Hierarchical DLO Routing with Reinforcement Learning and In-Context Vision-language Models
作者: Mingen Li, Houjian Yu, Yixuan Huang, Youngjin Hong, Changhyun Choi
分类: cs.RO, cs.LG
发布日期: 2025-10-22
备注: 8 pages, 6 figures, 3 tables
💡 一句话要点
提出层次化DLO路由框架以解决长时间规划问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 可变形线性物体 长时间路由 视觉-语言模型 强化学习 层次化框架 机器人技术 高层次推理
📋 核心要点
- 长时间路由任务的复杂性在于需要机器人进行高层次推理和多步骤计划,现有方法在这方面存在不足。
- 本文提出的框架结合视觉-语言模型和强化学习,能够在给定语言目标的情况下自动生成和执行路由计划。
- 实验结果显示,该方法在长时间路由场景中的成功率达到92.5%,比最佳基线方法提升近50%。
📝 摘要(中文)
可变形线性物体(DLO)如电缆和绳索的长时间路由任务在工业装配线和日常生活中十分常见。这些任务具有挑战性,因为它们要求机器人在执行过程中进行长时间规划和可靠的技能执行。成功完成这些任务需要适应非线性动态,分解抽象路由目标,并生成由多项技能组成的多步骤计划。本文提出了一种完全自主的层次化框架,利用视觉-语言模型进行高层次推理,合成可行计划,并通过强化学习训练低层次技能。为提高长时间任务的鲁棒性,我们还引入了失败恢复机制,将DLO重新定向至可插入状态。该方法在多种场景中表现出色,成功率达到92.5%。
🔬 方法详解
问题定义:本文旨在解决可变形线性物体(DLO)在长时间路由任务中的规划与执行问题。现有方法往往无法有效处理复杂的非线性动态和高层次推理,导致成功率低下。
核心思路:提出的层次化框架通过结合视觉-语言模型进行高层次推理,生成可行的多步骤计划,并利用强化学习训练低层次技能,从而实现自主执行。
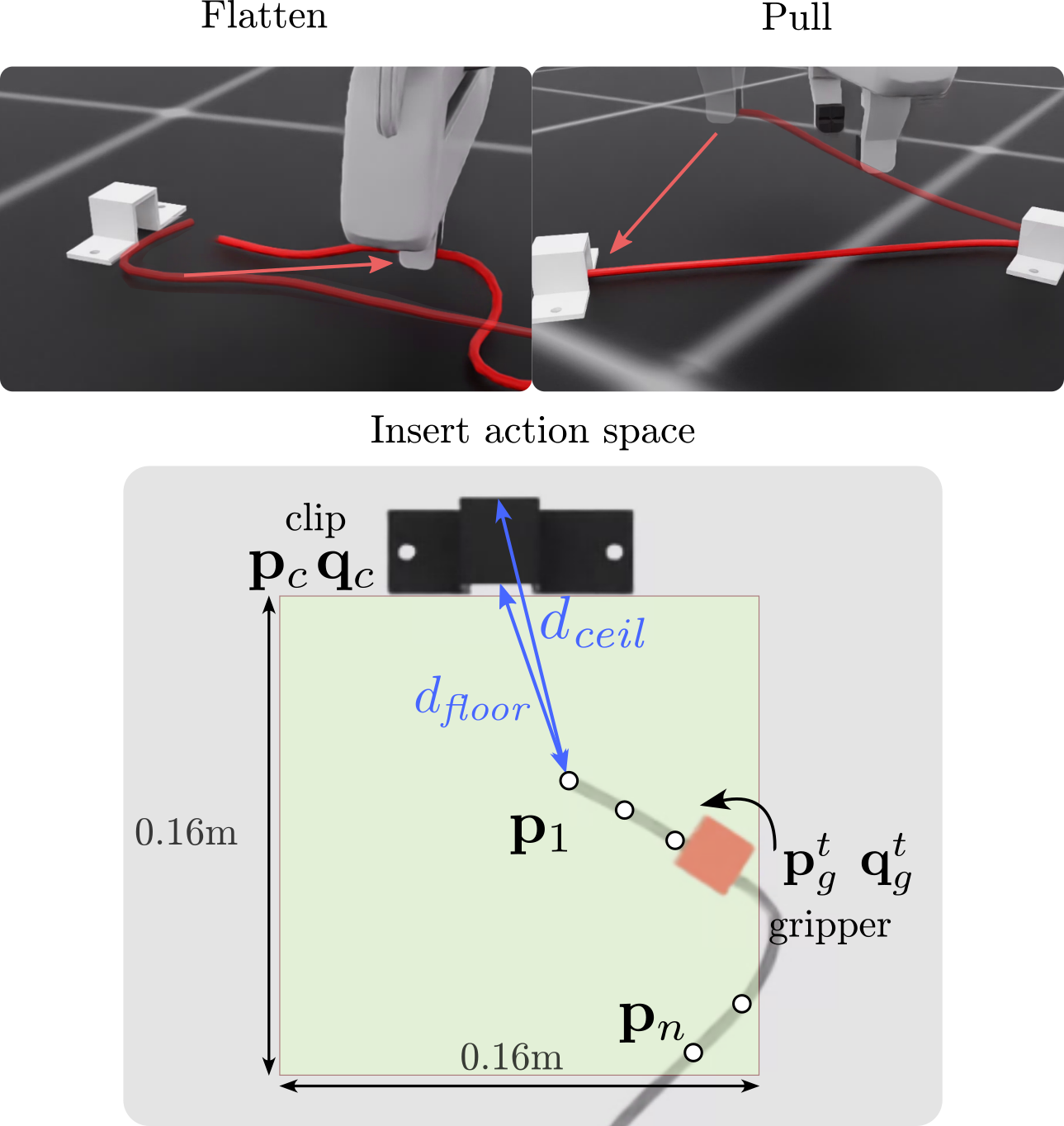
技术框架:整体架构包括三个主要模块:首先,输入的路由目标通过视觉-语言模型进行解析和推理;其次,生成的高层次计划被分解为低层次技能;最后,执行过程中通过强化学习优化技能表现,并引入失败恢复机制。
关键创新:最重要的创新在于将视觉-语言模型与强化学习相结合,实现了高层次推理与低层次技能执行的有效协同,显著提高了任务的成功率和鲁棒性。
关键设计:在设计中,采用了特定的损失函数来平衡高层次推理与低层次执行的目标,同时在强化学习中使用了自适应学习率以提高训练效率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,提出的方法在长时间路由任务中的成功率达到92.5%,相比最佳基线方法提升近50%。这一显著的性能提升展示了框架在复杂场景中的有效性和鲁棒性。
🎯 应用场景
该研究的潜在应用领域包括工业自动化、机器人装配、智能家居等场景,能够有效提升机器人在复杂环境中的操作能力和灵活性。未来,该框架有望扩展到更多类型的物体操作任务,推动智能机器人技术的发展。
📄 摘要(原文)
Long-horizon routing tasks of deformable linear objects (DLOs), such as cables and ropes, are common in industrial assembly lines and everyday life. These tasks are particularly challenging because they require robots to manipulate DLO with long-horizon planning and reliable skill execution. Successfully completing such tasks demands adapting to their nonlinear dynamics, decomposing abstract routing goals, and generating multi-step plans composed of multiple skills, all of which require accurate high-level reasoning during execution. In this paper, we propose a fully autonomous hierarchical framework for solving challenging DLO routing tasks. Given an implicit or explicit routing goal expressed in language, our framework leverages vision-language models~(VLMs) for in-context high-level reasoning to synthesize feasible plans, which are then executed by low-level skills trained via reinforcement learning. To improve robustness in long horizons, we further introduce a failure recovery mechanism that reorients the DLO into insertion-feasible states. Our approach generalizes to diverse scenes involving object attributes, spatial descriptions, as well as implicit language commands. It outperforms the next best baseline method by nearly 50% and achieves an overall success rate of 92.5% across long-horizon routing scenarios.