SutureBot: A Precision Framework & Benchmark For Autonomous End-to-End Suturing
作者: Jesse Haworth, Juo-Tung Chen, Nigel Nelson, Ji Woong Kim, Masoud Moghani, Chelsea Finn, Axel Krieger
分类: cs.RO, cs.LG
发布日期: 2025-10-23
备注: 10 pages, 5 figures, 4 tables, NeurIPS 2025
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
SutureBot:用于自主端到端缝合的精确框架与基准测试
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱四:生成式动作 (Generative Motion) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人缝合 自主操作 目标条件框架 模仿学习 视觉-语言-动作模型 达芬奇机器人 手术机器人
📋 核心要点
- 现有机器人缝合研究缺乏在真实硬件上的完全自主端到端流程,限制了实际应用。
- SutureBot通过目标条件框架优化插入点精度,提升了缝合的准确性和可靠性。
- 论文发布了包含1890个演示的高保真数据集,并评估了VLA模型,为后续研究提供了基准。
📝 摘要(中文)
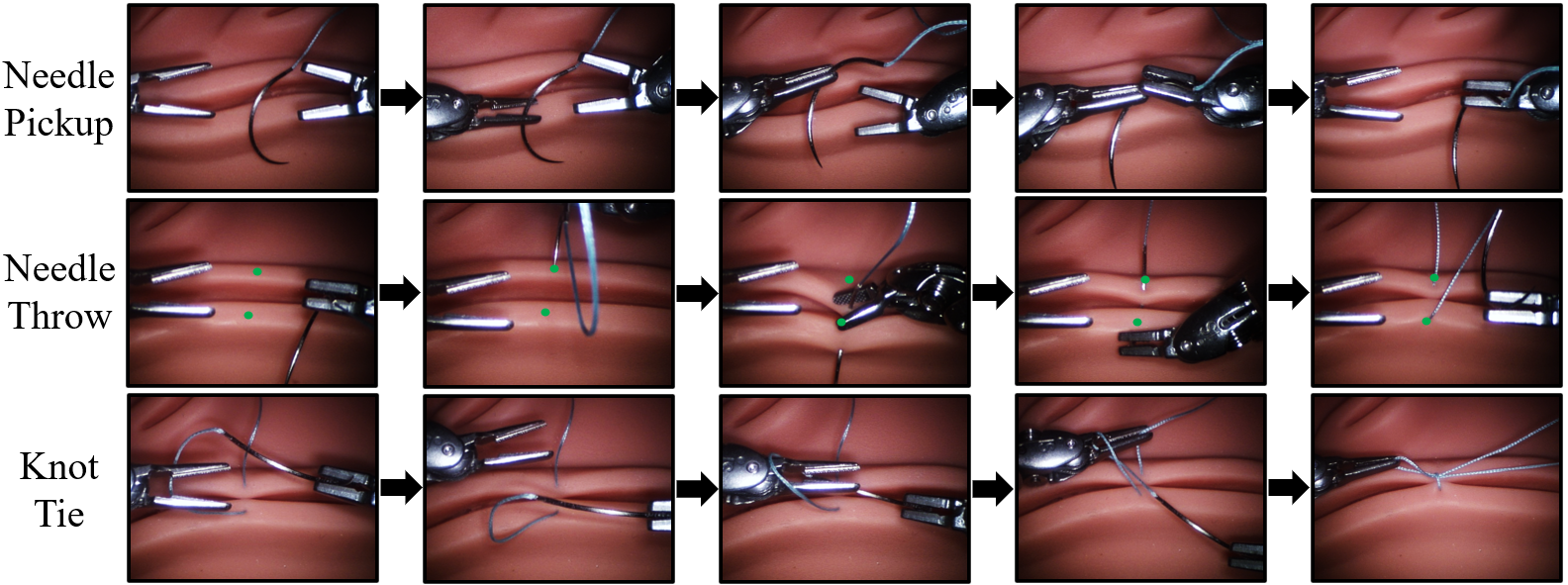
机器人缝合是一项典型的长时程灵巧操作任务,需要协调的持针、精确的组织穿透和牢固的结扎。尽管在端到端自主化方面做出了诸多努力,但尚未在物理硬件上展示完全自主的缝合流程。我们推出了SutureBot:一个在达芬奇研究套件(dVRK)上的自主缝合基准,涵盖了持针、组织插入和结扎。为了确保可重复性,我们发布了一个包含1890个缝合演示的高保真数据集。此外,我们提出了一个以目标为条件的框架,该框架明确地优化了插入点精度,与仅任务基线相比,目标精度提高了59%-74%。为了将此任务确立为灵巧模仿学习的基准,我们评估了最先进的视觉-语言-动作(VLA)模型,包括$π_0$,GR00T N1,OpenVLA-OFT和多任务ACT,每个模型都通过高级任务预测策略进行了增强。自主缝合是实现手术机器人自主化的关键里程碑。这些贡献支持可重复的评估和开发以精确为中心的长时程灵巧操作策略,这对于端到端缝合是必需的。数据集可在https://huggingface.co/datasets/jchen396/suturebot上获得。
🔬 方法详解
