MoTVLA: A Vision-Language-Action Model with Unified Fast-Slow Reasoning
作者: Wenhui Huang, Changhe Chen, Han Qi, Chen Lv, Yilun Du, Heng Yang
分类: cs.RO
发布日期: 2025-10-21 (更新: 2025-10-23)
💡 一句话要点
提出MoTVLA模型,融合快慢推理,提升机器人视觉-语言-动作策略的语言可控性和效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 机器人控制 快慢推理 混合Transformer 语言可控性
📋 核心要点
- 现有方法在将视觉-语言指令集成到机器人策略中时,面临语言可控性不足或推理延迟过高的问题。
- MoTVLA模型通过混合Transformer结构,融合通用VLM的慢推理和领域专家的快推理,提升策略执行效率。
- 实验结果表明,MoTVLA在语言可控性、推理速度和操作任务性能方面均优于现有方法。
📝 摘要(中文)
本文提出了一种基于混合Transformer(MoT)的视觉-语言-动作(VLA)模型MoTVLA,它集成了快慢统一推理与行为策略学习。MoTVLA保留了预训练VLM的通用智能(作为通用专家),用于感知、场景理解和语义规划等任务,同时引入了一个领域专家,即与预训练VLM共享知识的第二个Transformer,以生成特定领域的快速推理(例如,机器人运动分解),从而提高策略执行效率。通过将动作专家建立在分解的运动指令之上,MoTVLA可以学习多样化的行为,并显著提高语言可控性。在自然语言处理基准、机器人仿真环境和真实世界实验中的广泛评估证实了MoTVLA在快慢推理和操作任务性能方面的优越性。
