Using Non-Expert Data to Robustify Imitation Learning via Offline Reinforcement Learning
作者: Kevin Huang, Rosario Scalise, Cleah Winston, Ayush Agrawal, Yunchu Zhang, Rohan Baijal, Markus Grotz, Byron Boots, Benjamin Burchfiel, Masha Itkina, Paarth Shah, Abhishek Gupta
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-22 (更新: 2025-10-25)
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
利用离线强化学习,通过非专家数据增强模仿学习的鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 离线强化学习 非专家数据 机器人操作 鲁棒性 泛化能力 策略优化 数据增强
📋 核心要点
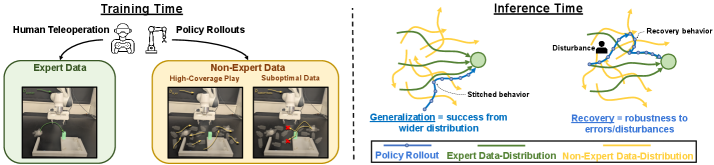
- 模仿学习依赖高质量专家数据,限制了其在真实场景中的泛化能力,非专家数据虽易获取但难以有效利用。
- 论文提出利用离线强化学习,通过算法修改,有效利用非专家数据增强模仿学习策略的鲁棒性。
- 实验表明,该方法显著提升了策略在操作任务中的恢复能力和泛化性能,并能有效利用次优数据。
📝 摘要(中文)
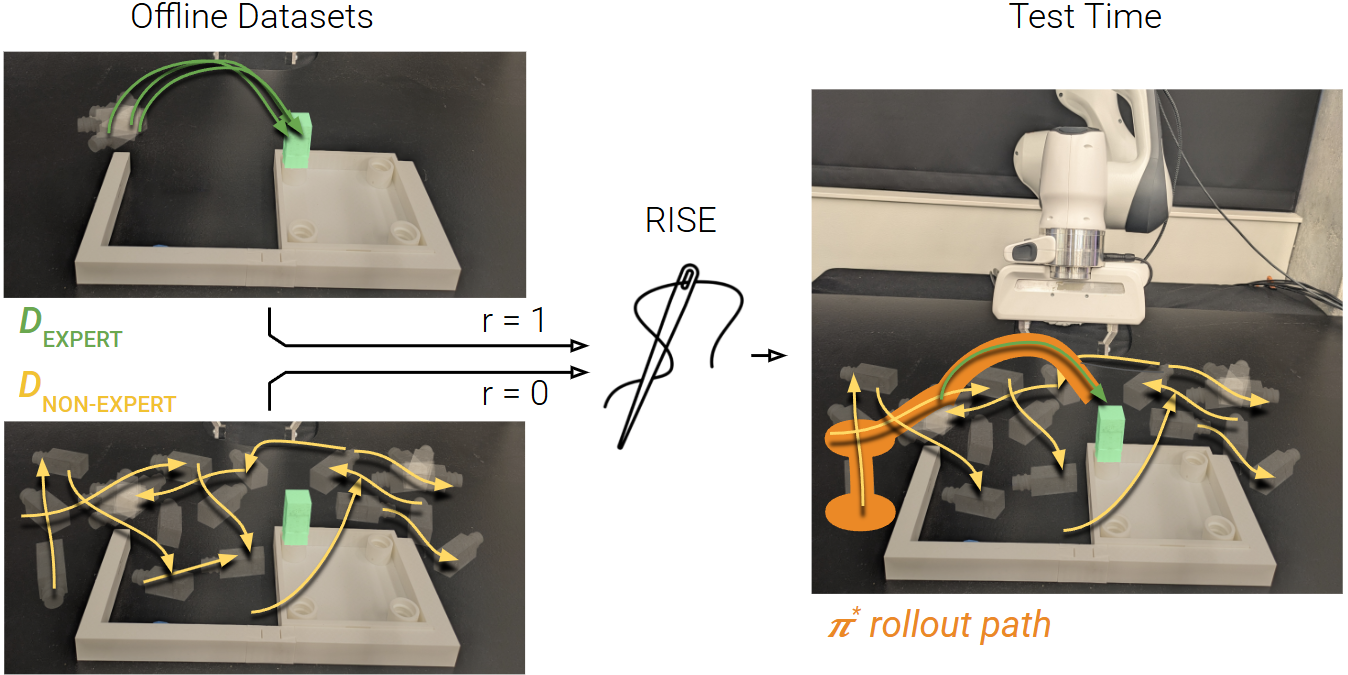
模仿学习在训练机器人执行复杂任务方面表现出色,但其对高质量、特定任务数据的依赖限制了其在真实世界中对各种物体配置和场景的适应性。非专家数据(如游戏数据、次优演示、部分任务完成或次优策略的rollout)可以提供更广泛的覆盖范围和更低的收集成本。然而,传统的模仿学习方法无法有效利用这些数据。本文提出,通过合理的设计,离线强化学习可以作为一种工具,利用非专家数据来增强模仿学习策略的性能。研究表明,标准的离线强化学习方法在真实世界中遇到的稀疏数据覆盖设置下,无法有效地利用非专家数据,但简单的算法修改可以在不需要额外假设的情况下利用这些数据。该方法通过拓宽策略分布的支持,使通过离线强化学习增强的模仿算法能够稳健地解决任务,从而显著增强恢复和泛化能力。在操作任务中,这些创新显著增加了学习策略在纳入非专家数据时成功的初始条件范围。此外,研究表明这些方法能够利用所有收集的数据,包括部分或次优演示,以支持任务导向的策略性能。这突显了使用非专家数据进行机器人鲁棒策略学习的算法技术的重要性。
🔬 方法详解
问题定义:模仿学习依赖于高质量的专家数据,这限制了它在真实世界复杂环境中的应用。收集高质量专家数据成本高昂,且难以覆盖所有可能的场景和状态。因此,如何利用更容易获取的非专家数据(如次优演示、部分完成的任务等)来提升模仿学习的鲁棒性和泛化能力是一个关键问题。
核心思路:论文的核心思路是利用离线强化学习(Offline RL)来处理非专家数据。离线强化学习可以在不与环境交互的情况下,仅通过离线数据集学习策略。通过对离线强化学习算法进行适当的修改,使其能够有效利用非专家数据中包含的丰富信息,从而增强模仿学习策略的性能。核心在于扩大策略分布的支持,使其能够覆盖非专家数据中的状态空间。
技术框架:该方法首先使用模仿学习从专家数据中初始化一个策略。然后,利用离线强化学习算法,结合专家数据和非专家数据,对策略进行进一步的优化。关键在于对离线强化学习算法进行修改,使其能够更好地处理非专家数据。具体来说,论文可能采用了某种形式的策略约束或正则化,以防止策略过度偏离专家数据,同时允许策略探索非专家数据中的状态空间。整体流程包括数据收集(专家数据和非专家数据)、策略初始化(模仿学习)和策略优化(离线强化学习)。
关键创新:该论文的关键创新在于提出了一种利用离线强化学习来增强模仿学习鲁棒性的方法,特别是在非专家数据可用时。与传统的模仿学习方法相比,该方法能够有效地利用非专家数据,从而提高策略的泛化能力和鲁棒性。与标准的离线强化学习方法相比,该方法通过算法修改,使其能够更好地处理非专家数据,避免了因数据质量差而导致的性能下降。
关键设计:论文的关键设计可能包括:1) 特定的离线强化学习算法选择(例如,Conservative Q-Learning (CQL) 或 Behavior Cloning with Perturbation (BCP));2) 用于约束策略分布的正则化项或损失函数;3) 用于平衡专家数据和非专家数据贡献的权重参数;4) 策略网络结构的设计,例如,使用更大的网络容量来更好地拟合非专家数据;5) 数据增强技术,例如,通过对非专家数据进行扰动来增加数据的多样性。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法能够显著提高模仿学习策略的鲁棒性和泛化能力。在操作任务中,与传统的模仿学习方法相比,该方法能够显著增加策略成功的初始条件范围。此外,该方法能够有效地利用次优演示数据,进一步提升策略的性能。具体性能数据(例如,成功率、完成时间等)和对比基线(例如,Behavior Cloning, Dagger)的详细信息需要在论文中查找。
