Efficient Model-Based Reinforcement Learning for Robot Control via Online Learning
作者: Fang Nan, Hao Ma, Qinghua Guan, Josie Hughes, Michael Muehlebach, Marco Hutter
分类: cs.RO
发布日期: 2025-10-21
💡 一句话要点
提出一种高效的在线模型强化学习算法,用于直接控制复杂机器人系统。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模型强化学习 在线学习 机器人控制 动力学建模 样本效率
📋 核心要点
- 现有sim-to-real方法依赖大量离线仿真,存在仿真偏差,限制了真实机器人控制策略的性能。
- 该方法提出在线模型强化学习,从真实交互数据构建动力学模型,指导策略更新,减少样本需求。
- 实验表明,该算法在液压挖掘机臂和软机器人臂上具有高样本效率,并能适应动态变化。
📝 摘要(中文)
本文提出了一种在线模型强化学习算法,适用于直接在真实环境中控制复杂的机器人系统。与依赖大量离线仿真和无模型策略优化的传统sim-to-real流程不同,我们的方法从实时交互数据中构建动力学模型,并利用学习到的动力学模型指导策略更新。这种高效的基于模型的强化学习方案显著减少了训练控制策略所需的样本数量,从而可以直接在真实世界的rollout数据上进行训练。这显著降低了仿真数据中的偏差影响,并有助于寻找高性能的控制策略。我们采用在线学习分析来推导标准随机在线优化假设下的次线性遗憾界限,为随着收集更多交互数据而带来的性能提升提供正式保证。在液压挖掘机臂和软机器人臂上进行的实验评估表明,该算法与无模型强化学习方法相比,具有很强的样本效率,并在数小时内达到可比的性能。当有效载荷条件随机化时,也观察到对动态变化的鲁棒适应性。我们的方法为广泛的具有挑战性的控制任务的高效和可靠的机器人学习铺平了道路。
🔬 方法详解
问题定义:现有机器人控制方法,特别是基于强化学习的方法,通常依赖于大量的仿真数据进行训练,然后将训练好的策略迁移到真实机器人上。这种sim-to-real的方法面临着仿真环境与真实环境之间的差异,导致策略在真实环境中性能下降。此外,无模型强化学习方法需要大量的真实世界样本,这在机器人控制中往往是不可行的,因为与真实环境的交互成本很高,且可能损坏机器人。
核心思路:本文的核心思路是在真实机器人上进行在线学习,通过与环境的实时交互来构建和更新动力学模型,并利用该模型来指导策略的优化。这种方法可以减少对仿真数据的依赖,并提高策略在真实环境中的性能。通过在线学习,模型可以不断适应真实环境的变化,从而提高控制策略的鲁棒性。
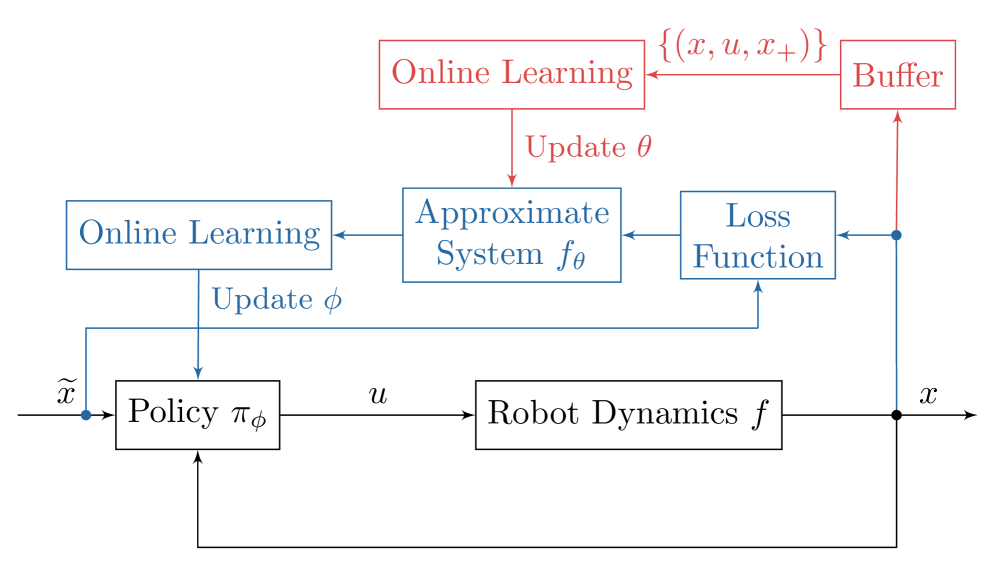
技术框架:该算法的整体框架包括以下几个主要模块:1) 数据采集模块:从真实机器人与环境的交互中收集数据,包括状态、动作和奖励等。2) 动力学模型学习模块:利用收集到的数据,在线学习机器人的动力学模型。3) 策略优化模块:利用学习到的动力学模型,进行策略优化,目标是最大化累积奖励。4) 策略执行模块:将优化后的策略应用到真实机器人上,进行控制。
关键创新:该方法最重要的创新点在于将模型学习和策略优化结合起来,并在真实机器人上进行在线学习。与传统的sim-to-real方法相比,该方法减少了对仿真数据的依赖,并提高了策略在真实环境中的性能。此外,该方法还采用了在线学习分析,为算法的性能提供了理论保证。
关键设计:在动力学模型学习方面,可以使用高斯过程回归或其他非参数模型来建模机器人的动力学。在策略优化方面,可以使用基于模型的策略梯度方法或模型预测控制等方法。关键参数包括模型学习率、策略更新步长、奖励函数的设计等。损失函数通常包括模型预测误差和策略的性能指标。
🖼️ 关键图片

📊 实验亮点
