Scalable Vision-Language-Action Model Pretraining for Robotic Manipulation with Real-Life Human Activity Videos
作者: Qixiu Li, Yu Deng, Yaobo Liang, Lin Luo, Lei Zhou, Chengtang Yao, Lingqi Zeng, Zhiyuan Feng, Huizhi Liang, Sicheng Xu, Yizhong Zhang, Xi Chen, Hao Chen, Lily Sun, Dong Chen, Jiaolong Yang, Baining Guo
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-10-24
备注: Project page: https://microsoft.github.io/VITRA/
💡 一句话要点
提出基于大规模人类活动视频的VLA模型预训练方法,提升机器人操作泛化性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱六:视频提取与匹配 (Video Extraction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人操作 视觉-语言-动作模型 预训练 人类活动视频 具身智能
📋 核心要点
- 现有机器人操作模型泛化性不足,难以应对真实世界复杂场景。
- 利用大规模无标注人类活动视频,自动生成VLA训练数据,模拟机器人操作。
- 预训练模型在零样本任务中表现出色,微调后显著提升机器人操作成功率。
📝 摘要(中文)
本文提出了一种新颖的机器人操作视觉-语言-动作(VLA)模型预训练方法,该方法利用大量未经标注的真实人类手部活动视频记录。通过将人类手部视为灵巧的机器人末端执行器,我们展示了“野外”的以自我为中心的人类视频可以被转换成与现有机器人VLA训练数据在任务粒度和标签上完全对齐的数据格式。这通过开发一种全自动的整体人类活动分析方法来实现,该方法适用于任意人类手部视频。该方法可以生成原子级别的手部活动片段及其语言描述,每个片段都伴随着逐帧的3D手部运动和相机运动。我们处理了大量的以自我为中心的视频,并创建了一个包含100万个片段和2600万帧的手部VLA训练数据集。该训练数据涵盖了真实生活中的各种物体和概念、灵巧的操作任务以及环境变化,大大超过了现有机器人数据的覆盖范围。我们设计了一个灵巧的手部VLA模型架构,并在此数据集上预训练该模型。该模型在完全未见过的真实世界观察中表现出强大的零样本能力。此外,在少量真实机器人动作数据上对其进行微调可以显著提高任务成功率和对真实机器人实验中新物体的泛化能力。我们还展示了模型任务性能相对于预训练数据规模的吸引人的缩放行为。我们相信这项工作为可扩展的VLA预训练奠定了坚实的基础,推动机器人朝着真正可泛化的具身智能发展。
🔬 方法详解
问题定义:现有机器人操作模型依赖于有限的标注数据,泛化能力较弱,难以适应真实世界中种类繁多的物体、任务和环境变化。如何利用海量未标注的真实世界数据来提升机器人操作模型的泛化能力是一个关键问题。
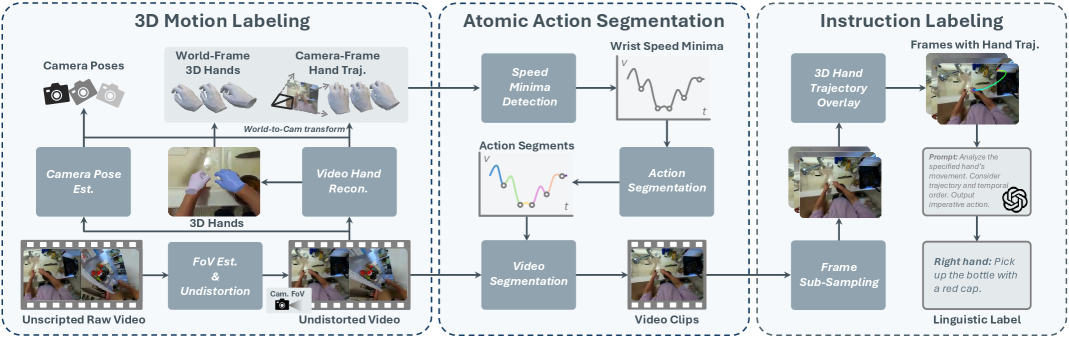
核心思路:将人类手部活动视为灵巧的机器人末端执行器,利用人类活动视频数据来预训练机器人操作模型。通过自动分析人类活动视频,提取手部运动轨迹、物体交互信息和语言描述,构建大规模的VLA训练数据集。
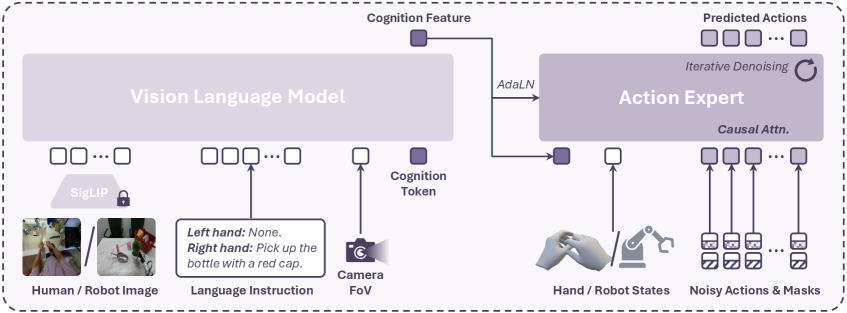
技术框架:该方法包含以下几个主要模块:1) 人类活动视频采集与处理:收集大量以自我为中心的人类手部活动视频。2) 全自动人类活动分析:开发一种全自动的整体人类活动分析方法,用于从视频中提取原子级别的手部活动片段、语言描述、3D手部运动和相机运动。3) VLA模型设计与预训练:设计一个灵巧的手部VLA模型架构,并在大规模手部VLA训练数据集上进行预训练。4) 机器人实验与微调:在真实机器人平台上进行实验,并使用少量真实机器人动作数据对预训练模型进行微调。
关键创新:该方法的核心创新在于利用大规模无标注人类活动视频进行机器人操作模型的预训练。与以往依赖于人工标注或合成数据的方法不同,该方法能够自动生成大规模的VLA训练数据,覆盖更广泛的物体、任务和环境变化。
关键设计:该方法的关键设计包括:1) 全自动人类活动分析方法,能够准确地从视频中提取手部运动轨迹、物体交互信息和语言描述。2) 灵巧的手部VLA模型架构,能够有效地学习视觉、语言和动作之间的关系。3) 大规模手部VLA训练数据集,包含100万个片段和2600万帧,覆盖了真实生活中的各种场景。
