PathFormer: A Transformer with 3D Grid Constraints for Digital Twin Robot-Arm Trajectory Generation
作者: Ahmed Alanazi, Duy Ho, Yugyung Lee
分类: cs.RO
发布日期: 2025-10-23
备注: 8 pages, 7 figures, 7 tables
💡 一句话要点
PathFormer:结合3D网格约束的Transformer用于数字孪生机器人手臂轨迹生成
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 机器人手臂 轨迹规划 Transformer 3D网格 数字孪生
📋 核心要点
- 现有序列模型在机器人手臂轨迹规划中忽略运动结构,导致轨迹无效或效率低下。
- PathFormer通过3D网格表示编码运动,并使用约束掩码解码,保证轨迹的合法性和效率。
- 实验表明,PathFormer在精度、成功率等方面均表现出色,并具备良好的泛化能力。
📝 摘要(中文)
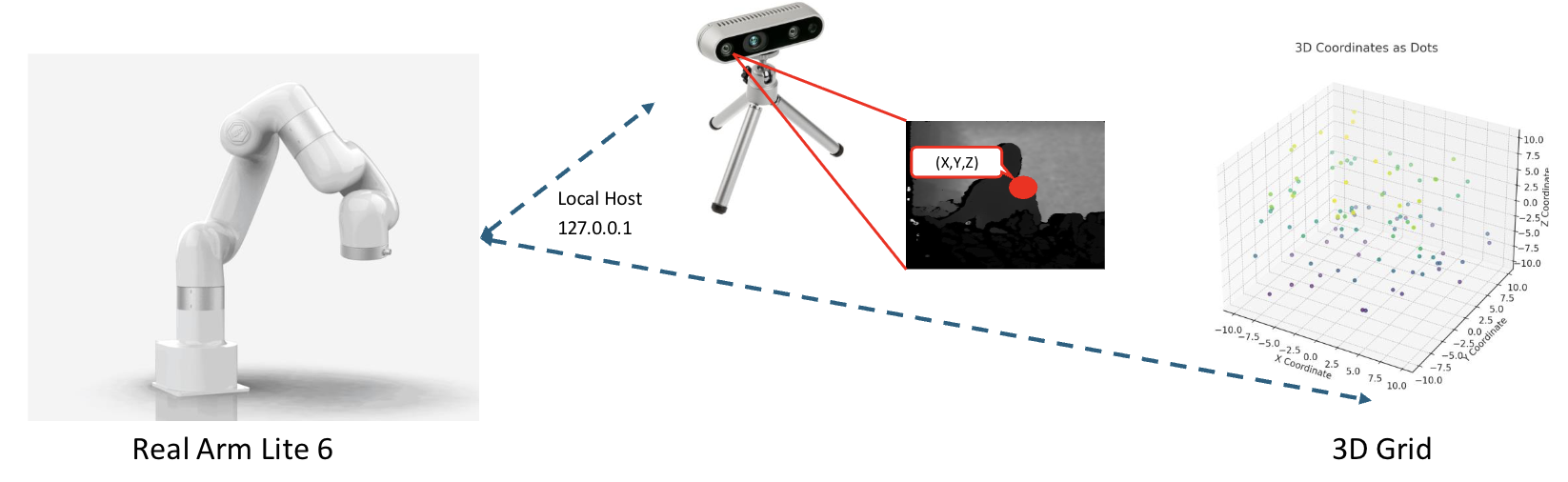
机器人手臂需要精确且任务感知的轨迹规划,但忽略运动结构的序列模型通常产生无效或低效的执行。本文提出了一种基于路径的Transformer,它使用3D网格(where/what/when)表示编码机器人运动,并采用约束掩码解码,在推理任务图和动作顺序的同时,强制执行格子相邻移动和工作空间边界。该模型在53,755条轨迹上训练(80%训练/20%验证),与真实值高度一致——步进精度89.44%,精确率93.32%,召回率89.44%,F1值为90.40%,并且通过构造保证99.99%的路径合法性。在配备深度相机数字孪生的xArm Lite 6上编译为运动基元后,在受控测试中达到高达97.5%的触达成功率和92.5%的拾取成功率,并在杂乱场景中跨60个语言指定的任务中达到86.7%的端到端成功率,通过局部重新定位吸收滑动和遮挡,而无需全局重新规划。这些结果表明,路径结构化表示使Transformer能够生成准确、可靠和可解释的机器人轨迹,桥接了基于图的规划和基于序列的学习,并为通用操作和sim-to-real迁移提供了实践基础。
🔬 方法详解
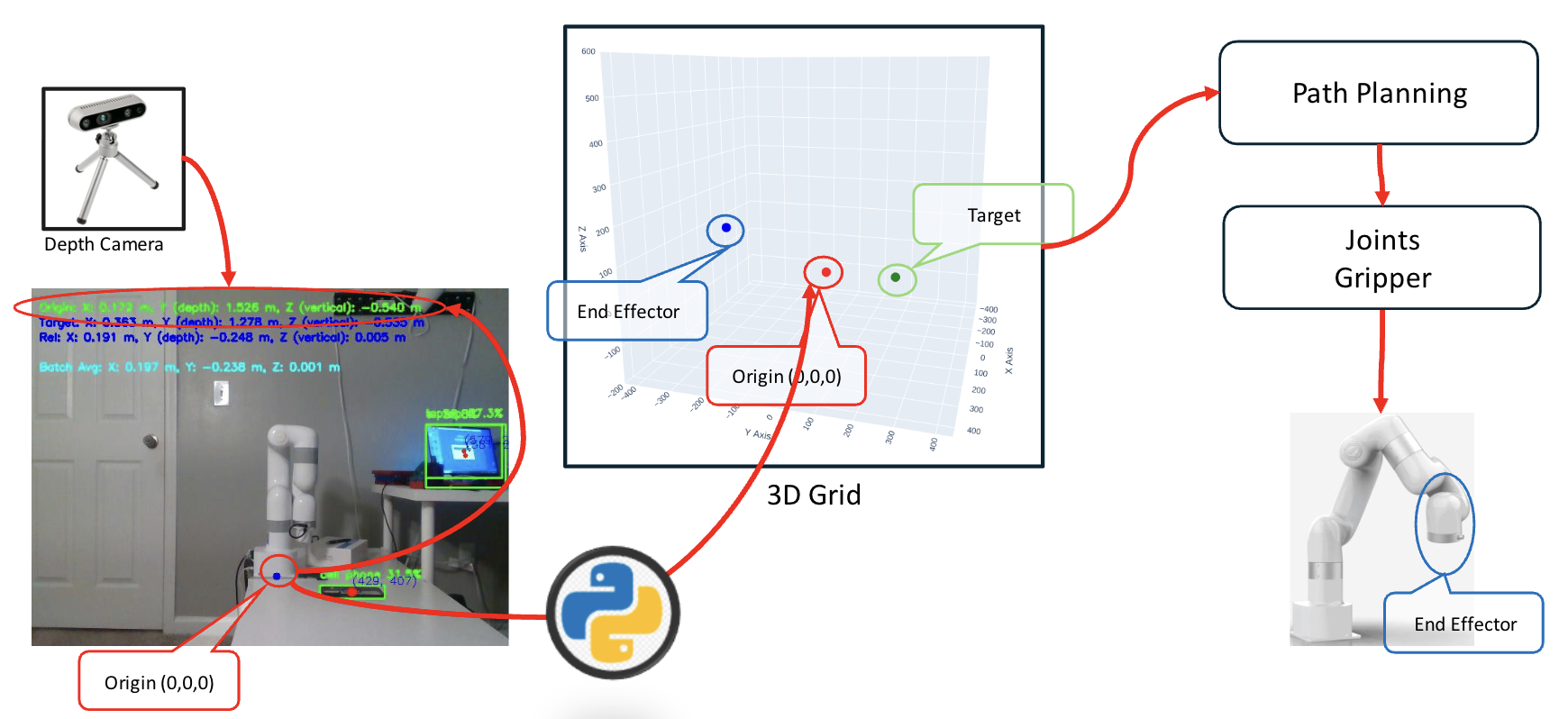
问题定义:机器人手臂轨迹规划需要精确且任务感知的运动,而现有序列模型缺乏对运动结构的建模能力,容易生成不合法或低效的轨迹。这些模型通常难以保证轨迹在工作空间内,也无法有效利用任务图和动作顺序等信息。