🔬 方法详解
问题定义:现有基于视觉-语言的机器人控制方法,要么依赖于直接的视觉-语言映射,缺乏语言指令的细粒度控制;要么引入推理模块,但推理过程耗时,导致执行延迟,难以满足实时性要求。因此,如何在保证语言可控性的同时,提高策略执行效率,是一个亟待解决的问题。
核心思路:MoTVLA的核心思路是将通用视觉-语言模型的通用知识与特定领域的快速推理能力相结合。通过混合Transformer结构,利用预训练VLM进行高层次的语义理解和规划(慢推理),同时引入一个领域专家Transformer进行快速的运动分解和动作生成(快推理)。
技术框架:MoTVLA模型包含三个主要模块:预训练的视觉-语言模型(VLM)、领域专家Transformer和动作专家。VLM负责处理视觉和语言输入,进行场景理解和语义规划。领域专家Transformer与VLM共享知识,负责将VLM的输出分解为具体的运动指令。动作专家根据分解的运动指令生成最终的机器人动作。整个框架采用端到端的方式进行训练。
关键创新:MoTVLA的关键创新在于其快慢推理的融合机制。通过将通用VLM的慢推理与领域专家的快推理相结合,实现了语言可控性和执行效率的平衡。领域专家Transformer的设计,使得模型能够学习到特定领域的快速推理能力,从而提高策略执行效率。
关键设计:MoTVLA的关键设计包括:1) 领域专家Transformer与VLM共享知识,加速领域知识的学习;2) 动作专家以分解的运动指令为条件,提高语言可控性;3) 采用混合Transformer结构,实现快慢推理的并行执行;4) 损失函数包括行为克隆损失、语言指令损失和运动分解损失,确保模型能够学习到正确的行为策略和运动分解方式。