🎯 应用场景
该研究成果可广泛应用于机器人操作、自动驾驶、游戏AI等领域。通过利用低成本的非专家数据,可以显著降低训练机器人的成本,并提高机器人在复杂环境中的适应能力。例如,在工业机器人领域,可以利用工人操作的记录数据来优化机器人的运动轨迹,提高生产效率。在自动驾驶领域,可以利用普通驾驶员的驾驶数据来增强自动驾驶系统的鲁棒性,提高安全性。
📄 摘要(原文)
Imitation learning has proven effective for training robots to perform complex tasks from expert human demonstrations. However, it remains limited by its reliance on high-quality, task-specific data, restricting adaptability to the diverse range of real-world object configurations and scenarios. In contrast, non-expert data -- such as play data, suboptimal demonstrations, partial task completions, or rollouts from suboptimal policies -- can offer broader coverage and lower collection costs. However, conventional imitation learning approaches fail to utilize this data effectively. To address these challenges, we posit that with right design decisions, offline reinforcement learning can be used as a tool to harness non-expert data to enhance the performance of imitation learning policies. We show that while standard offline RL approaches can be ineffective at actually leveraging non-expert data under the sparse data coverage settings typically encountered in the real world, simple algorithmic modifications can allow for the utilization of this data, without significant additional assumptions. Our approach shows that broadening the support of the policy distribution can allow imitation algorithms augmented by offline RL to solve tasks robustly, showing considerably enhanced recovery and generalization behavior. In manipulation tasks, these innovations significantly increase the range of initial conditions where learned policies are successful when non-expert data is incorporated. Moreover, we show that these methods are able to leverage all collected data, including partial or suboptimal demonstrations, to bolster task-directed policy performance. This underscores the importance of algorithmic techniques for using non-expert data for robust policy learning in robotics. Website: https://uwrobotlearning.github.io/RISE-offline/