Ant-inspired Walling Strategies for Scalable Swarm Separation: Reinforcement Learning Approaches Based on Finite State Machines
作者: Shenbagaraj Kannapiran, Elena Oikonomou, Albert Chu, Spring Berman, Theodore P. Pavlic
分类: cs.RO
发布日期: 2025-10-26
💡 一句话要点
受蚂蚁启发,提出基于有限状态机和强化学习的可扩展集群分离墙策略
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人集群 空间分离 有限状态机 深度强化学习 分散式控制
📋 核心要点
- 现有机器人集群控制方法难以在执行并发任务时维持有效的空间分离,导致任务干扰和效率降低。
- 论文提出一种受蚂蚁墙行为启发的策略,利用有限状态机和强化学习构建动态“墙”,实现集群间的有效分离。
- 仿真结果表明,该方法能显著减少集群间的混合,DQN增强的控制器在适应性和收敛速度方面表现更优,混合程度降低40-50%。
📝 摘要(中文)
本研究受军队蚂蚁形成临时“墙”以防止觅食路径干扰的启发,开发了两种用于异构机器人集群的分散式控制器,以在执行并发任务时保持空间分离。第一种是基于有限状态机(FSM)的控制器,它使用遭遇触发的转换来创建刚性、稳定的墙。第二种将FSM状态与深度Q网络(DQN)集成,通过涌现的“非军事区”动态优化分离。在仿真中,两种控制器都减少了子组之间的混合,其中DQN增强的控制器提高了适应性,减少了40-50%的混合,同时实现了更快的收敛。
🔬 方法详解
问题定义:论文旨在解决异构机器人集群在执行并发任务时,如何维持有效的空间分离,避免不同子群之间的相互干扰的问题。现有方法可能无法很好地适应动态环境,或者难以在计算资源有限的机器人上实现。
核心思路:论文的核心思路是模仿蚂蚁形成临时墙壁的行为,利用机器人构建动态的“墙”或“非军事区”,从而在空间上分隔不同的机器人子群。这种方法旨在实现分散式控制,使每个机器人仅根据局部信息做出决策。
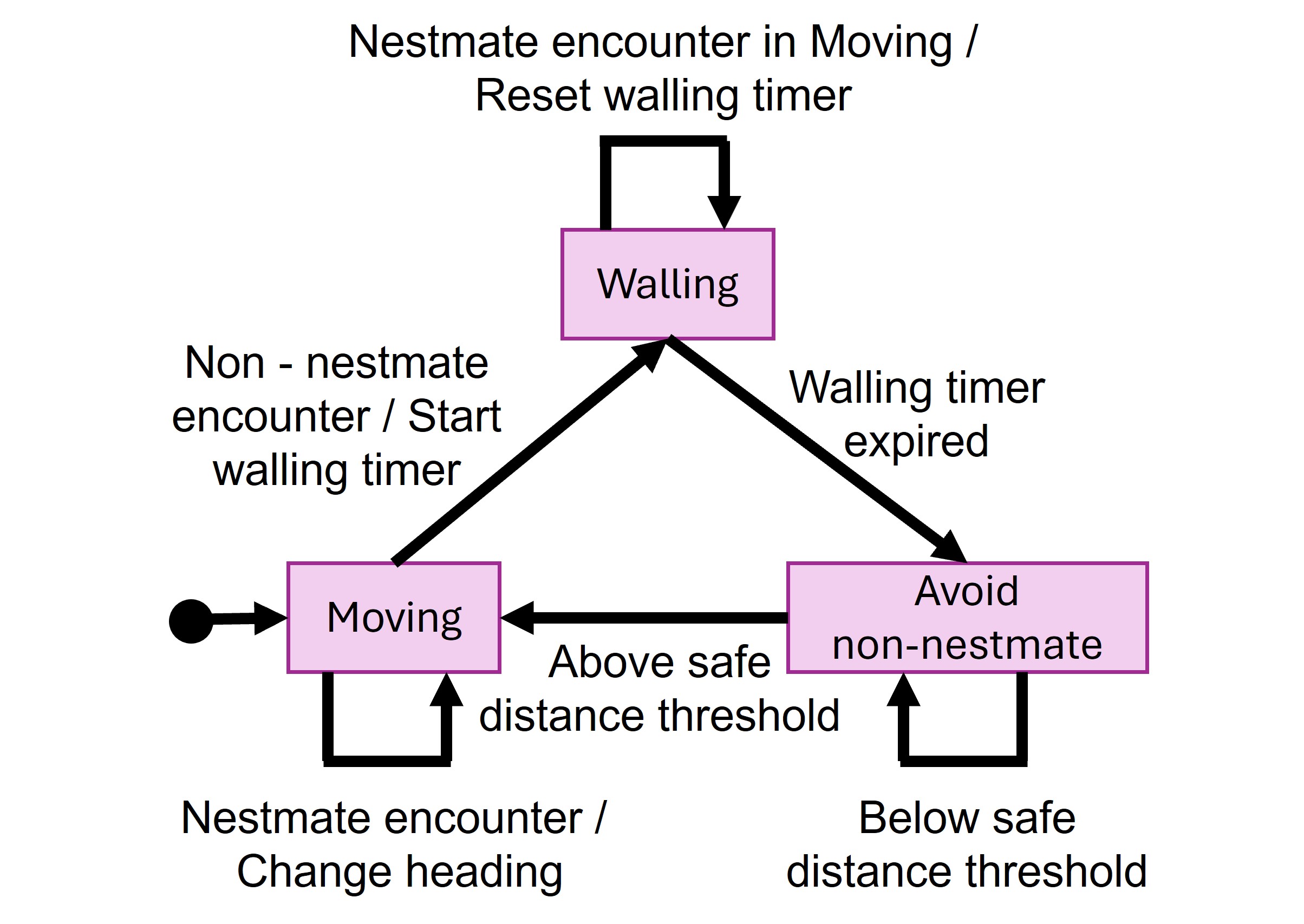
技术框架:整体框架包含两个主要控制器:1) 基于有限状态机(FSM)的控制器,该控制器定义了机器人的不同状态(如巡逻、筑墙等),并根据与其他机器人的遭遇触发状态转换。2) 集成FSM和深度Q网络(DQN)的控制器,DQN用于动态优化分离策略,通过学习奖励函数来调整机器人的行为。
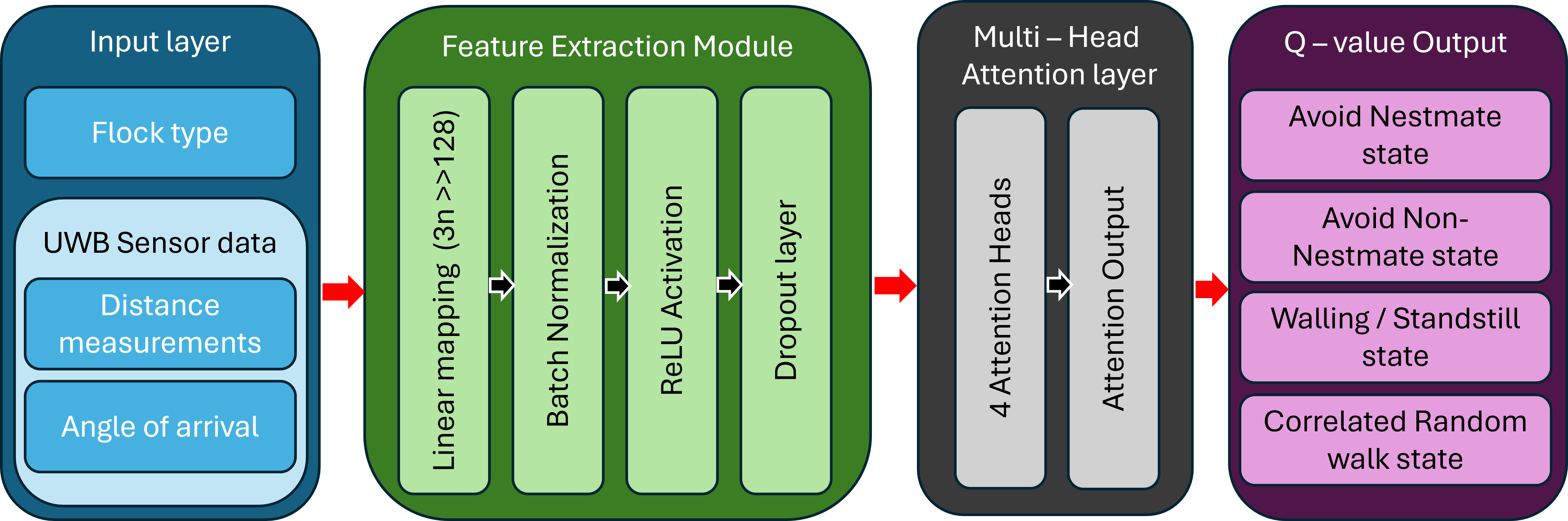
关键创新:最重要的技术创新在于将传统的有限状态机与深度强化学习相结合。FSM提供了一个基本的行为框架,而DQN则用于动态调整和优化这些行为,从而提高系统的适应性和鲁棒性。这种混合方法允许机器人在复杂环境中学习更有效的分离策略。
