Estimating Continuum Robot Shape under External Loading using Spatiotemporal Neural Networks
作者: Enyi Wang, Zhen Deng, Chuanchuan Pan, Bingwei He, Jianwei Zhang
分类: cs.RO
发布日期: 2025-10-25
备注: 2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
💡 一句话要点
提出时空神经网络,融合多模态信息,精确估计受载连续体机器人的形状。
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 连续体机器人 形状估计 时空神经网络 多模态融合 深度学习
📋 核心要点
- 现有连续体机器人形状估计方法难以准确处理外部载荷引起的形变,精度有待提高。
- 论文提出一种时空神经网络,融合历史肌腱位移和RGB图像,预测机器人形变后的点云。
- 实验表明,该方法在有无载荷情况下,形状估计误差分别达到0.08mm和0.22mm,优于现有方法。
📝 摘要(中文)
本文提出了一种基于学习的方法,用于精确估计受外部载荷作用的柔性连续体机器人的3D形状。该方法引入了一种时空神经网络架构,融合了多模态输入,包括当前和历史的肌腱位移数据以及RGB图像,以生成表示机器人变形配置的点云。该网络集成了用于时间特征提取的循环神经模块、用于空间特征提取的编码模块以及用于将视觉数据中提取的空间特征与来自历史执行器输入的时间依赖性相结合的多模态融合模块。通过将贝塞尔曲线拟合到预测的点云来实现连续的3D形状重建。实验验证表明,我们的方法实现了高精度,平均形状估计误差为0.08毫米(无载荷)和0.22毫米(有载荷),优于TDCR形状感知领域的现有方法。结果验证了基于深度学习的时空数据融合在载荷条件下进行精确形状估计的有效性。
🔬 方法详解
问题定义:连续体机器人在外部载荷作用下,形状会发生复杂变化,精确估计其3D形状是机器人控制和任务规划的关键。现有方法,如基于模型的力学方法,计算复杂度高,且难以准确建模复杂的载荷情况。基于传感器的方案成本较高,且可能影响机器人的灵活性。因此,需要一种能够准确、高效地估计受载连续体机器人形状的方法。
核心思路:论文的核心思路是利用深度学习方法,从多模态数据中学习机器人形状与外部载荷之间的复杂关系。通过融合历史的肌腱位移数据(反映机器人的控制输入)和RGB图像(提供机器人形状的视觉信息),网络能够更好地理解机器人的当前状态和形变情况。时空神经网络的设计允许网络捕捉时间上的依赖关系,从而提高形状估计的准确性。
技术框架:该方法的技术框架主要包括以下几个模块:1) 时间特征提取模块:使用循环神经网络(RNN)处理历史肌腱位移数据,提取时间上的依赖关系。2) 空间特征提取模块:使用卷积神经网络(CNN)处理RGB图像,提取空间特征。3) 多模态融合模块:将时间特征和空间特征进行融合,得到融合后的特征表示。4) 点云预测模块:使用全连接层将融合后的特征映射到3D点云,表示机器人的形状。5) 形状重建模块:将预测的点云拟合成贝塞尔曲线,得到连续的3D形状。
关键创新:该方法最重要的技术创新点在于时空神经网络的设计,它能够有效地融合多模态数据,并捕捉时间上的依赖关系。与传统的基于模型的或者仅使用单一模态数据的方法相比,该方法能够更准确地估计受载连续体机器人的形状。此外,使用点云作为中间表示,然后拟合贝塞尔曲线,能够实现连续且精确的3D形状重建。