🖼️ 关键图片

📊 实验亮点
该模型在未见过的真实世界观察中表现出强大的零样本能力。在少量真实机器人动作数据上进行微调后,任务成功率显著提高,并且对真实机器人实验中的新物体具有更好的泛化能力。实验还表明,模型性能随着预训练数据规模的增加而提升,验证了该方法的可扩展性。
🎯 应用场景
该研究成果可应用于各种机器人操作任务,例如家庭服务机器人、工业机器人和医疗机器人。通过利用大规模人类活动视频进行预训练,可以显著提升机器人在复杂环境中的操作能力和泛化能力,使其能够更好地适应真实世界的挑战。该技术还有潜力应用于虚拟现实和增强现实等领域,提升人机交互的自然性和智能化。
📄 摘要(原文)
This paper presents a novel approach for pretraining robotic manipulation Vision-Language-Action (VLA) models using a large corpus of unscripted real-life video recordings of human hand activities. Treating human hand as dexterous robot end-effector, we show that "in-the-wild" egocentric human videos without any annotations can be transformed into data formats fully aligned with existing robotic V-L-A training data in terms of task granularity and labels. This is achieved by the development of a fully-automated holistic human activity analysis approach for arbitrary human hand videos. This approach can generate atomic-level hand activity segments and their language descriptions, each accompanied with framewise 3D hand motion and camera motion. We process a large volume of egocentric videos and create a hand-VLA training dataset containing 1M episodes and 26M frames. This training data covers a wide range of objects and concepts, dexterous manipulation tasks, and environment variations in real life, vastly exceeding the coverage of existing robot data. We design a dexterous hand VLA model architecture and pretrain the model on this dataset. The model exhibits strong zero-shot capabilities on completely unseen real-world observations. Additionally, fine-tuning it on a small amount of real robot action data significantly improves task success rates and generalization to novel objects in real robotic experiments. We also demonstrate the appealing scaling behavior of the model's task performance with respect to pretraining data scale. We believe this work lays a solid foundation for scalable VLA pretraining, advancing robots toward truly generalizable embodied intelligence.