep reinforcement learning (DRL), which poses limitations in terms of safety and interpretability, especially when generalizing to novel terrains. To overcome these challenges, we introduce VOCALoco, a modular skill-selection framework that dynamically adapts locomotion strategies based on perceptual input. Given a set of pre-trained locomotion policies, VOCALoco evaluates their viability and energy-consumption by predicting both the safety of execution and the anticipated cost of transport over a fixed planning horizon. This joint assessment enables the selection of policies that are both safe and energy-efficient, given the observed local terrain. We evaluate our approach on staircase locomotion tasks, demonstrating its performance in both simulated and real-world scenarios using a quadrupedal robot. Empirical results show that VOCALoco achieves improved robustness and safety during stair ascent and descent compared to a conventional end-to-end DRL policy