Real-Time Gait Adaptation for Quadrupeds using Model Predictive Control and Reinforcement Learning
作者: Prakrut Kotecha, Ganga Nair B, Shishir Kolathaya
分类: cs.RO, cs.AI
发布日期: 2025-10-23 (更新: 2025-10-24)
备注: 7 pages
💡 一句话要点
提出基于MPC与强化学习的四足机器人实时步态自适应框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 四足机器人 步态自适应 模型预测控制 强化学习 能量效率 运动规划
📋 核心要点
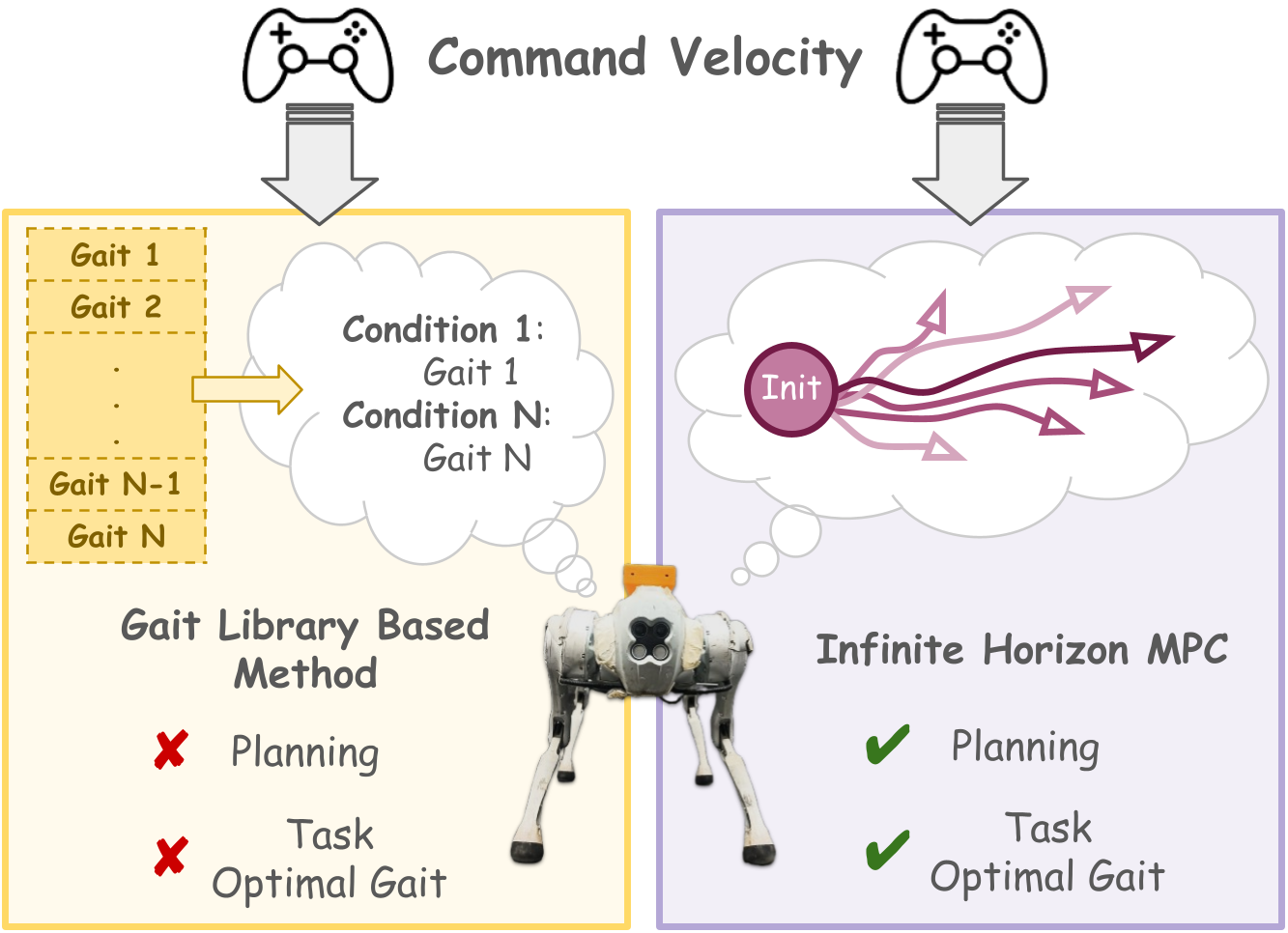
- 传统强化学习方法在四足机器人运动控制中存在收敛于单一步态,导致性能次优的问题。
- 该论文结合模型预测控制(MPC)和强化学习,利用MPPI算法和Dreamer模块,实现步态和动作的联合优化。
- 仿真实验表明,该方法在保证精确跟踪的同时,显著降低了能量消耗,并实现了自适应步态。
📝 摘要(中文)
本文提出了一种用于四足机器人实时步态自适应的优化框架,该框架结合了模型预测路径积分(MPPI)算法和Dreamer模块,旨在生成自适应且最优的运动策略。在每个时间步,MPPI利用学习到的Dreamer奖励函数联合优化动作和步态变量,该奖励函数鼓励速度跟踪、能量效率、稳定性和平滑过渡,同时惩罚突兀的步态变化。此外,还引入了学习到的价值函数作为终端奖励,将规划扩展到无限时域。在Unitree Go1的仿真实验中,结果表明,该框架在不同目标速度下,平均降低了高达36.48%的能量消耗,同时保持了精确的跟踪和自适应的、任务相关的步态。
🔬 方法详解
问题定义:现有四足机器人控制方法,特别是基于强化学习的方法,容易收敛到单一的步态模式,无法根据任务需求和环境变化进行灵活调整,导致能量效率低下和适应性不足。传统的模型预测控制方法虽然能针对特定任务进行优化,但缺乏对未知环境的适应能力。
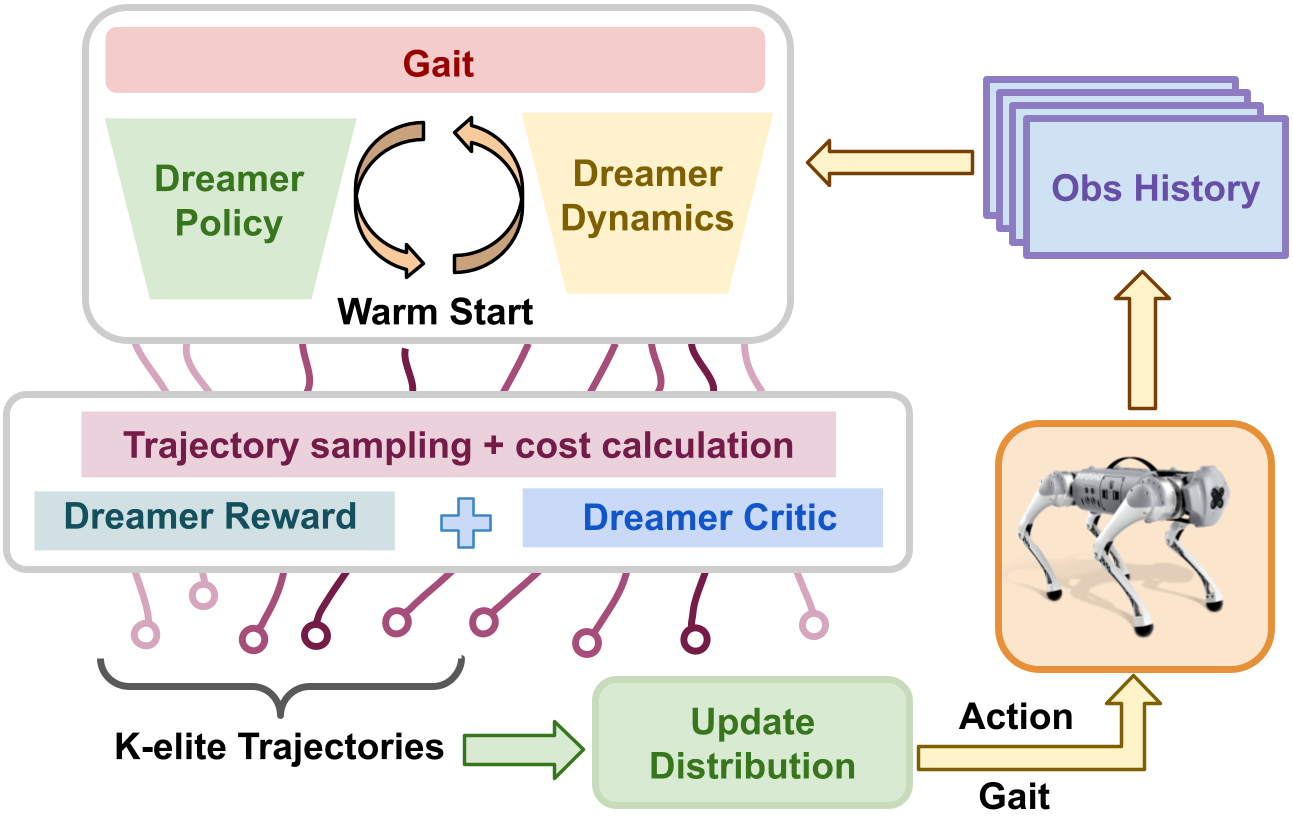
