PGTT: Phase-Guided Terrain Traversal for Perceptive Legged Locomotion
作者: Alexandros Ntagkas, Chairi Kiourt, Konstantinos Chatzilygeroudis
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-21
备注: 9 pages, 9 figures, 2 tables
💡 一句话要点
PGTT:基于相位引导的地形遍历方法,提升感知型足式机器人运动的鲁棒性。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 足式机器人 强化学习 地形遍历 相位引导 奖励塑造 深度学习 机器人控制
📋 核心要点
- 现有足式机器人强化学习控制器依赖步态先验或“盲目”运动,限制了适应性和鲁棒性。
- PGTT通过奖励塑造来引导步态结构,减少了对步态先验的依赖,提升了地形适应性。
- 实验表明,PGTT在复杂地形和扰动下表现出色,且训练收敛速度更快,并成功部署到真实机器人。
📝 摘要(中文)
本文提出了一种名为相位引导地形遍历(PGTT)的感知型深度强化学习方法,旨在克服现有足式机器人控制器的局限性。现有方法要么依赖于振荡器或逆运动学(IK)的步态先验,限制了动作空间并增加了策略优化的偏差,降低了机器人形态的适应性;要么“盲目”操作,难以预测后腿地形,且对噪声敏感。PGTT通过奖励塑造来强制执行步态结构,从而减少了策略学习中的归纳偏差。PGTT将每条腿的相位编码为三次Hermite样条,该样条根据局部高度图统计信息调整摆动高度,并增加摆动相位接触惩罚,同时策略直接在关节空间中执行动作,支持与形态无关的部署。在MuJoCo(MJX)中,通过课程学习和领域随机化在程序生成的阶梯状地形上进行训练,PGTT在推力扰动下(中位数+7.5% vs. 次优方法)和离散障碍物上(+9%)取得了最高的成功率,同时具有相当的速度跟踪性能,并且收敛到有效策略的速度比强大的端到端基线快大约2倍。我们在Unitree Go2上使用实时LiDAR高程到高度图的流水线验证了PGTT,并报告了使用相同超参数在ANYmal-C上获得的初步结果。这些发现表明,地形自适应的相位引导奖励塑造是跨平台实现鲁棒感知运动的一种简单而通用的机制。
🔬 方法详解
问题定义:现有感知型足式机器人控制器面临的挑战在于,要么依赖于振荡器或逆运动学等步态先验,限制了动作空间和形态适应性;要么直接进行端到端学习,但难以预测后腿地形,对噪声敏感,鲁棒性较差。这些方法在复杂地形和扰动下的表现往往不尽如人意。
核心思路:PGTT的核心思路是通过奖励塑造来引导机器人学习合适的步态,而不是直接施加步态先验。通过精心设计的奖励函数,鼓励机器人学习地形自适应的运动模式,同时避免了对特定机器人形态的限制。这种方法旨在提高机器人在复杂环境中的鲁棒性和适应性。
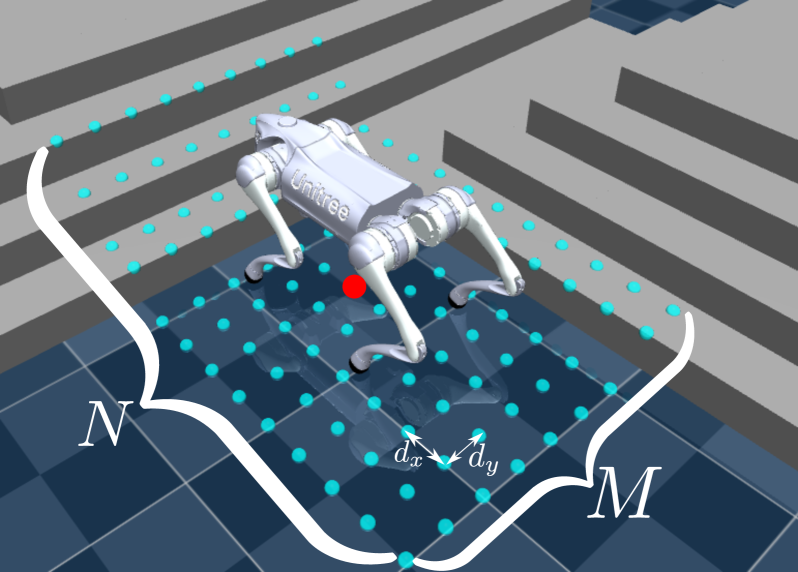
技术框架:PGTT的整体框架包括以下几个主要模块:1) 感知模块:利用LiDAR等传感器获取环境的高度图信息。2) 相位编码模块:将每条腿的运动相位编码为三次Hermite样条,用于控制腿的摆动高度。3) 奖励塑造模块:设计奖励函数,包括前进奖励、接触惩罚、姿态稳定奖励等,引导机器人学习期望的运动行为。4) 强化学习策略优化模块:使用深度强化学习算法(如PPO)优化机器人的控制策略,使其能够在复杂地形上稳定行走。
关键创新:PGTT的关键创新在于使用相位引导的奖励塑造来学习步态,而不是依赖于传统的步态先验。这种方法减少了策略学习中的归纳偏差,提高了机器人在不同地形和机器人形态下的适应性。此外,PGTT还通过自适应调整摆动高度来更好地适应地形变化。
关键设计:PGTT的关键设计包括:1) 使用三次Hermite样条来编码腿的运动相位,允许平滑地调整摆动高度。2) 设计摆动相位接触惩罚,避免腿在摆动过程中与地形发生碰撞。3) 使用课程学习和领域随机化来提高策略的泛化能力。4) 策略网络直接输出关节空间的控制指令,避免了逆运动学计算的误差。
🖼️ 关键图片


📊 实验亮点
