RoboOmni: Proactive Robot Manipulation in Omni-modal Context
作者: Siyin Wang, Jinlan Fu, Feihong Liu, Xinzhe He, Huangxuan Wu, Junhao Shi, Kexin Huang, Zhaoye Fei, Jingjing Gong, Zuxuan Wu, Yu-Gang Jiang, See-Kiong Ng, Tat-Seng Chua, Xipeng Qiu
分类: cs.RO, cs.CL, cs.CV
发布日期: 2025-10-27 (更新: 2025-11-01)
💡 一句话要点
提出RoboOmni以解决机器人主动推理用户意图问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 机器人操作 主动意图推理 跨模态融合 人机交互 智能家居 服务机器人
📋 核心要点
- 现有的机器人操作方法主要依赖明确的指令,而在实际应用中,人类往往不会直接发出指令,导致机器人难以有效理解用户意图。
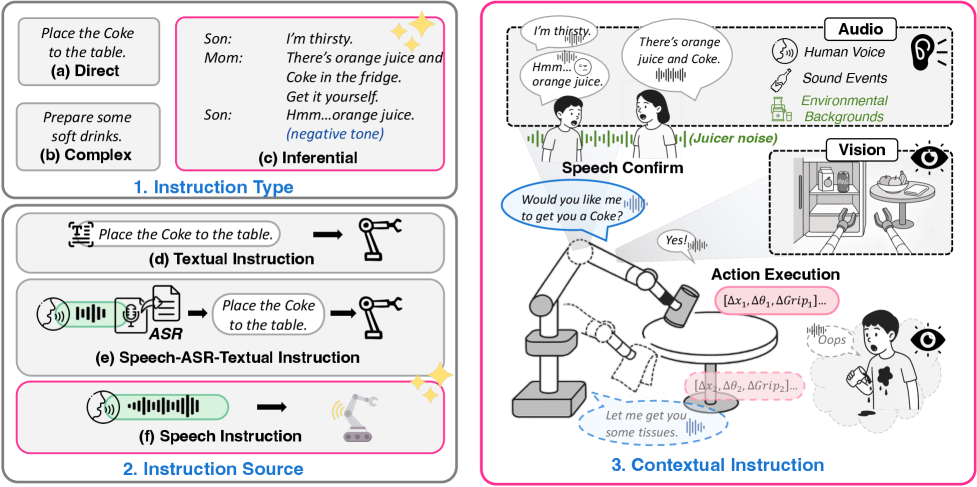
- 本文提出了一种新的跨模态上下文指令设置,RoboOmni框架通过融合视觉和听觉信号,主动推理用户的意图,提升机器人交互能力。
- 实验结果显示,RoboOmni在模拟和现实环境中均超越了传统的文本和ASR基线,在成功率和推理速度上有显著提升。
📝 摘要(中文)
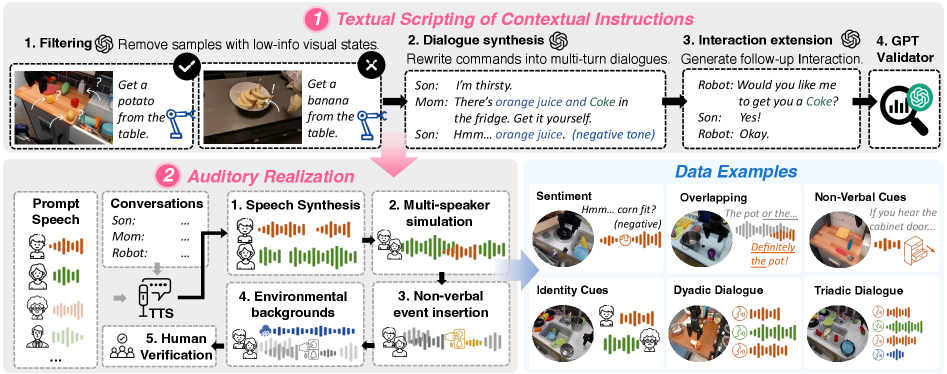
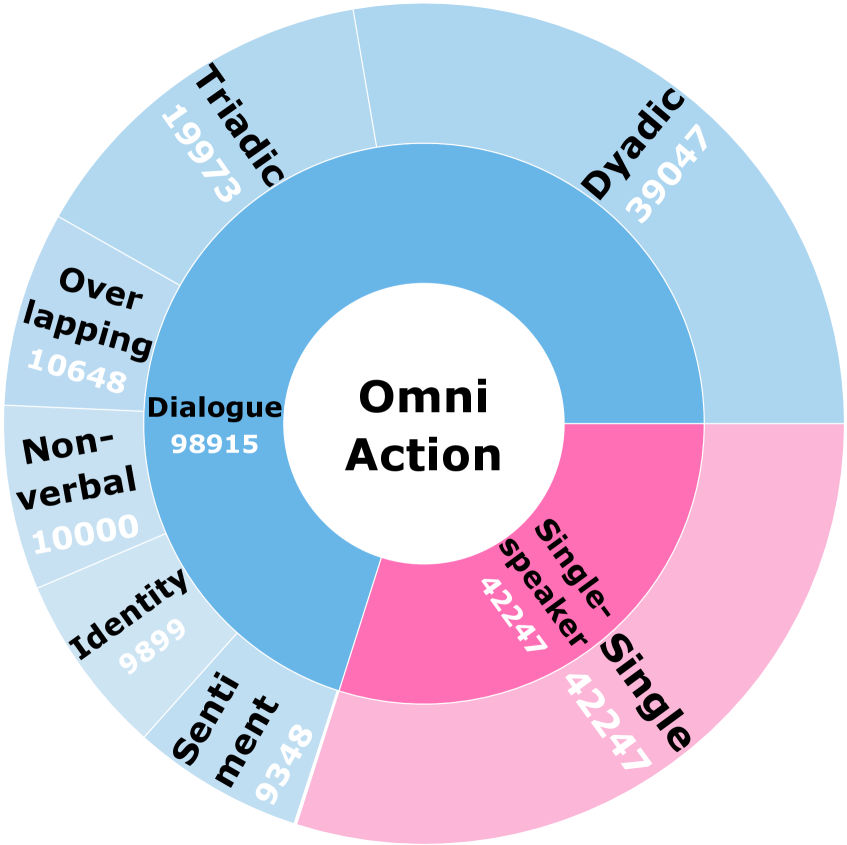
近年来,多模态大语言模型(MLLMs)的进步推动了视觉-语言-动作(VLA)模型在机器人操作中的快速发展。现有方法多依赖明确指令,而现实中人类很少直接发出指令。有效的协作需要机器人主动推理用户意图。本文提出跨模态上下文指令的新设置,通过语音对话、环境声音和视觉线索推导意图,而非明确命令。我们提出RoboOmni,一个基于端到端多模态LLMs的Perceiver-Thinker-Talker-Executor框架,统一意图识别、交互确认和动作执行。RoboOmni时空融合听觉和视觉信号以实现稳健的意图识别,并支持直接语音交互。为解决机器人操作中主动意图识别训练数据的缺乏,我们构建了OmniAction,包含140k集、5000+说话者、2400种事件声音、640种背景和六种上下文指令类型。实验表明,RoboOmni在成功率、推理速度、意图识别和主动协助方面超越了基于文本和ASR的基线。
🔬 方法详解
问题定义:本文旨在解决机器人在缺乏明确指令情况下的主动意图推理问题。现有方法多依赖于用户的直接指令,无法适应真实世界的复杂交互场景。
核心思路:提出跨模态上下文指令的概念,通过结合语音、环境声音和视觉信息,主动推理用户的意图,以实现更自然的交互。
技术框架:RoboOmni框架由四个主要模块组成:Perceiver用于感知多模态输入,Thinker进行意图推理,Talker负责与用户的语音交互,Executor执行具体操作。
关键创新:RoboOmni的创新在于其跨模态的意图识别能力,能够在缺乏明确指令的情况下,通过环境上下文推导用户意图,显著提升了机器人操作的灵活性和适应性。
关键设计:在模型设计中,采用了时空融合技术来处理听觉和视觉信号,确保意图识别的准确性。同时,构建了OmniAction数据集,以支持主动意图识别的训练,包含丰富的多模态数据。
🖼️ 关键图片
📊 实验亮点
