Multi-Modal Decentralized Reinforcement Learning for Modular Reconfigurable Lunar Robots
作者: Ashutosh Mishra, Shreya Santra, Elian Neppel, Edoardo M. Rossi Lombardi, Shamistan Karimov, Kentaro Uno, Kazuya Yoshida
分类: cs.RO, cs.MA
发布日期: 2025-10-23
备注: Accepted in IEEE iSpaRo 2025. Awaiting Publication
💡 一句话要点
提出多模态去中心化强化学习,用于模块化可重构月球机器人控制。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模块化机器人 去中心化强化学习 可重构机器人 月球探测 软演员-评论家 近端策略优化 零样本泛化
📋 核心要点
- 模块化机器人形态组合爆炸,难以统一控制,现有方法泛化性不足。
- 采用去中心化强化学习,每个模块独立学习策略,实现零样本泛化。
- 仿真和月球模拟测试表明,该方法在移动、转向和操作任务中表现出色。
📝 摘要(中文)
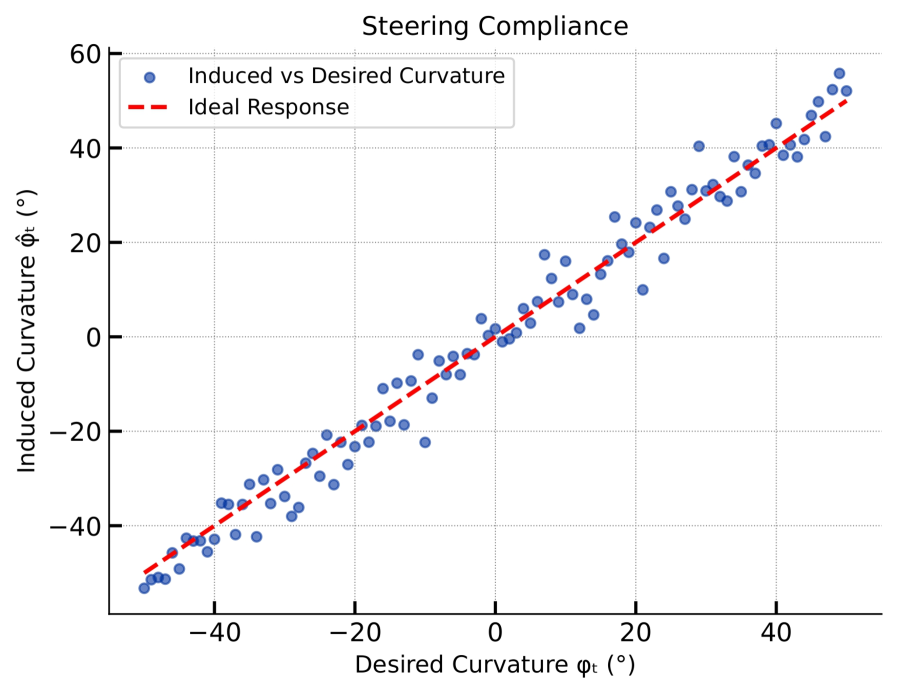
本文提出了一种去中心化强化学习(Dec-RL)方案,用于控制模块化可重构机器人,使其适应特定任务的太空作业。每个模块学习自己的策略:轮式模块使用软演员-评论家(SAC)算法进行移动,7自由度(DoF)机械臂使用近端策略优化(PPO)算法进行转向和操作,从而实现对未见配置的零样本泛化。在仿真中,转向策略在期望角度和实际角度之间的平均绝对误差为3.63°;操作策略在目标偏移标准下的成功率稳定在84.6%;轮式策略在保持99.6%成功率的同时,将平均电机扭矩相对于基线降低了95.4%。月球模拟场地测试验证了自主移动、转向和初步对准以进行重构的零样本集成。该系统在策略执行的同步、并行和顺序模式之间平稳过渡,没有空闲状态或控制冲突,表明这是一种可扩展、可重用且稳健的模块化月球机器人方法。
🔬 方法详解
问题定义:论文旨在解决模块化可重构机器人在复杂环境(如月球表面)中的自主控制问题。现有集中式控制方法难以应对模块化机器人形态组合爆炸带来的挑战,泛化能力差,难以适应新的机器人构型。此外,传统控制方法难以处理月球表面的不确定性和复杂性,需要更鲁棒的控制策略。
核心思路:论文的核心思路是采用去中心化强化学习(Dec-RL),将整体控制问题分解为多个独立的子问题,每个模块(如轮式模块和机械臂模块)独立学习自己的控制策略。这种方法可以有效降低控制复杂度,提高系统的可扩展性和鲁棒性,并实现对未见构型的零样本泛化。
技术框架:整体框架包含以下几个主要模块:1) 轮式模块的SAC策略学习,用于实现自主移动;2) 机械臂模块的PPO策略学习,用于实现转向和操作;3) 策略执行模块,负责协调各个模块的策略执行,实现同步、并行和顺序模式的切换;4) 仿真环境和月球模拟场地,用于策略训练和验证。
关键创新:最重要的技术创新点在于将去中心化强化学习应用于模块化可重构机器人的控制。与传统的集中式控制方法相比,该方法具有更好的可扩展性、鲁棒性和泛化能力。此外,论文还针对轮式模块和机械臂模块分别设计了不同的强化学习算法(SAC和PPO),以适应其不同的运动特性和控制需求。
关键设计:轮式模块使用SAC算法,奖励函数设计考虑了速度、能耗和稳定性等因素。机械臂模块使用PPO算法,奖励函数设计考虑了目标接近程度、碰撞避免和操作成功率等因素。网络结构方面,采用了多层感知机(MLP)作为策略网络和价值网络。在策略执行模块中,设计了状态机来管理不同模式之间的切换,确保系统平稳运行。
🖼️ 关键图片


📊 实验亮点
仿真结果表明,转向策略的平均绝对误差为3.63°,操作策略的成功率达到84.6%,轮式策略在保持99.6%成功率的同时,将平均电机扭矩降低了95.4%。月球模拟场地测试验证了零样本集成能力,实现了自主移动、转向和初步对准,证明了该方法在实际环境中的可行性。
🎯 应用场景
该研究成果可应用于月球探测、空间站维护、灾后救援等领域。模块化机器人能够根据任务需求进行重构,适应不同的环境和任务要求。去中心化控制方法提高了系统的鲁棒性和可扩展性,使其能够应对复杂和不确定的环境。未来,该技术有望应用于更广泛的机器人领域,推动机器人智能化发展。
📄 摘要(原文)
Modular reconfigurable robots suit task-specific space operations, but the combinatorial growth of morphologies hinders unified control. We propose a decentralized reinforcement learning (Dec-RL) scheme where each module learns its own policy: wheel modules use Soft Actor-Critic (SAC) for locomotion and 7-DoF limbs use Proximal Policy Optimization (PPO) for steering and manipulation, enabling zero-shot generalization to unseen configurations. In simulation, the steering policy achieved a mean absolute error of 3.63° between desired and induced angles; the manipulation policy plateaued at 84.6 % success on a target-offset criterion; and the wheel policy cut average motor torque by 95.4 % relative to baseline while maintaining 99.6 % success. Lunar-analogue field tests validated zero-shot integration for autonomous locomotion, steering, and preliminary alignment for reconfiguration. The system transitioned smoothly among synchronous, parallel, and sequential modes for Policy Execution, without idle states or control conflicts, indicating a scalable, reusable, and robust approach for modular lunar robots.