核心思路:本文的核心思路是将机器人运动表示为3D网格(where/what/when),并利用Transformer模型学习轨迹生成。通过引入约束掩码解码,强制执行格子相邻移动和工作空间边界,从而保证生成轨迹的合法性。这种方法结合了图规划和序列学习的优点。
技术框架:PathFormer的整体框架包括以下几个主要模块:1) 3D网格编码器:将机器人运动轨迹编码为3D网格表示。2) Transformer编码器:学习任务图和动作顺序的表示。3) 约束掩码解码器:生成合法的机器人运动轨迹,同时考虑任务目标。该框架利用Transformer强大的序列建模能力,并结合3D网格约束,实现高效且可靠的轨迹生成。
关键创新:PathFormer的关键创新在于将3D网格表示与约束掩码解码相结合,从而在Transformer框架下实现了对机器人运动结构的有效建模。与现有方法相比,PathFormer能够生成更合法、更高效的轨迹,并且能够更好地利用任务信息。
关键设计:PathFormer的关键设计包括:1) 3D网格的划分方式,需要根据机器人工作空间和运动范围进行合理设置。2) 约束掩码的设计,需要保证轨迹的连续性和合法性。3) Transformer模型的结构和参数设置,需要根据具体任务进行调整。4) 损失函数的设计,需要同时考虑轨迹的精度和合法性。
🖼️ 关键图片

📊 实验亮点
PathFormer在53,755条轨迹上训练后,步进精度达到89.44%,精确率93.32%,召回率89.44%,F1值为90.40%,且99.99%的路径合法。在xArm Lite 6上的实验表明,PathFormer在受控测试中达到高达97.5%的触达成功率和92.5%的拾取成功率,并在杂乱场景中跨60个语言指定的任务中达到86.7%的端到端成功率。
🎯 应用场景
PathFormer可应用于各种机器人手臂操作任务,如工业自动化、医疗机器人、家庭服务机器人等。该研究成果有助于提高机器人操作的精度、效率和可靠性,并为实现通用机器人操作和sim-to-real迁移奠定基础。未来,PathFormer有望在更复杂的机器人系统中发挥重要作用。
📄 摘要(原文)
Robotic arms require precise, task-aware trajectory planning, yet sequence models that ignore motion structure often yield invalid or inefficient executions. We present a Path-based Transformer that encodes robot motion with a 3-grid (where/what/when) representation and constraint-masked decoding, enforcing lattice-adjacent moves and workspace bounds while reasoning over task graphs and action order. Trained on 53,755 trajectories (80% train / 20% validation), the model aligns closely with ground truth -- 89.44% stepwise accuracy, 93.32% precision, 89.44% recall, and 90.40% F1 -- with 99.99% of paths legal by construction. Compiled to motor primitives on an xArm Lite 6 with a depth-camera digital twin, it attains up to 97.5% reach and 92.5% pick success in controlled tests, and 86.7% end-to-end success across 60 language-specified tasks in cluttered scenes, absorbing slips and occlusions via local re-grounding without global re-planning. These results show that path-structured representations enable Transformers to generate accurate, reliable, and interpretable robot trajectories, bridging graph-based planning and sequence-based learning and providing a practical foundation for general-purpose manipulation and sim-to-real transfer.