A Novel Multi-Timescale Stability-Preserving Hierarchical Reinforcement Learning Controller Framework for Adaptive Control in High-Dimensional Dynamical Systems
作者: Mohammad Ali Labbaf Khaniki, Fateme Taroodi, Benyamin Safizadeh
分类: cs.RO, eess.SY
发布日期: 2025-10-25
💡 一句话要点
提出多时间尺度Lyapunov约束分层强化学习框架,解决高维动态系统自适应控制问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分层强化学习 Lyapunov稳定性 多时间尺度控制 高维动态系统 自适应控制
📋 核心要点
- 高维随机系统控制面临维度灾难、缺乏时间抽象和难以保证随机稳定性的挑战。
- MTLHRL框架通过分层策略和Lyapunov约束,实现多时间尺度决策和稳定性保证。
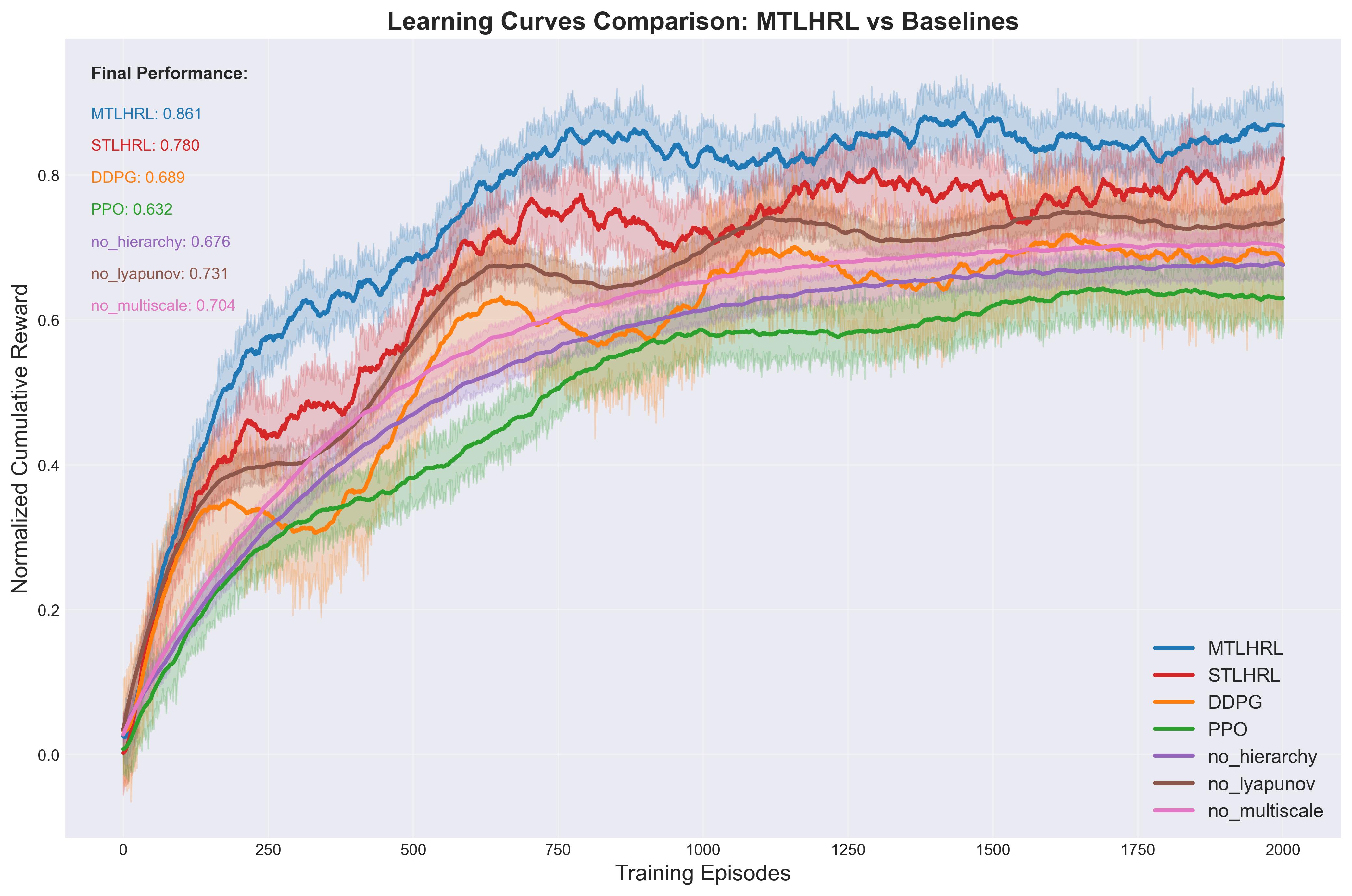
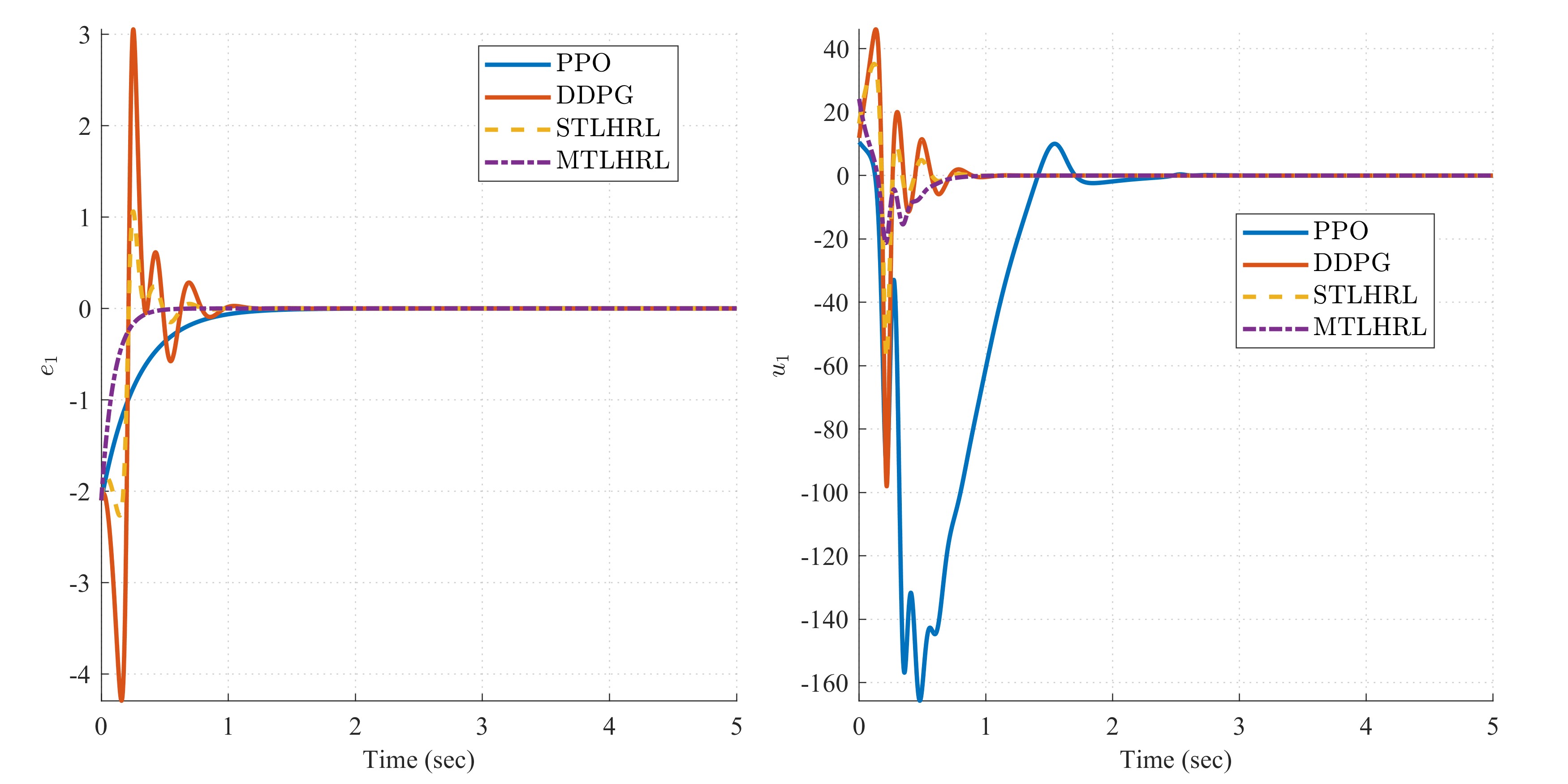
- 实验表明,MTLHRL在超混沌系统和机器人控制中均优于基线方法,误差更低,收敛更快。
📝 摘要(中文)
本研究提出了多时间尺度Lyapunov约束分层强化学习(MTLHRL)框架,旨在克服高维随机系统控制中的维度灾难、缺乏时间抽象以及难以保证随机稳定性的问题。MTLHRL将分层策略集成到半马尔可夫决策过程(SMDP)中,利用高层策略进行战略规划,低层策略进行反应控制,有效管理复杂的多时间尺度决策并降低维度开销。通过拉格朗日松弛和多时间尺度actor-critic更新优化神经Lyapunov函数,严格保证稳定性,确保在随机动态下的均方有界性或渐近稳定性。该框架通过信任域约束和解耦优化,促进高效可靠的学习。在8D超混沌系统和5-DOF机器人机械臂上的大量仿真表明,MTLHRL在稳定性和性能方面均优于基线方法,记录了最低的误差指标(例如,超混沌控制中的积分绝对误差(IAE):3.912,机器人控制中的IAE:1.623),实现了更快的收敛速度,并表现出卓越的抗干扰能力。MTLHRL为复杂随机系统的鲁棒控制提供了一个理论基础扎实且实际可行的解决方案。
🔬 方法详解
问题定义:论文旨在解决高维随机动态系统自适应控制问题。现有方法面临维度灾难,难以处理复杂的多时间尺度决策,并且缺乏对系统稳定性的有效保证,尤其是在存在随机扰动的情况下。这些问题限制了其在机器人、自动驾驶等领域的应用。
