Policies over Poses: Reinforcement Learning based Distributed Pose-Graph Optimization for Multi-Robot SLAM
作者: Sai Krishna Ghanta, Ramviyas Parasuraman
分类: cs.RO, cs.AI, cs.MA
发布日期: 2025-10-26
备注: IEEE International Symposium on Multi-Robot & Multi-Agent Systems (MRS) 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于强化学习的分布式位姿图优化方法,用于多机器人SLAM。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多机器人SLAM 分布式位姿图优化 强化学习 图神经网络 多智能体系统
📋 核心要点
- 传统分布式位姿图优化方法易陷入局部最优,且计算效率较低,难以满足大规模多机器人SLAM的需求。
- 论文提出基于多智能体强化学习的分布式位姿图优化框架,通过学习策略优化局部位姿图,并使用共识方案保证全局一致性。
- 实验结果表明,该方法在全局目标优化和推理效率方面均优于现有方法,且具有良好的可扩展性。
📝 摘要(中文)
本文研究了分布式位姿图优化(PGO)问题,该问题对于多机器人同步定位与地图构建(SLAM)中精确轨迹估计至关重要。传统的迭代方法线性化高度非凸的优化目标,需要重复求解正规方程,这通常收敛到局部最小值,从而产生次优估计。我们提出了一种可扩展的、对异常值鲁棒的分布式平面PGO框架,该框架使用多智能体强化学习(MARL)。我们将分布式PGO建模为在局部位姿图上定义的部分可观察马尔可夫博弈,其中每个动作细化单个边的位姿估计。图划分器分解全局位姿图,每个机器人运行一个循环边条件图神经网络(GNN)编码器,该编码器具有自适应边门控以消除噪声边。机器人通过利用先前动作记忆和图嵌入的混合策略顺序地细化位姿。在局部图校正后,共识方案协调机器人间的差异,以产生全局一致的估计。我们在全面的合成和真实世界数据集上的广泛评估表明,我们学习的基于MARL的actor比最先进的分布式PGO框架平均降低了37.5%的全局目标,同时将推理效率提高了至少6倍。我们还证明了actor复制允许单个学习策略轻松扩展到更大的机器人团队,而无需任何重新训练。
🔬 方法详解
问题定义:论文旨在解决多机器人SLAM中的分布式位姿图优化问题。现有方法,如迭代最近点(ICP)等,通常需要线性化非凸优化目标,容易陷入局部最小值,导致轨迹估计不准确。此外,传统方法计算复杂度高,难以扩展到大规模机器人团队。
核心思路:论文的核心思路是将分布式位姿图优化问题建模为一个部分可观察马尔可夫博弈,利用多智能体强化学习(MARL)训练智能体,使其能够学习到一种策略,通过优化局部位姿图来提高全局位姿图的精度。通过学习,智能体能够更好地处理噪声和异常值,避免陷入局部最优。
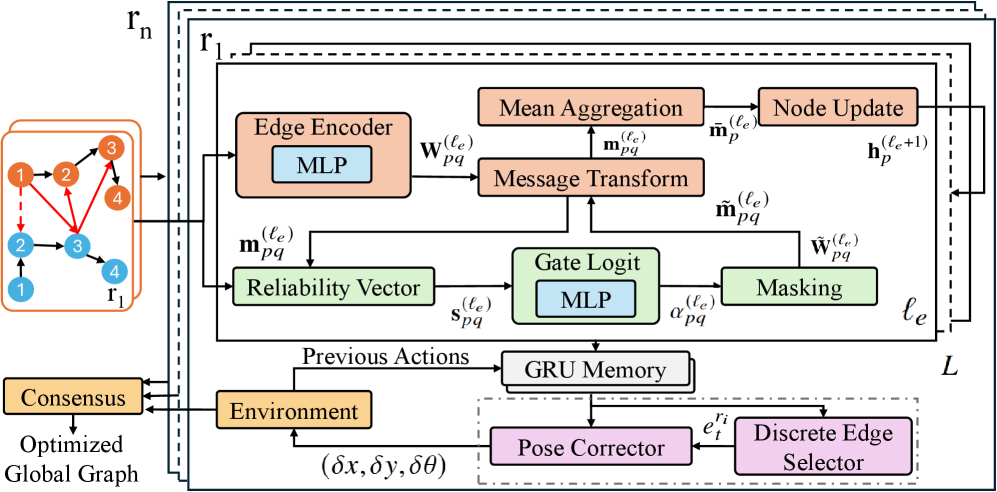
技术框架:整体框架包括以下几个主要模块:1) 图划分器:将全局位姿图分解为多个局部位姿图,分配给不同的机器人。2) 局部图优化:每个机器人运行一个循环边条件图神经网络(GNN)编码器,利用学习到的策略优化局部位姿图。GNN具有自适应边门控机制,用于消除噪声边。3) 共识方案:协调机器人之间的位姿估计差异,生成全局一致的位姿图。
关键创新:最重要的技术创新点在于使用多智能体强化学习来解决分布式位姿图优化问题。与传统方法相比,该方法能够学习到一种更鲁棒、更高效的优化策略,避免了手动设计优化算法的复杂性。此外,通过actor复制,该方法可以轻松扩展到更大的机器人团队,而无需重新训练。
关键设计:论文使用循环边条件图神经网络(GNN)作为智能体的编码器,GNN的输入是局部位姿图的边信息,输出是每个边的位姿调整量。GNN具有自适应边门控机制,用于根据边的置信度调整其权重。损失函数包括位姿误差和共识误差,用于训练智能体优化局部位姿图并与其他智能体达成一致。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在合成和真实世界数据集上均优于现有方法。与最先进的分布式PGO框架相比,该方法平均降低了37.5%的全局目标,同时将推理效率提高了至少6倍。此外,该方法具有良好的可扩展性,可以通过actor复制轻松扩展到更大的机器人团队,而无需重新训练。
🎯 应用场景
该研究成果可应用于多机器人协同探索、自主导航、环境监测等领域。通过提高多机器人SLAM的精度和效率,可以实现更可靠、更智能的机器人系统,例如在仓库管理、灾难救援、农业生产等场景中实现自动化作业。
📄 摘要(原文)
We consider the distributed pose-graph optimization (PGO) problem, which is fundamental in accurate trajectory estimation in multi-robot simultaneous localization and mapping (SLAM). Conventional iterative approaches linearize a highly non-convex optimization objective, requiring repeated solving of normal equations, which often converge to local minima and thus produce suboptimal estimates. We propose a scalable, outlier-robust distributed planar PGO framework using Multi-Agent Reinforcement Learning (MARL). We cast distributed PGO as a partially observable Markov game defined on local pose-graphs, where each action refines a single edge's pose estimate. A graph partitioner decomposes the global pose graph, and each robot runs a recurrent edge-conditioned Graph Neural Network (GNN) encoder with adaptive edge-gating to denoise noisy edges. Robots sequentially refine poses through a hybrid policy that utilizes prior action memory and graph embeddings. After local graph correction, a consensus scheme reconciles inter-robot disagreements to produce a globally consistent estimate. Our extensive evaluations on a comprehensive suite of synthetic and real-world datasets demonstrate that our learned MARL-based actors reduce the global objective by an average of 37.5% more than the state-of-the-art distributed PGO framework, while enhancing inference efficiency by at least 6X. We also demonstrate that actor replication allows a single learned policy to scale effortlessly to substantially larger robot teams without any retraining. Code is publicly available at https://github.com/herolab-uga/policies-over-poses.