Online Object-Level Semantic Mapping for Quadrupeds in Real-World Environments
作者: Emad Razavi, Angelo Bratta, João Carlos Virgolino Soares, Carmine Recchiuto, Claudio Semini
分类: cs.RO
发布日期: 2025-10-21
备注: Published at the Italian Conference on Robotics and Intelligent Machines (I-RIM) 3D, 2025
💡 一句话要点
针对四足机器人,提出一种实时的、对象级别的语义地图构建方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 四足机器人 语义地图 对象级别 在线构建 传感器融合
📋 核心要点
- 现有方法难以在四足机器人上构建稳定、持久的对象级别语义地图,尤其是在动态和遮挡环境中。
- 该方法融合深度信息和视觉检测,通过时序关联维持对象实例,即使对象暂时离开视野也能保持追踪。
- 在真实机器人平台上验证了该方法的有效性,结果表明该方法能构建稳定的、可用于规划的对象层。
📝 摘要(中文)
本文提出了一种用于四足机器人在真实室内环境中运行的在线语义对象地图构建系统,该系统将传感器检测结果转换为全局地图中已命名的对象。在运行过程中,该映射器集成了深度几何信息与相机检测结果,合并了单帧中共定位的检测结果,并将跨帧的重复检测关联到持久的对象实例。当对象超出视野时,它们仍保留在地图中,并且重复的观测会更新相同的实例,而不是创建重复项。输出是一个紧凑的对象层,可以查询(类别、姿态和置信度),与占据栅格地图集成,并且可以被规划器读取。在机器人上的测试中,该对象层在视角变化时保持稳定。
🔬 方法详解
问题定义:现有的语义地图构建方法在四足机器人应用中面临挑战,主要体现在两个方面:一是如何在动态环境中保持对象识别的鲁棒性,二是如何在视角变化和遮挡情况下维持对象实例的持久性。传统的基于单帧的语义地图容易产生重复的对象实例,且缺乏对对象历史信息的利用。
核心思路:本文的核心思路是将来自深度传感器和视觉传感器的信息进行融合,并引入时间上的关联机制。通过融合深度信息,可以更准确地估计对象的位置和大小。通过时间关联,可以将跨帧的观测结果关联到同一个对象实例,从而避免重复创建对象,并提高地图的稳定性。
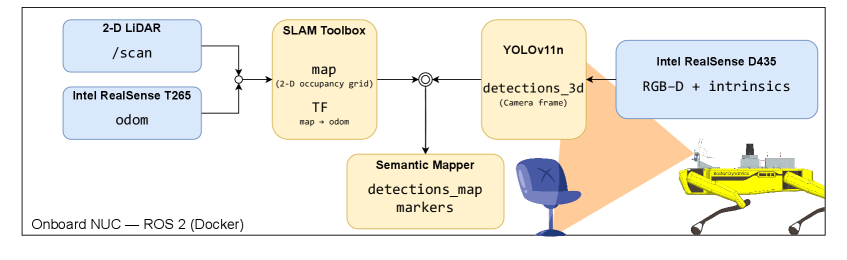
技术框架:该系统包含以下几个主要模块:1) 传感器数据获取:从深度相机和视觉相机获取数据。2) 对象检测:利用视觉检测器识别图像中的对象。3) 几何信息融合:将深度信息与视觉检测结果融合,估计对象在三维空间中的位置和大小。4) 对象关联:利用时间关联机制,将跨帧的观测结果关联到同一个对象实例。5) 地图构建:将对象实例添加到全局地图中,并维护地图的更新。
关键创新:该方法最重要的创新点在于其在线的对象级别语义地图构建框架,能够有效地融合深度信息和视觉检测结果,并利用时间关联机制维持对象实例的持久性。与现有方法相比,该方法能够更好地处理动态环境和视角变化带来的挑战,从而构建更稳定、更可靠的语义地图。
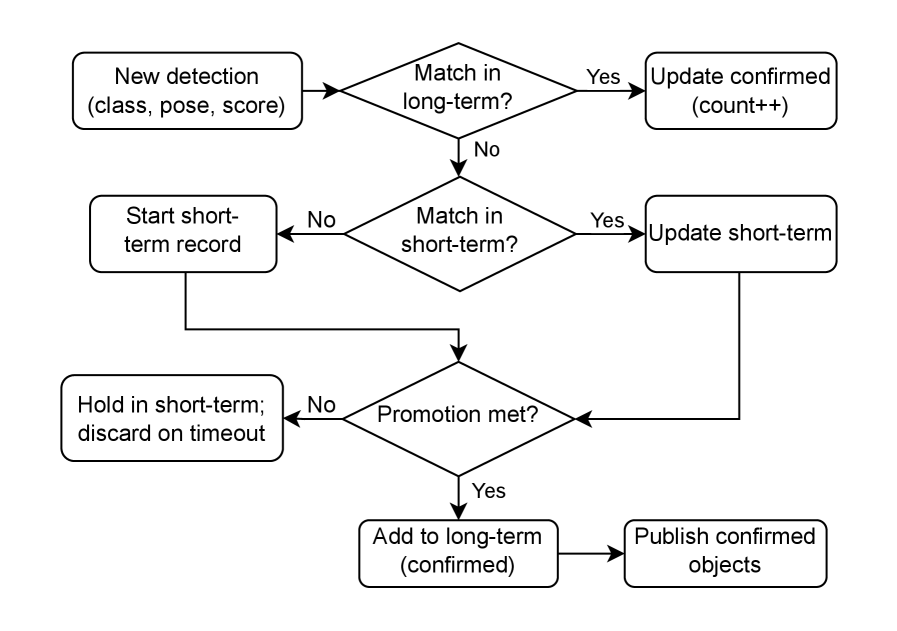
关键设计:在对象关联模块中,使用了基于距离和类别相似度的关联算法。具体来说,对于每一帧新检测到的对象,系统会搜索地图中已存在的对象实例,如果存在距离足够近且类别相同的对象实例,则将新的观测结果关联到该实例。此外,系统还维护了一个置信度值,用于表示对象实例的可靠程度。每次观测到对象实例时,其置信度值会增加;如果长时间没有观测到对象实例,其置信度值会降低。当置信度值低于某个阈值时,该对象实例会被从地图中移除。
🖼️ 关键图片

📊 实验亮点
该方法在真实机器人平台上进行了验证,结果表明该方法能够构建稳定的、可用于规划的对象层。即使在视角变化和遮挡情况下,该方法也能有效地维持对象实例的持久性。实验结果表明,该方法能够显著减少重复对象实例的产生,并提高地图的整体质量。
🎯 应用场景
该研究成果可应用于四足机器人的自主导航、环境理解和人机交互等领域。例如,机器人可以利用语义地图进行目标导向的导航,理解周围环境中的物体,并与人进行更自然的交互。此外,该技术还可以扩展到其他类型的移动机器人和增强现实应用中。
📄 摘要(原文)
We present an online semantic object mapping system for a quadruped robot operating in real indoor environments, turning sensor detections into named objects in a global map. During a run, the mapper integrates range geometry with camera detections, merges co-located detections within a frame, and associates repeated detections into persistent object instances across frames. Objects remain in the map when they are out of view, and repeated sightings update the same instance rather than creating duplicates. The output is a compact object layer that can be queried (class, pose, and confidence), is integrated with the occupancy map and readable by a planner. In on-robot tests, the layer remained stable across viewpoint changes.