UrbanVLA: A Vision-Language-Action Model for Urban Micromobility
作者: Anqi Li, Zhiyong Wang, Jiazhao Zhang, Minghan Li, Yunpeng Qi, Zhibo Chen, Zhizheng Zhang, He Wang
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-10-27
💡 一句话要点
提出UrbanVLA,用于城市微出行场景下基于视觉-语言-动作的导航。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 城市微出行 视觉-语言-动作模型 导航 路线规划 强化学习
📋 核心要点
- 现有导航方法难以应对城市微出行应用中大规模、动态和非结构化的真实环境。
- UrbanVLA通过路线条件下的视觉-语言-动作框架,显式对齐路线航点与视觉观测,规划轨迹。
- UrbanVLA在MetaUrban的SocialNav任务中超越了基线55%以上,并在真实世界导航中表现出鲁棒性。
📝 摘要(中文)
本文提出UrbanVLA,一个基于视觉-语言-动作(VLA)的框架,专为可扩展的城市导航设计,适用于城市微出行应用,如配送机器人。该方法在执行过程中显式地将带噪声的路线航点与视觉观测对齐,并规划轨迹以驱动机器人。为了使UrbanVLA掌握低级(如点目标到达和避障)和高级(如路线-视觉对齐)导航技能,采用了两阶段训练流程:首先使用模拟环境和从网络视频解析的轨迹进行监督微调(SFT),然后使用模拟和真实世界数据的混合进行强化微调(RFT),以增强模型在真实环境中的安全性和适应性。实验表明,UrbanVLA在MetaUrban的SocialNav任务中超越了强大的基线55%以上,并实现了可靠的真实世界导航,展示了其在大型城市环境中的可扩展性和对真实世界不确定性的鲁棒性。
🔬 方法详解
问题定义:论文旨在解决城市微出行应用中,机器人需要在复杂、动态的城市环境中,根据长距离路线指令进行可靠导航的问题。现有方法通常针对短距离、可控场景设计,难以应对真实城市环境中的不确定性和大规模导航需求。现有方法缺乏有效的视觉-语言对齐机制,无法充分利用路线信息进行导航。
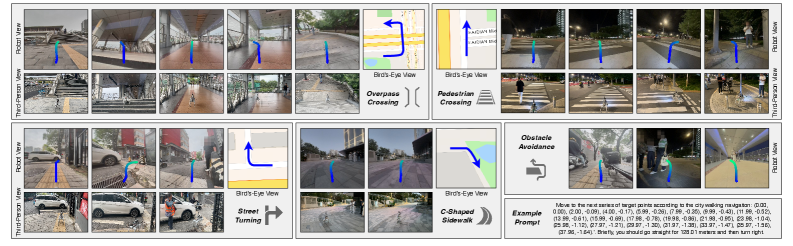
核心思路:论文的核心思路是构建一个路线条件下的视觉-语言-动作(VLA)模型,该模型能够将高层次的路线指令(语言)与低层次的视觉感知信息相结合,从而实现精确的导航控制(动作)。通过显式地将路线航点与视觉观测对齐,模型可以更好地理解环境,并规划出安全、高效的行驶轨迹。
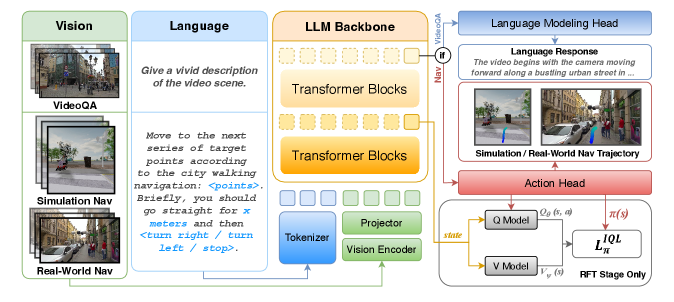
技术框架:UrbanVLA的整体框架包含以下几个主要模块:1) 视觉感知模块:用于从摄像头或其他传感器获取环境的视觉信息。2) 语言理解模块:用于解析路线指令,提取关键的航点信息。3) 视觉-语言对齐模块:将视觉信息和路线信息进行对齐,确定机器人在环境中的位置和方向。4) 轨迹规划模块:根据对齐后的信息,规划出一条安全、高效的行驶轨迹。5) 动作执行模块:控制机器人按照规划的轨迹行驶。训练过程分为两个阶段:监督微调(SFT)和强化微调(RFT)。
关键创新:UrbanVLA的关键创新在于其显式的视觉-语言对齐机制。与以往的方法不同,UrbanVLA不是简单地将视觉信息和路线信息进行拼接,而是通过学习一个对齐模型,将两者进行精确的匹配。这种对齐机制使得模型能够更好地理解环境,并规划出更加合理的轨迹。此外,两阶段训练策略也至关重要,SFT阶段利用模拟数据和网络视频提供先验知识,RFT阶段则利用真实数据提升模型的鲁棒性。
关键设计:在视觉-语言对齐模块中,可能使用了注意力机制或其他相似性度量方法,来计算视觉特征和语言特征之间的相关性。损失函数可能包括轨迹预测损失、对齐损失等,用于约束模型的学习。在强化微调阶段,奖励函数的设计至关重要,需要综合考虑安全性、效率和目标达成率等因素。具体的网络结构细节(如卷积神经网络的层数、循环神经网络的类型等)未知,但可以推测使用了常见的深度学习模型。
🖼️ 关键图片
📊 实验亮点