关键设计:FSM控制器中的关键设计包括状态的定义和状态转换的触发条件。DQN控制器的关键设计包括奖励函数的定义(鼓励分离,惩罚混合),以及网络结构的选择(例如,多层感知机),输入状态包括机器人之间的相对位置和速度等信息。DQN通过与环境的交互学习Q函数,从而指导机器人的行为。
🖼️ 关键图片

📊 实验亮点
仿真实验表明,两种控制器均能有效减少子群之间的混合。DQN增强的控制器表现出更强的适应性,能够动态调整分离策略。与仅使用FSM的控制器相比,DQN增强的控制器能够将集群间的混合程度降低40-50%,并实现更快的收敛速度,表明强化学习在优化集群分离策略方面的潜力。
🎯 应用场景
该研究成果可应用于多种需要集群协作和空间分离的场景,例如:多机器人协同搜索救援、仓库物流管理、农业机器人集群作业等。通过有效的分离策略,可以减少机器人之间的冲突和干扰,提高整体任务效率和安全性。未来的研究可以探索更复杂的环境和任务,以及将该方法应用于真实的机器人硬件平台。
📄 摘要(原文)
In natural systems, emergent structures often arise to balance competing demands. Army ants, for example, form temporary "walls" that prevent interference between foraging trails. Inspired by this behavior, we developed two decentralized controllers for heterogeneous robotic swarms to maintain spatial separation while executing concurrent tasks. The first is a finite-state machine (FSM)-based controller that uses encounter-triggered transitions to create rigid, stable walls. The second integrates FSM states with a Deep Q-Network (DQN), dynamically optimizing separation through emergent "demilitarized zones." In simulation, both controllers reduce mixing between subgroups, with the DQN-enhanced controller improving adaptability and reducing mixing by 40-50% while achieving faster convergence.