核心思路:本文的核心思路是将模型预测控制(MPC)与强化学习相结合,利用MPC的优化能力和强化学习的环境适应性,实现四足机器人的实时步态自适应。通过学习一个奖励函数(Dreamer reward)来指导MPC的优化过程,从而在保证任务完成的同时,优化步态选择,提高能量效率和稳定性。
技术框架:该框架主要包含以下几个模块:1) MPPI控制器:负责在每个时间步优化动作和步态变量。2) Dreamer模块:学习一个奖励函数,用于评估不同动作和步态的优劣。3) 价值函数:作为终端奖励,用于扩展规划视野到无限时域。整体流程是,MPPI控制器根据当前状态和Dreamer奖励函数,生成一系列候选动作和步态,然后选择最优的动作和步态执行。
关键创新:该方法最重要的创新点在于将模型预测控制与强化学习相结合,并使用学习到的奖励函数来指导MPC的优化过程。与传统的MPC方法相比,该方法具有更强的环境适应性。与传统的强化学习方法相比,该方法能够更有效地探索步态空间,并获得更优的步态策略。
关键设计:Dreamer奖励函数的设计至关重要,它需要综合考虑速度跟踪、能量效率、稳定性以及步态平滑过渡等因素。价值函数的设计也需要仔细考虑,以保证终端奖励的准确性。MPPI控制器的参数设置,如采样数量和噪声水平,也会影响算法的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在Unitree Go1四足机器人仿真中,能够显著降低能量消耗,平均降低高达36.48%,同时保持精确的速度跟踪和自适应步态。该方法优于传统的固定步态控制方法,证明了其在实时步态自适应方面的有效性。
🎯 应用场景
该研究成果可应用于各种四足机器人应用场景,例如搜救、巡检、物流等。通过实时步态自适应,机器人可以更好地适应复杂地形和变化的任务需求,提高工作效率和安全性。此外,该方法还可以推广到其他类型的机器人,例如双足机器人和轮式机器人。
📄 摘要(原文)
Model-free reinforcement learning (RL) has enabled adaptable and agile quadruped locomotion; however, policies often converge to a single gait, leading to suboptimal performance. Traditionally, Model Predictive Control (MPC) has been extensively used to obtain task-specific optimal policies but lacks the ability to adapt to varying environments. To address these limitations, we propose an optimization framework for real-time gait adaptation in a continuous gait space, combining the Model Predictive Path Integral (MPPI) algorithm with a Dreamer module to produce adaptive and optimal policies for quadruped locomotion. At each time step, MPPI jointly optimizes the actions and gait variables using a learned Dreamer reward that promotes velocity tracking, energy efficiency, stability, and smooth transitions, while penalizing abrupt gait changes. A learned value function is incorporated as terminal reward, extending the formulation to an infinite-horizon planner. We evaluate our framework in simulation on the Unitree Go1, demonstrating an average reduction of up to 36.48 % in energy consumption across varying target speeds, while maintaining accurate tracking and adaptive, task-appropriate gaits.