PGTT在仿真实验中表现出色,在推力扰动下成功率比次优方法高7.5%,在离散障碍物上成功率高9%。此外,PGTT的训练收敛速度比端到端基线快2倍。真实机器人实验表明,PGTT能够成功部署到Unitree Go2和ANYmal-C上,验证了其在真实环境中的可行性和有效性。
🎯 应用场景
PGTT技术可应用于各种足式机器人,使其能够在复杂地形(如灾后救援现场、崎岖山地)中稳定行走。该技术具有广泛的应用前景,例如:搜救机器人、物流机器人、巡检机器人等。通过提高足式机器人的地形适应性和鲁棒性,可以使其在更多实际场景中发挥作用,解决人类难以到达或危险的作业任务。
📄 摘要(原文)
State-of-the-art perceptive Reinforcement Learning controllers for legged robots either (i) impose oscillator or IK-based gait priors that constrain the action space, add bias to the policy optimization and reduce adaptability across robot morphologies, or (ii) operate "blind", which struggle to anticipate hind-leg terrain, and are brittle to noise. In this paper, we propose Phase-Guided Terrain Traversal (PGTT), a perception-aware deep-RL approach that overcomes these limitations by enforcing gait structure purely through reward shaping, thereby reducing inductive bias in policy learning compared to oscillator/IK-conditioned action priors. PGTT encodes per-leg phase as a cubic Hermite spline that adapts swing height to local heightmap statistics and adds a swing-phase contact penalty, while the policy acts directly in joint space supporting morphology-agnostic deployment. Trained in MuJoCo (MJX) on procedurally generated stair-like terrains with curriculum and domain randomization, PGTT achieves the highest success under push disturbances (median +7.5% vs. the next best method) and on discrete obstacles (+9%), with comparable velocity tracking, and converging to an effective policy roughly 2x faster than strong end-to-end baselines. We validate PGTT on a Unitree Go2 using a real-time LiDAR elevation-to-heightmap pipeline, and we report preliminary results on ANYmal-C obtained with the same hyperparameters. These findings indicate that terrain-adaptive, phase-guided reward shaping is a simple and general mechanism for robust perceptive locomotion across platforms.