FieldGen: From Teleoperated Pre-Manipulation Trajectories to Field-Guided Data Generation
作者: Wenhao Wang, Kehe Ye, Xinyu Zhou, Tianxing Chen, Cao Min, Qiaoming Zhu, Xiaokang Yang, Ping Luo, Yongjian Shen, Yang Yang, Maoqing Yao, Yao Mu
分类: cs.RO, cs.AI, cs.HC
发布日期: 2025-10-23 (更新: 2025-10-28)
备注: Webpage: https://fieldgen.github.io/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
FieldGen:提出一种基于场引导的数据生成框架,用于提升机器人操作策略的训练。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 机器人操作 数据生成 吸引场 强化学习 模仿学习 轨迹生成 远程操作 策略学习
📋 核心要点
- 现有机器人操作数据收集方法难以兼顾数据规模、多样性和质量,仿真存在真实差距,远程操作成本高。
- FieldGen通过解耦预操作和精细操作阶段,利用吸引场自动生成多样化轨迹,结合人工演示的关键信息。
- 实验表明,FieldGen训练的策略在成功率和稳定性上优于远程操作基线,并显著降低了人工成本。
📝 摘要(中文)
大规模和多样化的数据集对于训练鲁棒的机器人操作策略至关重要。然而,现有的数据收集方法难以平衡规模、多样性和质量。仿真提供了可扩展性,但存在模拟到真实的差距;远程操作产生高质量的演示,但多样性有限且人工成本高昂。我们介绍了FieldGen,一个场引导的数据生成框架,它能够以最小的人工监督实现可扩展、多样化和高质量的真实世界数据收集。FieldGen将操作分解为两个阶段:一个允许轨迹多样性的预操作阶段,以及一个需要专家精度的精细操作阶段。人工演示捕获关键的接触和姿势信息,之后,一个吸引场自动生成收敛到成功配置的各种轨迹。这种解耦设计将可扩展的轨迹多样性与精确的监督相结合。此外,FieldGen-Reward使用奖励注释增强生成的数据,以进一步增强策略学习。实验表明,与基于远程操作的基线相比,使用FieldGen训练的策略实现了更高的成功率和改进的稳定性,同时显著减少了长期真实世界数据收集中的人工工作量。
🔬 方法详解
问题定义:现有机器人操作策略训练依赖大规模数据集,但真实数据收集成本高昂且难以保证多样性。仿真数据存在与真实世界的差距,而远程操作虽然质量高,但成本高且数据多样性受限。因此,如何高效、低成本地生成大规模、高质量且多样化的真实世界机器人操作数据成为关键问题。