问题定义:论文旨在解决机器人自主缝合中,如何在真实机器人平台上实现端到端的高精度缝合问题。现有方法通常难以在真实环境中达到足够的精度和鲁棒性,尤其是在长时程操作中,误差会不断累积,导致最终缝合失败。现有方法的痛点在于缺乏一个统一的基准测试平台和高精度控制策略,难以进行有效的算法评估和比较。
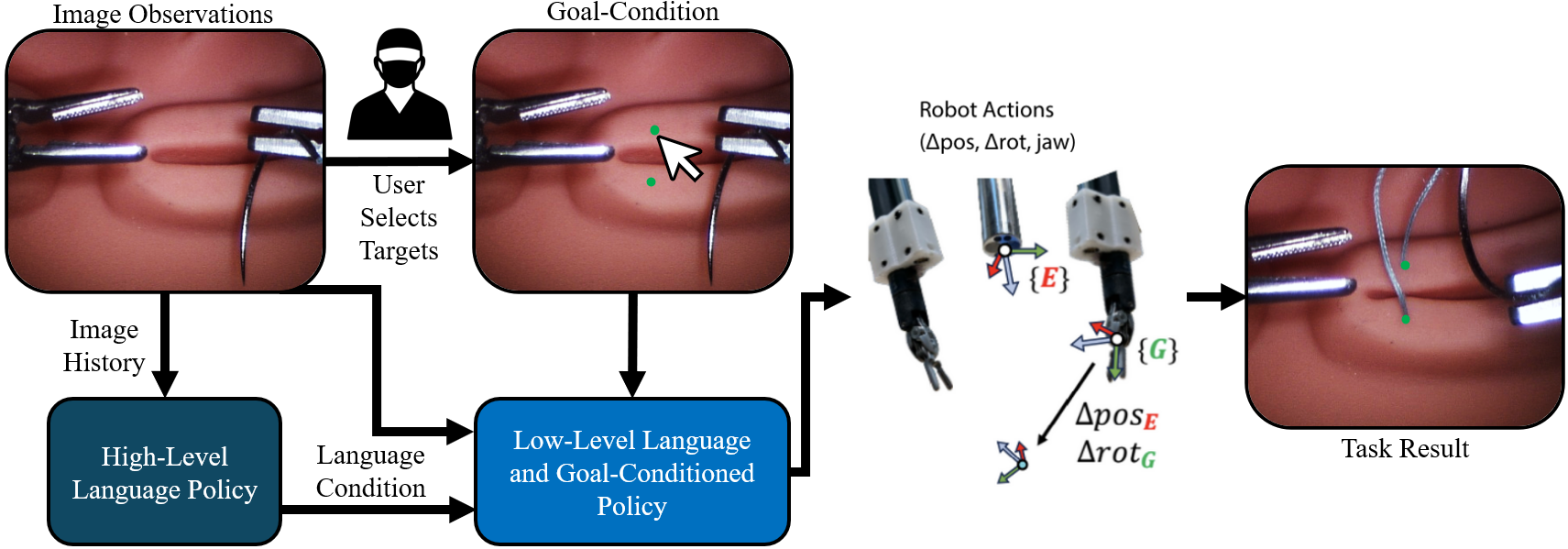
核心思路:论文的核心思路是通过引入目标条件框架,显式地优化缝合过程中的关键步骤,特别是组织插入点的精度。通过将缝合任务分解为多个子任务,并针对每个子任务设计特定的目标函数,从而提高整体缝合的成功率和精度。此外,论文还构建了一个高保真数据集,用于训练和评估模仿学习算法。
技术框架:SutureBot框架主要包含以下几个模块:1) 感知模块:用于获取机器人和环境的状态信息,例如针的位置、组织形状等。2) 规划模块:根据感知信息和目标任务,生成一系列的动作指令。3) 控制模块:将动作指令转化为机器人的控制信号,驱动机器人执行缝合操作。4) 任务预测模块:使用高级任务预测策略增强VLA模型,用于预测当前应该执行的子任务。整体流程是从针的拾取开始,经过组织插入,最终完成结扎。
关键创新:论文最重要的技术创新点在于提出了一个以目标为条件的框架,该框架显式地优化了插入点精度。与传统的任务导向方法相比,该框架能够更有效地减少误差累积,提高缝合的精度和成功率。此外,论文还构建了一个高保真数据集,为模仿学习算法的训练和评估提供了重要的数据支持。
关键设计:在目标条件框架中,论文设计了特定的目标函数来优化插入点精度。例如,可以使用均方误差损失函数来最小化实际插入点与目标插入点之间的距离。在VLA模型的训练中,论文使用了交叉熵损失函数来优化任务预测策略。此外,论文还对机器人的控制参数进行了精细的调整,以确保机器人能够精确地执行缝合操作。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SutureBot提出的目标条件框架在插入点精度方面,相比于仅任务基线提高了59%-74%。此外,论文还评估了多种最先进的视觉-语言-动作(VLA)模型,为后续研究提供了重要的参考基准。该数据集和基准测试的发布,将促进机器人自主缝合领域的研究进展。
🎯 应用场景
该研究成果可应用于微创手术、远程手术等领域,提高手术的精度和效率,降低手术风险。通过自主缝合,可以减轻医生的工作负担,并为缺乏专业医生的地区提供医疗服务。未来,该技术有望应用于更复杂的机器人手术任务,推动手术机器人技术的发展。
📄 摘要(原文)
Robotic suturing is a prototypical long-horizon dexterous manipulation task, requiring coordinated needle grasping, precise tissue penetration, and secure knot tying. Despite numerous efforts toward end-to-end autonomy, a fully autonomous suturing pipeline has yet to be demonstrated on physical hardware. We introduce SutureBot: an autonomous suturing benchmark on the da Vinci Research Kit (dVRK), spanning needle pickup, tissue insertion, and knot tying. To ensure repeatability, we release a high-fidelity dataset comprising 1,890 suturing demonstrations. Furthermore, we propose a goal-conditioned framework that explicitly optimizes insertion-point precision, improving targeting accuracy by 59\%-74\% over a task-only baseline. To establish this task as a benchmark for dexterous imitation learning, we evaluate state-of-the-art vision-language-action (VLA) models, including $π_0$, GR00T N1, OpenVLA-OFT, and multitask ACT, each augmented with a high-level task-prediction policy. Autonomous suturing is a key milestone toward achieving robotic autonomy in surgery. These contributions support reproducible evaluation and development of precision-focused, long-horizon dexterous manipulation policies necessary for end-to-end suturing. Dataset is available at: https://huggingface.co/datasets/jchen396/suturebot