MemER: Scaling Up Memory for Robot Control via Experience Retrieval
作者: Ajay Sridhar, Jennifer Pan, Satvik Sharma, Chelsea Finn
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-23
备注: Project page: https://jen-pan.github.io/memer/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MemER:通过经验检索扩展机器人控制的记忆能力
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器人控制 长期记忆 经验检索 分层策略 视觉-语言-动作模型
📋 核心要点
- 现有机器人策略缺乏有效利用长期记忆的能力,直接使用长序列或随机采样历史信息效率低且易出错。
- MemER提出一种分层策略框架,高层策略选择并跟踪相关历史关键帧,为低层策略生成指令。
- 实验表明,MemER在需要长期记忆的真实机器人操作任务中,性能优于现有方法,验证了其有效性。
📝 摘要(中文)
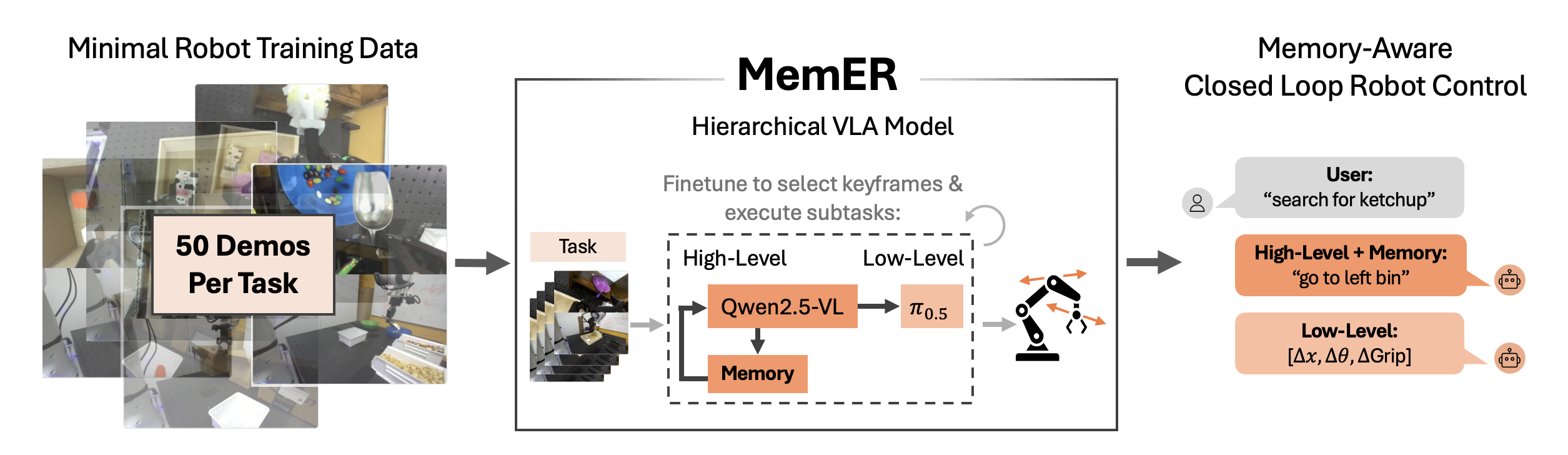
人类通常依赖记忆来执行任务,但大多数机器人策略缺乏这种能力。本文旨在赋予机器人策略相同的能力。直接依赖长观测历史在计算上代价高昂,且在协变量偏移下脆弱;而随意地对历史进行子采样会导致不相关或冗余的信息。因此,我们提出了一个分层策略框架,其中高层策略被训练来选择和跟踪先前相关的关键帧。高层策略在生成文本指令供低层策略执行时,会使用选定的关键帧和最近的帧。这种设计与现有的视觉-语言-动作(VLA)模型兼容,并使系统能够有效地推理长期依赖关系。在我们的实验中,我们分别微调了Qwen2.5-VL-7B-Instruct和$π_{0.5}$作为高层和低层策略,使用带有少量语言注释的演示数据。我们的方法MemER在三个需要数分钟记忆的真实世界长时程机器人操作任务上优于现有方法。
🔬 方法详解
问题定义:现有机器人控制策略难以有效利用长期记忆。简单地将所有历史观测作为输入计算成本高昂,且容易受到协变量偏移的影响。而随机采样历史信息则可能引入不相关或冗余的信息,导致策略性能下降。因此,如何高效地利用历史经验是机器人长期控制面临的关键问题。