核心思路:FieldGen的核心思路是将机器人操作任务分解为两个阶段:预操作阶段和精细操作阶段。预操作阶段允许轨迹具有较大的多样性,而精细操作阶段则需要专家级的精确控制。通过这种解耦,可以利用吸引场自动生成多样化的预操作轨迹,同时保证最终操作的精度。
技术框架:FieldGen框架包含以下几个主要模块:1) 人工演示模块:收集少量人工远程操作数据,用于提取关键的接触和姿势信息。2) 吸引场生成模块:基于人工演示数据,构建一个吸引场,该场能够引导机器人生成多样化的预操作轨迹,最终收敛到成功的操作配置。3) 奖励标注模块 (FieldGen-Reward):对生成的数据进行奖励标注,用于进一步提升策略学习的效果。整体流程是从人工演示开始,然后利用吸引场生成大量数据,最后使用生成的数据训练机器人操作策略。
关键创新:FieldGen的关键创新在于其解耦的设计和吸引场的应用。与传统的端到端数据收集方法不同,FieldGen将操作分解为预操作和精细操作两个阶段,从而能够分别处理轨迹多样性和操作精度的问题。吸引场的应用使得可以自动生成大量多样化的轨迹,而无需大量的人工干预。
关键设计:吸引场的具体设计包括定义吸引点(通常是目标物体或关键位置),以及定义吸引力的强度和范围。吸引力的强度可以根据机器人与吸引点之间的距离进行调整,以保证轨迹的平滑性和收敛性。此外,FieldGen-Reward模块使用逆强化学习或模仿学习等方法,根据人工演示数据学习奖励函数,并将其用于标注生成的数据。
🖼️ 关键图片
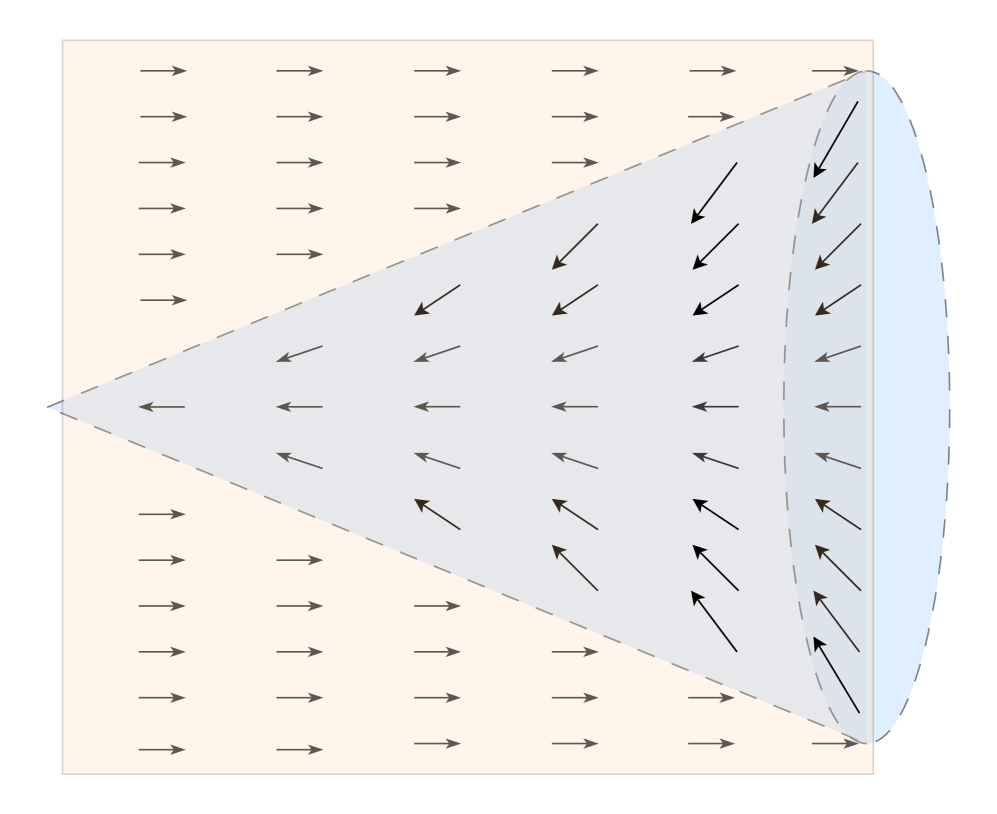
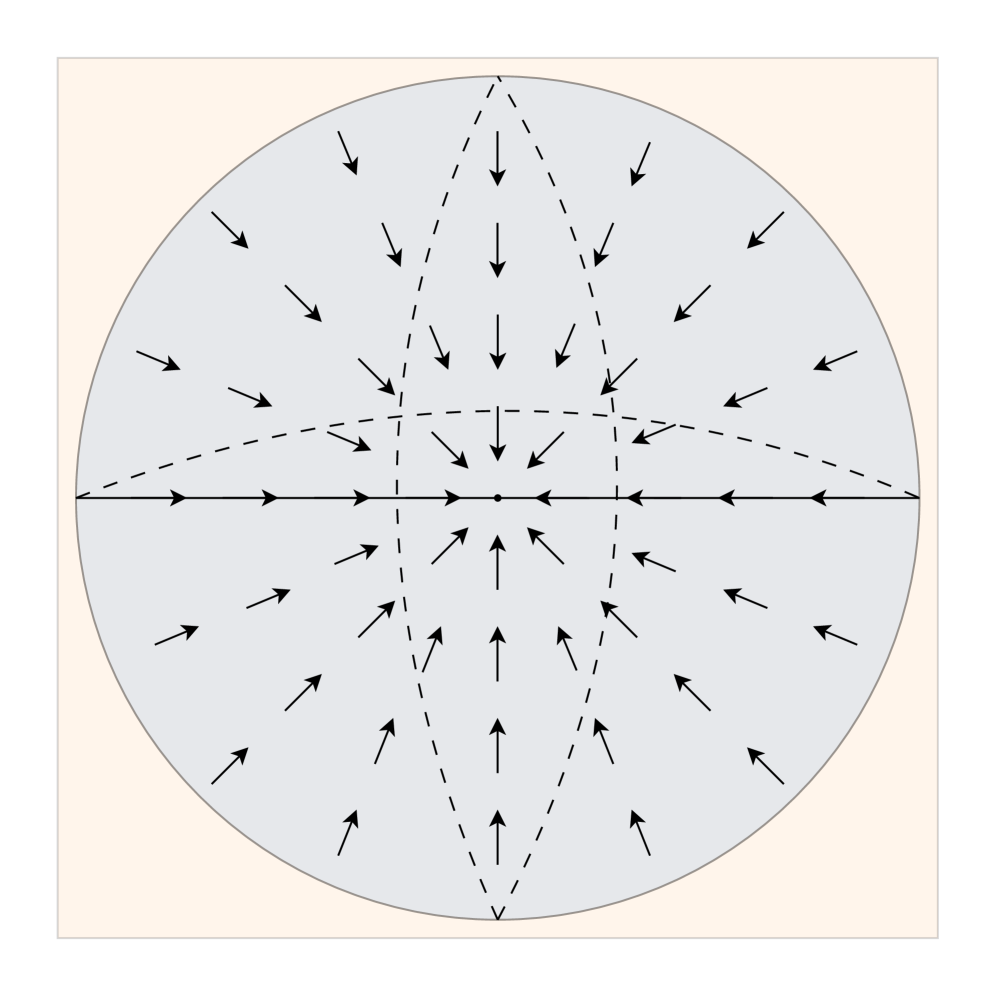

📊 实验亮点
实验结果表明,使用FieldGen训练的机器人操作策略在真实世界中取得了显著的性能提升。与基于远程操作的基线相比,FieldGen在多个操作任务上实现了更高的成功率和更好的稳定性。例如,在抓取任务中,FieldGen将成功率提高了15%,同时显著减少了人工数据标注的工作量。
🎯 应用场景
FieldGen可广泛应用于各种机器人操作任务的数据生成,例如物体抓取、装配、放置等。该方法能够降低数据收集成本,提高数据质量和多样性,从而加速机器人操作策略的训练和部署。未来,FieldGen可以扩展到更复杂的机器人任务,例如多物体操作、动态环境操作等,并与其他数据增强技术相结合,进一步提升机器人操作的智能化水平。
📄 摘要(原文)
Large-scale and diverse datasets are vital for training robust robotic manipulation policies, yet existing data collection methods struggle to balance scale, diversity, and quality. Simulation offers scalability but suffers from sim-to-real gaps, while teleoperation yields high-quality demonstrations with limited diversity and high labor cost. We introduce FieldGen, a field-guided data generation framework that enables scalable, diverse, and high-quality real-world data collection with minimal human supervision. FieldGen decomposes manipulation into two stages: a pre-manipulation phase, allowing trajectory diversity, and a fine manipulation phase requiring expert precision. Human demonstrations capture key contact and pose information, after which an attraction field automatically generates diverse trajectories converging to successful configurations. This decoupled design combines scalable trajectory diversity with precise supervision. Moreover, FieldGen-Reward augments generated data with reward annotations to further enhance policy learning. Experiments demonstrate that policies trained with FieldGen achieve higher success rates and improved stability compared to teleoperation-based baselines, while significantly reducing human effort in long-term real-world data collection. Webpage is available at https://fieldgen.github.io/.