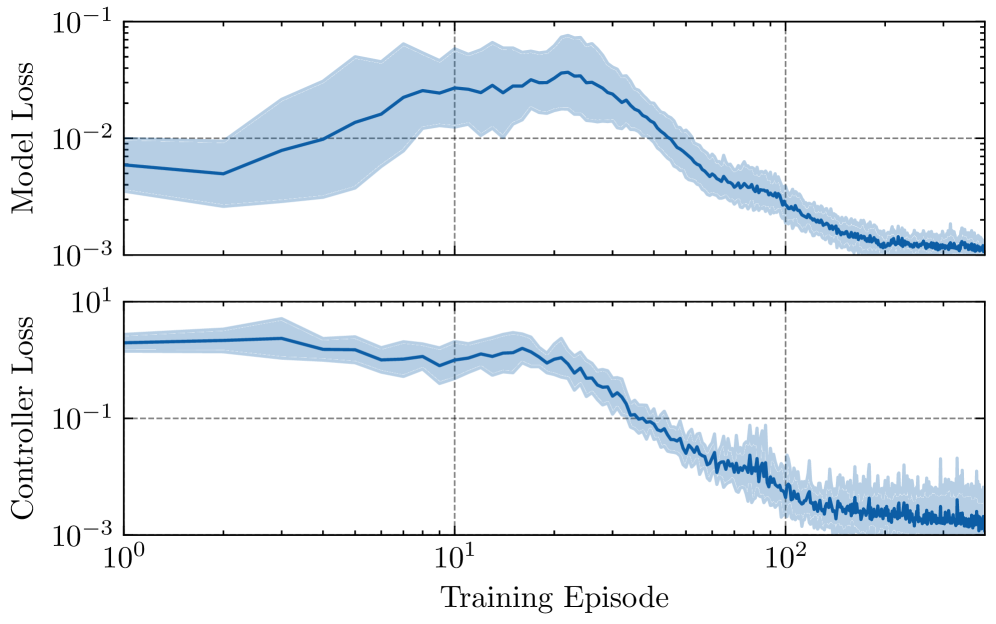
在液压挖掘机臂和软机器人臂上的实验结果表明,该算法与无模型强化学习方法相比,具有显著的样本效率优势,在数小时内即可达到可比的性能水平。此外,当有效载荷条件随机化时,该算法表现出对动态变化的鲁棒适应性,验证了其在实际应用中的潜力。
🎯 应用场景
该研究成果可广泛应用于各种复杂机器人系统的控制,例如工业机器人、服务机器人、医疗机器人和无人驾驶车辆等。通过在线学习,机器人可以不断适应环境变化,提高控制精度和鲁棒性,从而实现更高效、更安全的人机协作。该方法还有助于降低机器人开发的成本和周期,加速机器人在各个领域的应用。
📄 摘要(原文)
We present an online model-based reinforcement learning algorithm suitable for controlling complex robotic systems directly in the real world. Unlike prevailing sim-to-real pipelines that rely on extensive offline simulation and model-free policy optimization, our method builds a dynamics model from real-time interaction data and performs policy updates guided by the learned dynamics model. This efficient model-based reinforcement learning scheme significantly reduces the number of samples to train control policies, enabling direct training on real-world rollout data. This significantly reduces the influence of bias in the simulated data, and facilitates the search for high-performance control policies. We adopt online learning analysis to derive sublinear regret bounds under standard stochastic online optimization assumptions, providing formal guarantees on performance improvement as more interaction data are collected. Experimental evaluations were performed on a hydraulic excavator arm and a soft robot arm, where the algorithm demonstrates strong sample efficiency compared to model-free reinforcement learning methods, reaching comparable performance within hours. Robust adaptation to shifting dynamics was also observed when the payload condition was randomized. Our approach paves the way toward efficient and reliable on-robot learning for a broad class of challenging control tasks.