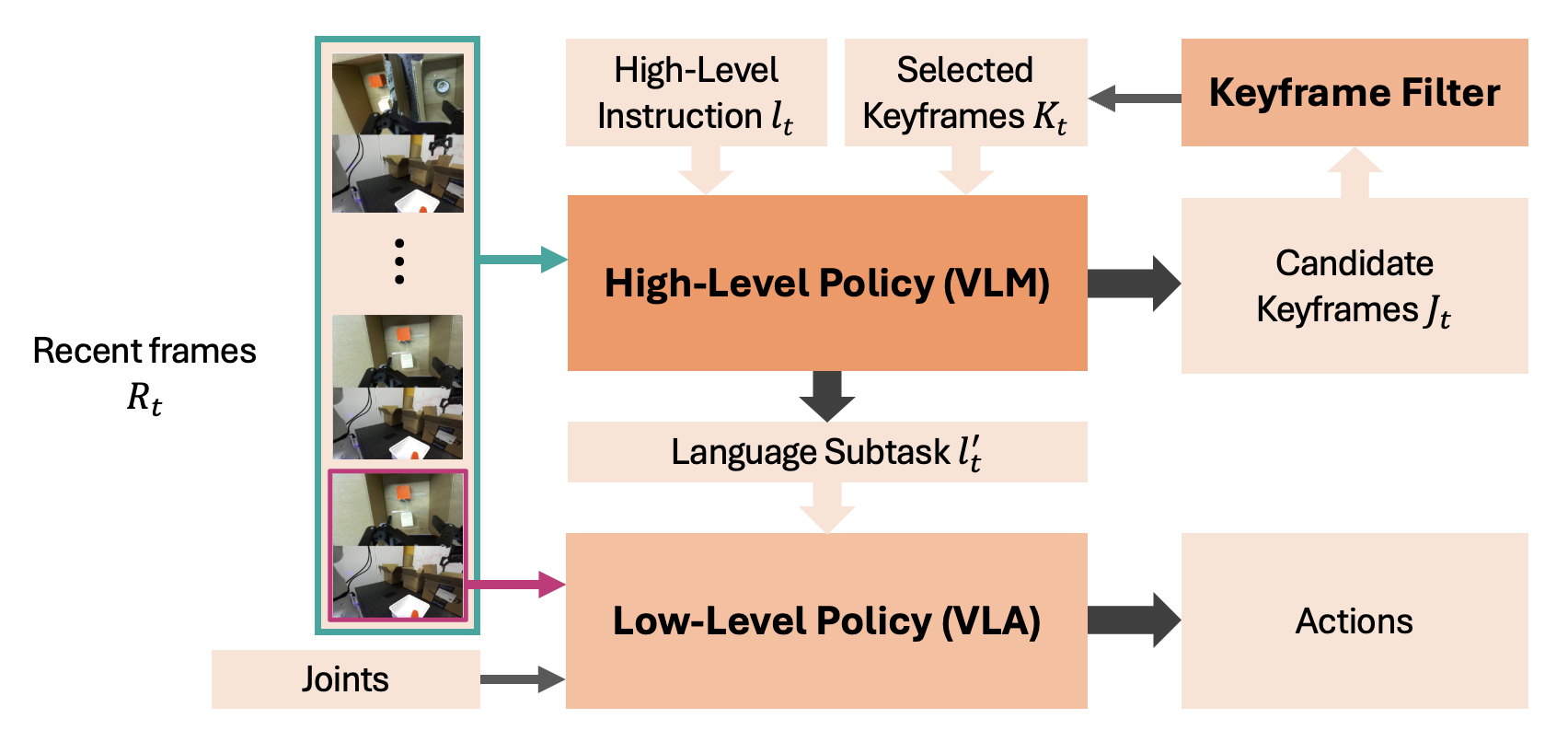
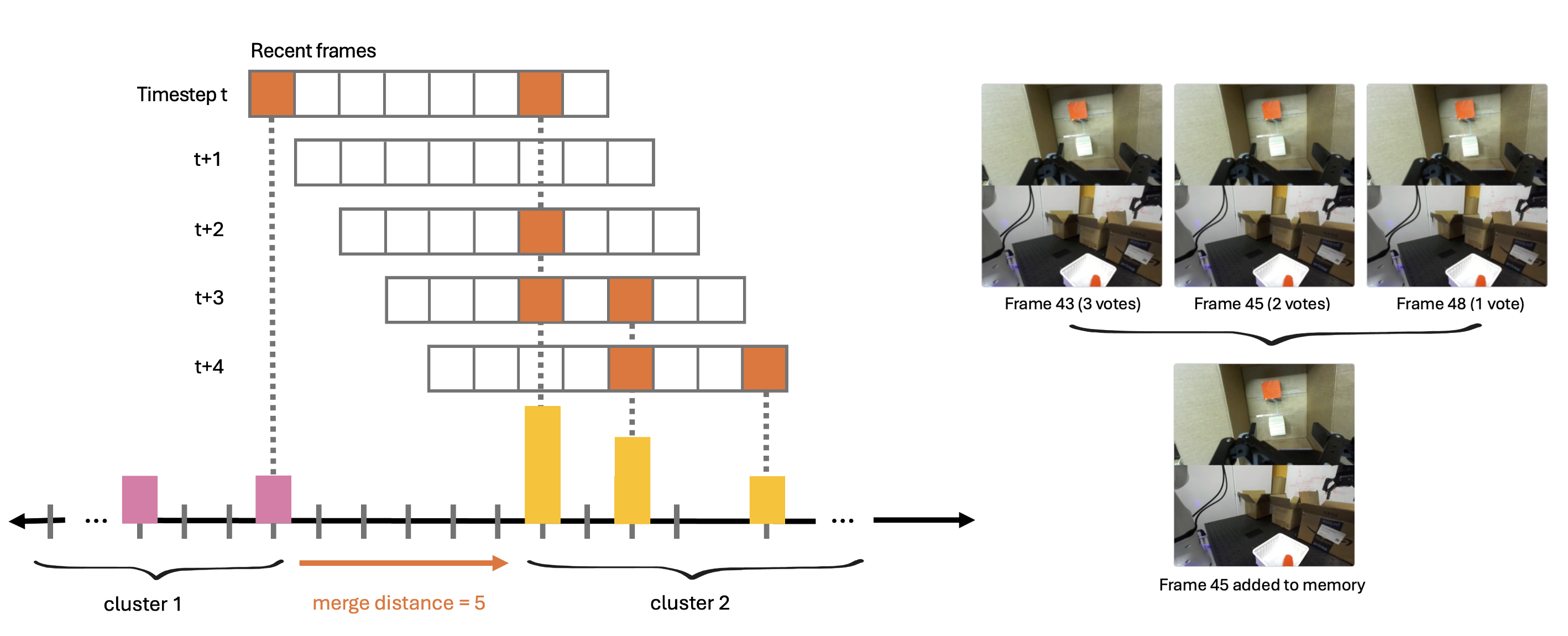
核心思路:MemER的核心思路是借鉴人类的记忆机制,通过选择性地记住和检索关键帧来提高机器人策略的效率和鲁棒性。高层策略负责从历史经验中选择与当前任务相关的关键帧,并将这些关键帧与当前观测结合,为低层策略生成指令。这种分层结构使得策略能够专注于重要的信息,从而减少计算量并提高性能。
技术框架:MemER采用分层策略框架,包含一个高层策略和一个低层策略。高层策略接收当前观测和历史经验,输出需要检索的关键帧索引。低层策略接收当前观测和高层策略检索到的关键帧,生成控制指令。高层策略和低层策略共同完成机器人控制任务。整个框架可以与现有的视觉-语言-动作(VLA)模型相结合。
关键创新:MemER的关键创新在于引入了经验检索机制,使得机器人策略能够选择性地利用历史经验。与以往方法相比,MemER不需要处理所有历史观测,而是只关注与当前任务相关的关键帧,从而大大提高了效率和鲁棒性。此外,MemER的分层结构也使得策略更容易训练和部署。
关键设计:高层策略使用Qwen2.5-VL-7B-Instruct进行微调,负责选择关键帧。低层策略使用$π_{0.5}$进行微调,负责执行控制指令。训练数据包括带有少量语言注释的演示数据。损失函数的设计旨在鼓励高层策略选择与当前任务相关的关键帧,并鼓励低层策略根据关键帧和当前观测生成正确的控制指令。
🖼️ 关键图片
📊 实验亮点
MemER在三个真实世界的长时程机器人操作任务上进行了评估,包括整理房间、堆叠积木和组装玩具。实验结果表明,MemER在所有任务上都优于现有方法,并且能够有效地利用长期记忆来完成任务。例如,在整理房间任务中,MemER的成功率比基线方法提高了20%以上。
🎯 应用场景
MemER具有广泛的应用前景,例如家庭服务机器人、工业自动化机器人和医疗机器人等。它可以帮助机器人在复杂的环境中执行长期任务,例如清洁房间、组装产品和辅助手术。通过利用历史经验,MemER可以提高机器人的效率、鲁棒性和安全性,从而更好地服务于人类。
📄 摘要(原文)
Humans routinely rely on memory to perform tasks, yet most robot policies lack this capability; our goal is to endow robot policies with the same ability. Naively conditioning on long observation histories is computationally expensive and brittle under covariate shift, while indiscriminate subsampling of history leads to irrelevant or redundant information. We propose a hierarchical policy framework, where the high-level policy is trained to select and track previous relevant keyframes from its experience. The high-level policy uses selected keyframes and the most recent frames when generating text instructions for a low-level policy to execute. This design is compatible with existing vision-language-action (VLA) models and enables the system to efficiently reason over long-horizon dependencies. In our experiments, we finetune Qwen2.5-VL-7B-Instruct and $π_{0.5}$ as the high-level and low-level policies respectively, using demonstrations supplemented with minimal language annotations. Our approach, MemER, outperforms prior methods on three real-world long-horizon robotic manipulation tasks that require minutes of memory. Videos and code can be found at https://jen-pan.github.io/memer/.