Reinforcement Learning-based Robust Wall Climbing Locomotion Controller in Ferromagnetic Environment
作者: Yong Um, Young-Ha Shin, Joon-Ha Kim, Soonpyo Kwon, Hae-Won Park
分类: cs.RO
发布日期: 2025-10-23
备注: 8 pages, 6 figures
💡 一句话要点
提出基于强化学习的四足磁吸附壁面攀爬鲁棒控制器
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 四足机器人 壁面攀爬 磁吸附 鲁棒控制
📋 核心要点
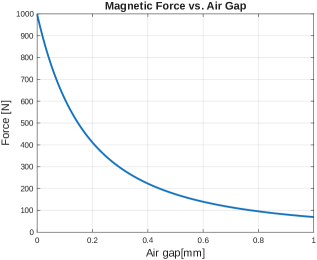
- 现有磁吸附攀爬机器人控制方法难以应对磁力不确定性,易受部分接触、气隙和吸附失效影响。
- 论文提出基于强化学习的控制策略,结合物理吸附模型和课程学习,提升控制器的鲁棒性。
- 实验表明,该方法在仿真和真实机器人上均表现出良好的壁面攀爬性能,能有效应对吸附失效。
📝 摘要(中文)
本文提出了一种基于强化学习的四足壁面攀爬运动框架,该框架显式地解决了磁吸附足端的不确定性问题。一个基于物理的四足磁吸附攀爬机器人吸附模型被整合到仿真环境中,以捕捉部分接触、气隙敏感性和概率性吸附失效。为了稳定学习并实现可靠的迁移,我们设计了一个三阶段课程学习方案:(1)在没有吸附的情况下,在平地上获得爬行步态;(2)在激活吸附模型的同时,逐渐将重力矢量旋转到垂直方向;(3)注入随机吸附失效,以鼓励滑移恢复。学习到的策略在退化的吸附条件下,在仿真中实现了高成功率、强大的吸附保持能力和从脱离状态的快速恢复。与假设完美吸附的模型预测控制(MPC)基线相比,我们的控制器在间歇性失去吸附时仍能维持运动。使用无束缚机器人的硬件实验进一步证实了在钢表面上的鲁棒垂直爬行,即使在瞬态不对准和不完全吸附的情况下也能保持稳定性。这些结果表明,将课程学习与现实的吸附建模相结合,为复杂环境中的磁吸附攀爬机器人提供了一个具有弹性的从仿真到现实的框架。
🔬 方法详解
问题定义:论文旨在解决四足磁吸附攀爬机器人在实际环境中,由于磁力吸附的不确定性(如部分接触、气隙、吸附失效)导致的运动控制问题。现有的控制方法,例如模型预测控制(MPC),通常假设完美的吸附条件,因此在实际应用中鲁棒性较差,容易因吸附失效而导致机器人跌落。
核心思路:论文的核心思路是利用强化学习(RL)训练一个能够显式处理吸附不确定性的控制器。通过在仿真环境中建立一个更真实的物理吸附模型,并结合课程学习策略,使RL智能体能够学习到在各种吸附条件下保持稳定运动的策略。这种方法的核心在于让智能体在训练过程中经历各种吸附失效的情况,从而提高其在真实环境中的鲁棒性。
技术框架:整体框架包含以下几个主要阶段:1) 仿真环境搭建:建立一个包含四足机器人和磁吸附模型的仿真环境,该模型能够模拟部分接触、气隙敏感性和概率性吸附失效。2) 课程学习:采用三阶段课程学习策略,逐步增加训练难度:a) 在无吸附条件下学习平地爬行;b) 逐渐旋转重力矢量并激活吸附模型;c) 引入随机吸附失效。3) 强化学习训练:使用强化学习算法(具体算法未明确说明,但暗示是off-policy算法)训练控制器,目标是最大化机器人在壁面上的稳定运动。4) Sim-to-Real迁移:将训练好的控制器部署到真实机器人上进行测试。
关键创新:论文的关键创新在于:1) 显式吸附不确定性建模:通过物理模型模拟实际环境中的吸附不确定性,使智能体能够学习到更鲁棒的控制策略。2) 课程学习策略:设计了一个三阶段课程学习方案,逐步引导智能体学习复杂的壁面攀爬任务。3) 强化学习与物理模型的结合:将强化学习与物理模型相结合,实现从仿真到真实的有效迁移。
关键设计:论文中关于关键设计的细节描述较少,但可以推断出以下几点:1) 吸附模型:基于物理的吸附模型,考虑了部分接触、气隙和概率性吸附失效,具体模型参数和公式未知。2) 强化学习算法:使用了某种off-policy的强化学习算法,具体算法未知。3) 奖励函数:奖励函数的设计目标是鼓励机器人在壁面上稳定运动,可能包含前进速度、姿态稳定性和吸附保持等方面的奖励。4) 网络结构:控制器的网络结构未知,但可以推断出是一个能够将机器人状态映射到关节控制指令的神经网络。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在仿真环境中实现了高成功率、强大的吸附保持能力和从脱离状态的快速恢复。与假设完美吸附的MPC基线相比,该控制器在间歇性失去吸附时仍能维持运动。硬件实验证实了在钢表面上的鲁棒垂直爬行,即使在瞬态不对准和不完全吸附的情况下也能保持稳定性。具体性能数据未知,但实验结果表明该方法具有良好的sim-to-real迁移能力。
🎯 应用场景
该研究成果可应用于各种需要在复杂环境中进行壁面攀爬的场景,例如桥梁检测、高层建筑维护、船舶检查等。通过提高机器人的自主性和鲁棒性,可以减少人工干预,提高工作效率,并降低安全风险。未来,该技术有望扩展到更复杂的环境和任务中,例如在管道内部进行检测和维护。
📄 摘要(原文)
We present a reinforcement learning framework for quadrupedal wall-climbing locomotion that explicitly addresses uncertainty in magnetic foot adhesion. A physics-based adhesion model of a quadrupedal magnetic climbing robot is incorporated into simulation to capture partial contact, air-gap sensitivity, and probabilistic attachment failures. To stabilize learning and enable reliable transfer, we design a three-phase curriculum: (1) acquire a crawl gait on flat ground without adhesion, (2) gradually rotate the gravity vector to vertical while activating the adhesion model, and (3) inject stochastic adhesion failures to encourage slip recovery. The learned policy achieves a high success rate, strong adhesion retention, and rapid recovery from detachment in simulation under degraded adhesion. Compared with a model predictive control (MPC) baseline that assumes perfect adhesion, our controller maintains locomotion when attachment is intermittently lost. Hardware experiments with the untethered robot further confirm robust vertical crawling on steel surfaces, maintaining stability despite transient misalignment and incomplete attachment. These results show that combining curriculum learning with realistic adhesion modeling provides a resilient sim-to-real framework for magnetic climbing robots in complex environments.