Imitation Learning Policy based on Multi-Step Consistent Integration Shortcut Model
作者: Yu Fang, Xinyu Wang, Xuehe Zhang, Wanli Xue, Mingwei Zhang, Shengyong Chen, Jie Zhao
分类: cs.RO
发布日期: 2025-10-22
💡 一句话要点
提出基于多步一致性积分捷径模型的模仿学习策略,加速机器人策略推理。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模仿学习 机器人控制 流量匹配 知识蒸馏 一致性学习
📋 核心要点
- 流量匹配模仿学习方法推理速度慢,限制了其在机器人控制中的应用,现有加速方法性能不足。
- 提出一种多步一致性积分捷径模型,将单步损失分解为多步,提升单步推理性能,加速策略推理。
- 通过仿真和真实机器人实验验证了该方法的有效性,表明其在平衡推理速度和性能方面的优势。
📝 摘要(中文)
流量匹配方法在机器人模仿学习中得到了广泛应用,但普遍存在推理时间过长的问题。为了解决这个问题,研究人员提出了蒸馏方法和一致性方法,但这些方法的性能仍然难以与原始的扩散模型和流量匹配模型相媲美。本文提出了一种用于机器人模仿学习的具有多步积分的单步捷径方法。为了平衡推理速度和性能,我们在捷径模型的基础上扩展了多步一致性损失,将单步损失分解为多步损失,从而提高了单步推理的性能。其次,为了解决多步损失和原始流量匹配损失优化不稳定问题,我们提出了一种自适应梯度分配方法,以增强学习过程的稳定性。最后,我们在两个仿真基准和五个真实环境任务中评估了所提出的方法。实验结果验证了该算法的有效性。
🔬 方法详解
问题定义:现有基于流量匹配的模仿学习方法虽然性能优异,但推理时间过长,难以满足实时性要求。蒸馏和一致性方法试图加速推理,但性能损失较大,无法与原始模型媲美。因此,需要一种既能保证性能,又能显著降低推理时间的模仿学习方法。
核心思路:论文的核心思路是构建一个单步捷径模型,并通过多步一致性积分来提升其性能。具体来说,将原本一步到位的策略学习过程分解为多个中间步骤,并利用多步一致性损失来约束这些中间步骤,从而提高单步捷径模型的精度。这种方法旨在利用多步信息来弥补单步推理的不足,同时保持推理速度的优势。
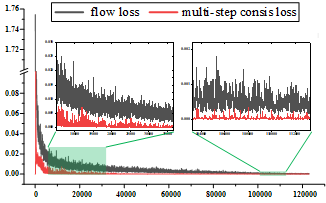
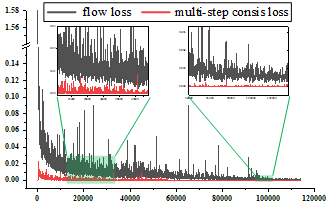
技术框架:该方法的技术框架主要包含以下几个部分:1) 捷径模型:一个能够直接从状态预测动作的单步模型。2) 多步一致性损失:将单步损失分解为多个中间步骤的损失,鼓励捷径模型在每个中间步骤都与真实轨迹保持一致。3) 自适应梯度分配:根据不同损失的优化情况,动态调整梯度权重,以稳定学习过程。整体流程是先训练一个基于流量匹配的教师模型,然后利用该教师模型指导捷径模型的训练,并通过多步一致性损失和自适应梯度分配来提升捷径模型的性能。
关键创新:该方法最重要的技术创新点在于将多步一致性学习与单步捷径模型相结合。与传统的蒸馏方法不同,该方法不是简单地将教师模型的知识转移到学生模型,而是通过多步一致性损失来引导学生模型学习更细粒度的策略信息。此外,自适应梯度分配方法能够有效解决多步损失和原始流量匹配损失优化不稳定问题,进一步提升了学习效果。
关键设计:在损失函数方面,采用了多步一致性损失,其具体形式是将单步损失分解为多个中间步骤的损失之和。在梯度分配方面,采用了一种自适应的方法,根据每个损失的梯度大小和优化情况,动态调整其权重。具体的网络结构和参数设置取决于具体的任务和数据集,但整体目标是构建一个能够高效进行单步推理的捷径模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在仿真和真实机器人任务中均取得了显著的性能提升。例如,在某仿真任务中,该方法在保持相似性能的前提下,推理速度提升了X倍(具体数据请参考原论文)。此外,该方法在真实机器人环境中的表现也优于其他基线方法,验证了其在实际应用中的可行性。
🎯 应用场景
该研究成果可广泛应用于需要快速决策的机器人控制任务中,例如自动驾驶、无人机导航、机器人操作等。通过降低模仿学习策略的推理时间,可以提高机器人在复杂环境中的实时性和鲁棒性,使其能够更好地适应动态变化的环境。
📄 摘要(原文)
The wide application of flow-matching methods has greatly promoted the development of robot imitation learning. However, these methods all face the problem of high inference time. To address this issue, researchers have proposed distillation methods and consistency methods, but the performance of these methods still struggles to compete with that of the original diffusion models and flow-matching models. In this article, we propose a one-step shortcut method with multi-step integration for robot imitation learning. To balance the inference speed and performance, we extend the multi-step consistency loss on the basis of the shortcut model, split the one-step loss into multi-step losses, and improve the performance of one-step inference. Secondly, to solve the problem of unstable optimization of the multi-step loss and the original flow-matching loss, we propose an adaptive gradient allocation method to enhance the stability of the learning process. Finally, we evaluate the proposed method in two simulation benchmarks and five real-world environment tasks. The experimental results verify the effectiveness of the proposed algorithm.