Transferable Deep Reinforcement Learning for Cross-Domain Navigation: from Farmland to the Moon
作者: Shreya Santra, Thomas Robbins, Kazuya Yoshida
分类: cs.RO
发布日期: 2025-10-27
备注: 6 pages, 7 figures. Accepted at IEEE iSpaRo 2025
💡 一句话要点
提出基于DRL的跨域迁移导航方法,实现从农田到月球的零样本泛化
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 跨域迁移 自主导航 行星探测 近端策略优化
📋 核心要点
- 传统导航算法需要针对特定环境进行大量调整,限制了其在新环境中的应用。
- 利用DRL在源域(农田)训练导航策略,并直接迁移到目标域(月球)进行零样本测试。
- 实验表明,在农田训练的策略在月球环境中仍能保持较高的成功率,无需额外训练。
📝 摘要(中文)
本文研究了深度强化学习(DRL)策略在视觉和地形上截然不同的模拟环境中的泛化能力,旨在解决非结构化环境下的自主导航问题。该问题在田野和行星机器人领域至关重要,机器人需要在不确定条件下高效地到达目标并避开障碍物。传统的算法方法通常需要大量的特定环境调整,限制了其在新领域的扩展性。本文利用近端策略优化(PPO)算法,在农田环境中训练了一个农业漫游车的3D模拟器,使其能够实现目标导向的导航和避障。然后,在类似月球的模拟环境中评估学习到的策略,以评估其迁移性能。结果表明,在陆地条件下训练的策略保持了较高的有效性,在不需要额外训练和微调的情况下,在月球模拟中实现了接近50%的成功率。这突显了基于DRL的跨域策略迁移作为一种有前途的方法的潜力,可以为未来的行星探测任务开发适应性强且高效的自主导航,并最大限度地降低再训练成本。
🔬 方法详解
问题定义:论文旨在解决机器人跨领域自主导航的问题,即如何让机器人在一个环境中学习到的导航策略,能够直接应用到另一个视觉和地形完全不同的环境中。现有方法通常需要针对新环境进行大量的参数调整和重新训练,成本高昂且效率低下。
核心思路:论文的核心思路是利用深度强化学习(DRL)的泛化能力,通过在源域(农田)中训练一个鲁棒的导航策略,使其能够适应目标域(月球)的视觉和地形差异。这种方法避免了在目标域中进行昂贵的重新训练或微调,从而降低了部署成本。
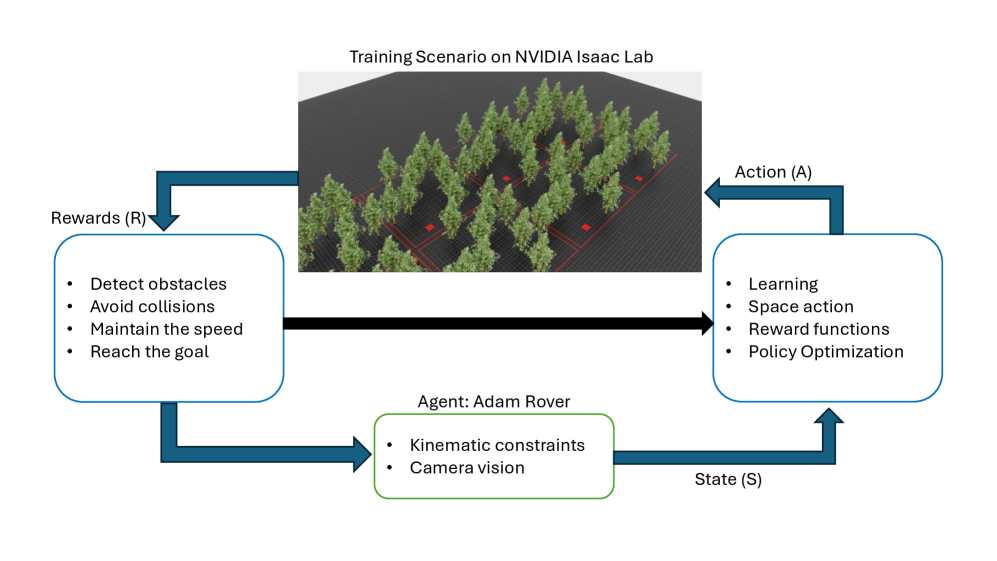
技术框架:整体框架包括两个主要部分:1) 在农田环境中构建一个3D模拟器,用于训练DRL策略。该模拟器需要模拟真实的农田环境,包括地形、植被、障碍物等。2) 在月球环境中构建一个3D模拟器,用于评估训练好的DRL策略的泛化能力。该模拟器需要模拟真实的月球环境,包括地形、光照、重力等。训练过程中,使用近端策略优化(PPO)算法来优化导航策略。
关键创新:论文的关键创新在于验证了DRL策略在视觉和地形差异巨大的环境中的零样本迁移能力。以往的DRL研究大多集中在同一环境或相似环境中的策略迁移,而本文则探索了在完全不同的环境中的策略迁移,这对于实际应用具有重要意义。
关键设计:论文使用PPO算法作为DRL训练算法,PPO是一种常用的策略梯度算法,具有较好的稳定性和收敛性。奖励函数的设计至关重要,需要平衡目标导向和避障两个目标。网络结构的选择也需要考虑计算效率和泛化能力。具体参数设置未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,在农田环境中训练的DRL策略,在未经任何调整的情况下,在月球模拟环境中实现了接近50%的导航成功率。这表明DRL策略具有较强的跨域泛化能力,为未来的行星探测任务提供了一种新的解决方案。具体的性能数据未知。
🎯 应用场景
该研究成果可应用于行星探测、农业机器人、搜救机器人等领域。通过在模拟环境中训练机器人,并将其导航策略迁移到真实环境中,可以降低开发成本和风险,提高机器人的自主导航能力。尤其是在资源有限或环境恶劣的场景下,该方法具有重要的应用价值。
📄 摘要(原文)
Autonomous navigation in unstructured environments is essential for field and planetary robotics, where robots must efficiently reach goals while avoiding obstacles under uncertain conditions. Conventional algorithmic approaches often require extensive environment-specific tuning, limiting scalability to new domains. Deep Reinforcement Learning (DRL) provides a data-driven alternative, allowing robots to acquire navigation strategies through direct interactions with their environment. This work investigates the feasibility of DRL policy generalization across visually and topographically distinct simulated domains, where policies are trained in terrestrial settings and validated in a zero-shot manner in extraterrestrial environments. A 3D simulation of an agricultural rover is developed and trained using Proximal Policy Optimization (PPO) to achieve goal-directed navigation and obstacle avoidance in farmland settings. The learned policy is then evaluated in a lunar-like simulated environment to assess transfer performance. The results indicate that policies trained under terrestrial conditions retain a high level of effectiveness, achieving close to 50\% success in lunar simulations without the need for additional training and fine-tuning. This underscores the potential of cross-domain DRL-based policy transfer as a promising approach to developing adaptable and efficient autonomous navigation for future planetary exploration missions, with the added benefit of minimizing retraining costs.