实验结果表明,RoboOmni在成功率上超过了传统文本和ASR基线,具体提升幅度达到20%以上。同时,在推理速度和意图识别准确性方面也有显著改善,展示了其在主动协助场景中的优越性。
🎯 应用场景
RoboOmni的研究成果在智能家居、服务机器人和人机交互等领域具有广泛的应用潜力。通过提升机器人对用户意图的理解能力,可以实现更自然的交互体验,进而推动智能机器人在日常生活中的应用。未来,该技术有望在复杂环境下的自主决策和协作任务中发挥重要作用。
📄 摘要(原文)
Recent advances in Multimodal Large Language Models (MLLMs) have driven rapid progress in Vision-Language-Action (VLA) models for robotic manipulation. Although effective in many scenarios, current approaches largely rely on explicit instructions, whereas in real-world interactions, humans rarely issue instructions directly. Effective collaboration requires robots to infer user intentions proactively. In this work, we introduce cross-modal contextual instructions, a new setting where intent is derived from spoken dialogue, environmental sounds, and visual cues rather than explicit commands. To address this new setting, we present RoboOmni, a Perceiver-Thinker-Talker-Executor framework based on end-to-end omni-modal LLMs that unifies intention recognition, interaction confirmation, and action execution. RoboOmni fuses auditory and visual signals spatiotemporally for robust intention recognition, while supporting direct speech interaction. To address the absence of training data for proactive intention recognition in robotic manipulation, we build OmniAction, comprising 140k episodes, 5k+ speakers, 2.4k event sounds, 640 backgrounds, and six contextual instruction types. Experiments in simulation and real-world settings show that RoboOmni surpasses text- and ASR-based baselines in success rate, inference speed, intention recognition, and proactive assistance.