UrbanVLA在MetaUrban的SocialNav任务中,相较于其他基线方法,性能提升超过55%。此外,UrbanVLA还在真实世界环境中进行了测试,验证了其在复杂、动态环境中的鲁棒性和可扩展性。这些实验结果表明,UrbanVLA在城市微出行导航领域具有显著优势。
🎯 应用场景
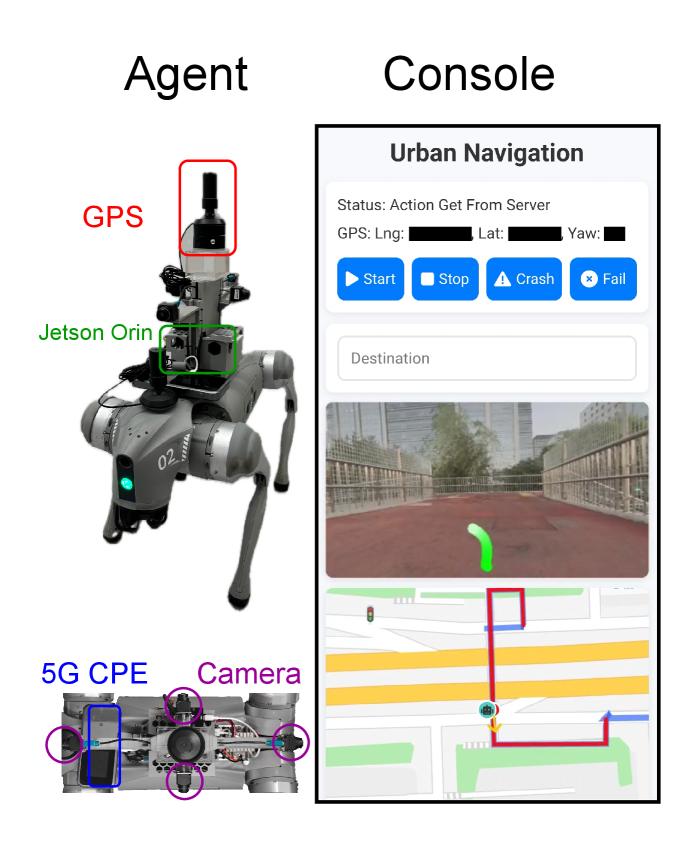
UrbanVLA具有广泛的应用前景,可用于城市配送机器人、自动驾驶车辆、无人巡检车等领域。该研究能够提升城市微出行设备的导航能力,使其能够在复杂的城市环境中安全、高效地运行。未来,该技术有望应用于智慧城市建设,提升城市交通效率,降低物流成本。
📄 摘要(原文)
Urban micromobility applications, such as delivery robots, demand reliable navigation across large-scale urban environments while following long-horizon route instructions. This task is particularly challenging due to the dynamic and unstructured nature of real-world city areas, yet most existing navigation methods remain tailored to short-scale and controllable scenarios. Effective urban micromobility requires two complementary levels of navigation skills: low-level capabilities such as point-goal reaching and obstacle avoidance, and high-level capabilities, such as route-visual alignment. To this end, we propose UrbanVLA, a route-conditioned Vision-Language-Action (VLA) framework designed for scalable urban navigation. Our method explicitly aligns noisy route waypoints with visual observations during execution, and subsequently plans trajectories to drive the robot. To enable UrbanVLA to master both levels of navigation, we employ a two-stage training pipeline. The process begins with Supervised Fine-Tuning (SFT) using simulated environments and trajectories parsed from web videos. This is followed by Reinforcement Fine-Tuning (RFT) on a mixture of simulation and real-world data, which enhances the model's safety and adaptability in real-world settings. Experiments demonstrate that UrbanVLA surpasses strong baselines by more than 55% in the SocialNav task on MetaUrban. Furthermore, UrbanVLA achieves reliable real-world navigation, showcasing both scalability to large-scale urban environments and robustness against real-world uncertainties.