核心思路:论文的核心思路是结合分层强化学习和Lyapunov稳定性理论。通过分层策略,将控制任务分解为高层战略规划和低层反应控制,从而降低维度。利用神经Lyapunov函数,显式地约束系统的稳定性,并通过优化算法保证学习过程中的稳定性。
技术框架:MTLHRL框架包含以下主要模块:1) 分层策略:高层策略负责长期目标规划,低层策略执行具体动作。2) 半马尔可夫决策过程(SMDP):用于建模多时间尺度决策过程。3) 神经Lyapunov函数:用于评估系统稳定性,并作为约束条件加入到优化目标中。4) 多时间尺度Actor-Critic:分别更新高层和低层策略,并使用信任域约束保证学习的稳定性。5) 拉格朗日松弛:用于将Lyapunov约束融入到优化目标中。
关键创新:该论文的关键创新在于将分层强化学习与Lyapunov稳定性理论相结合,提出了一种多时间尺度、稳定性保证的控制框架。与传统方法相比,MTLHRL能够有效处理高维问题,实现多时间尺度决策,并显式地保证系统的稳定性。
关键设计:论文的关键设计包括:1) Lyapunov函数的选择和训练:使用神经网络逼近Lyapunov函数,并通过优化算法使其满足Lyapunov稳定性条件。2) 多时间尺度Actor-Critic更新:分别针对高层和低层策略进行更新,并使用不同的学习率。3) 信任域约束:限制策略更新的幅度,保证学习的稳定性。4) 拉格朗日松弛:将Lyapunov约束转化为优化目标中的惩罚项,并通过调整拉格朗日乘子来平衡性能和稳定性。
🖼️ 关键图片

📊 实验亮点
在8D超混沌系统和5-DOF机器人机械臂上的实验结果表明,MTLHRL显著优于基线方法。在超混沌控制中,MTLHRL的积分绝对误差(IAE)为3.912,在机器人控制中,IAE为1.623,均远低于基线方法。此外,MTLHRL还表现出更快的收敛速度和更强的抗干扰能力。
🎯 应用场景
该研究成果可应用于机器人控制、自动驾驶、航空航天等领域,尤其适用于需要高精度和高可靠性的复杂动态系统。通过保证系统的稳定性,可以提高系统的安全性和鲁棒性,降低故障风险,具有重要的实际应用价值和潜在的经济效益。
📄 摘要(原文)
Controlling high-dimensional stochastic systems, critical in robotics, autonomous vehicles, and hyperchaotic systems, faces the curse of dimensionality, lacks temporal abstraction, and often fails to ensure stochastic stability. To overcome these limitations, this study introduces the Multi-Timescale Lyapunov-Constrained Hierarchical Reinforcement Learning (MTLHRL) framework. MTLHRL integrates a hierarchical policy within a semi-Markov Decision Process (SMDP), featuring a high-level policy for strategic planning and a low-level policy for reactive control, which effectively manages complex, multi-timescale decision-making and reduces dimensionality overhead. Stability is rigorously enforced using a neural Lyapunov function optimized via Lagrangian relaxation and multi-timescale actor-critic updates, ensuring mean-square boundedness or asymptotic stability in the face of stochastic dynamics. The framework promotes efficient and reliable learning through trust-region constraints and decoupled optimization. Extensive simulations on an 8D hyperchaotic system and a 5-DOF robotic manipulator demonstrate MTLHRL's empirical superiority. It significantly outperforms baseline methods in both stability and performance, recording the lowest error indices (e.g., Integral Absolute Error (IAE): 3.912 in hyperchaotic control and IAE: 1.623 in robotics), achieving faster convergence, and exhibiting superior disturbance rejection. MTLHRL offers a theoretically grounded and practically viable solution for robust control of complex stochastic systems.