关键设计:在时间特征提取模块中,使用了GRU或者LSTM等循环神经网络单元。在空间特征提取模块中,可以使用预训练的CNN模型,如ResNet或者VGG。多模态融合模块可以使用简单的拼接或者更复杂的注意力机制。损失函数可以使用点云之间的Chamfer距离或者Earth Mover's Distance,以衡量预测点云与真实点云之间的差异。贝塞尔曲线的阶数和控制点数量需要根据机器人的形状复杂程度进行调整。
🖼️ 关键图片
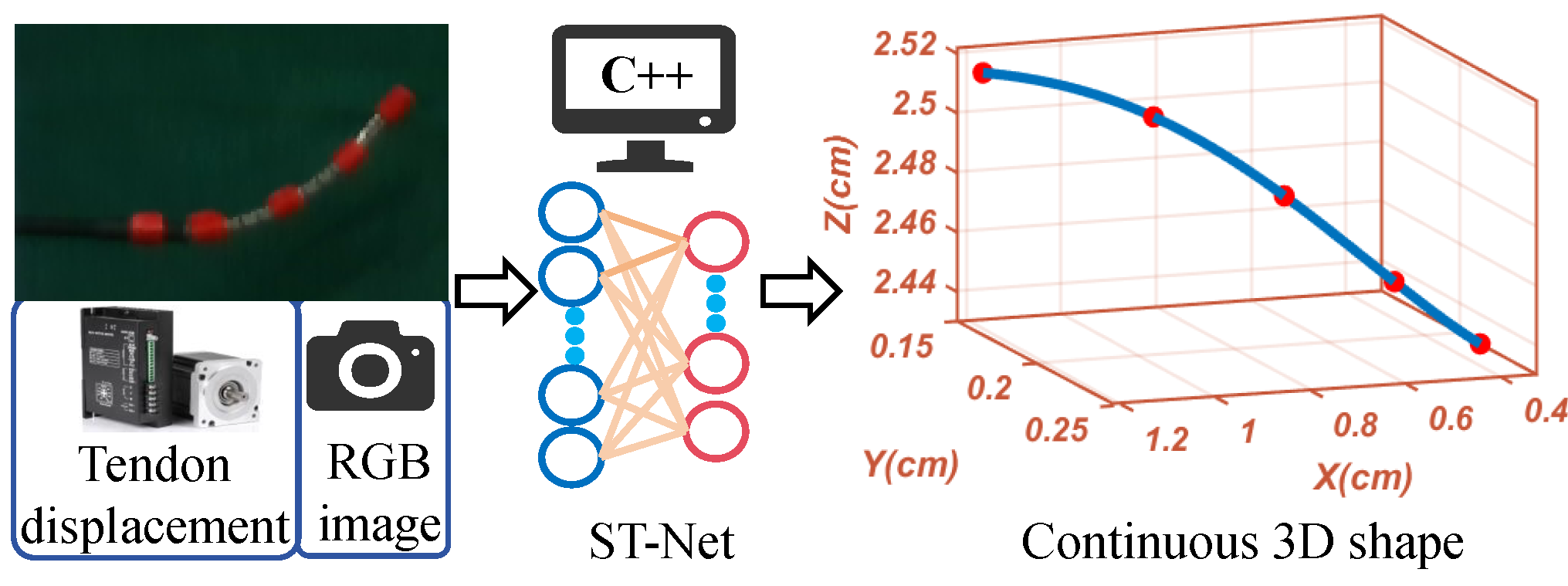


📊 实验亮点
实验结果表明,该方法在无载荷情况下,平均形状估计误差为0.08mm,在有载荷情况下,平均形状估计误差为0.22mm。与现有方法相比,该方法在形状估计精度方面有显著提升,验证了时空神经网络在连续体机器人形状估计中的有效性。
🎯 应用场景
该研究成果可应用于医疗机器人、工业检测、搜救等领域。在医疗领域,可用于精确控制连续体机器人在人体内的运动,进行微创手术。在工业检测领域,可用于检测复杂结构的内部缺陷。在搜救领域,可用于在狭小空间内进行搜索和救援。
📄 摘要(原文)
This paper presents a learning-based approach for accurately estimating the 3D shape of flexible continuum robots subjected to external loads. The proposed method introduces a spatiotemporal neural network architecture that fuses multi-modal inputs, including current and historical tendon displacement data and RGB images, to generate point clouds representing the robot's deformed configuration. The network integrates a recurrent neural module for temporal feature extraction, an encoding module for spatial feature extraction, and a multi-modal fusion module to combine spatial features extracted from visual data with temporal dependencies from historical actuator inputs. Continuous 3D shape reconstruction is achieved by fitting Bézier curves to the predicted point clouds. Experimental validation demonstrates that our approach achieves high precision, with mean shape estimation errors of 0.08 mm (unloaded) and 0.22 mm (loaded), outperforming state-of-the-art methods in shape sensing for TDCRs. The results validate the efficacy of deep learning-based spatiotemporal data fusion for precise shape estimation under loading conditions.