🖼️ 关键图片
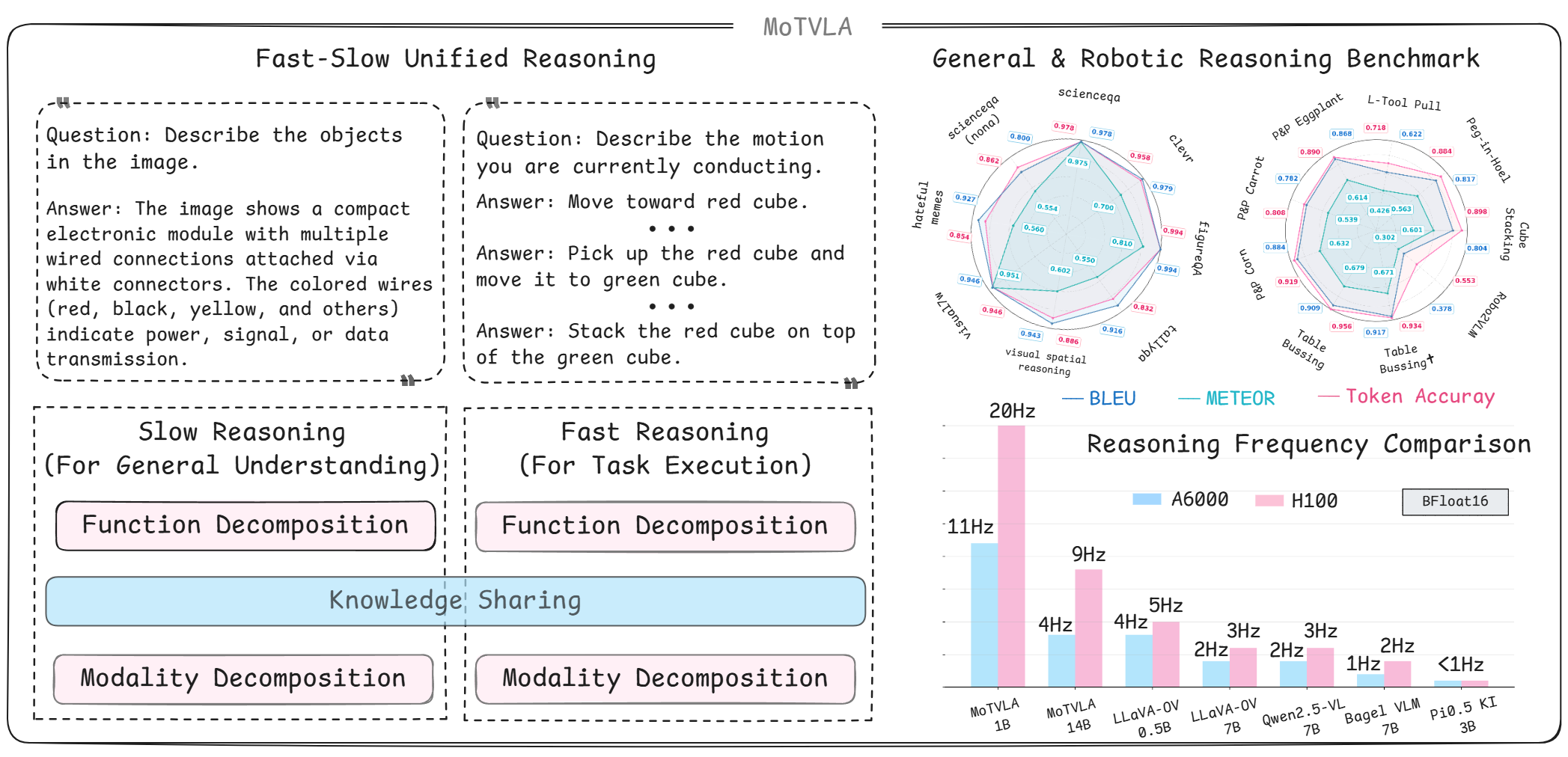
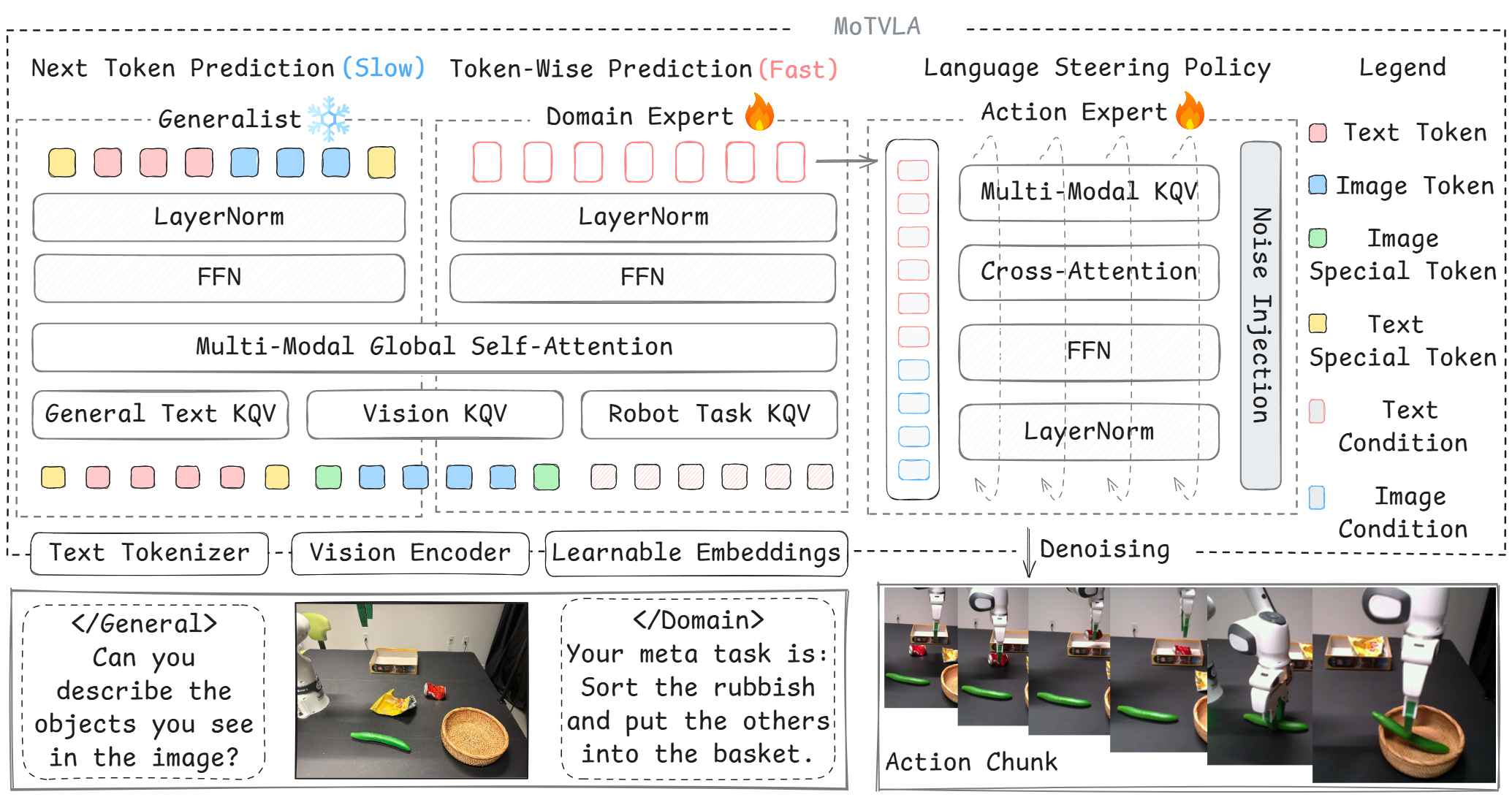

📊 实验亮点
实验结果表明,MoTVLA模型在自然语言处理基准测试中取得了优异的性能,在机器人仿真环境中显著提高了任务完成率和执行效率,并在真实世界实验中验证了其有效性。相较于现有方法,MoTVLA在语言可控性和执行效率方面均有显著提升。
🎯 应用场景
MoTVLA模型可应用于各种需要视觉-语言指导的机器人操作任务,例如家庭服务机器人、工业机器人、医疗机器人等。该模型能够使机器人更好地理解人类指令,并高效地完成复杂的操作任务,具有广阔的应用前景。
📄 摘要(原文)
Integrating visual-language instructions into visuomotor policies is gaining momentum in robot learning for enhancing open-world generalization. Despite promising advances, existing approaches face two challenges: limited language steerability when no generated reasoning is used as a condition, or significant inference latency when reasoning is incorporated. In this work, we introduce MoTVLA, a mixture-of-transformers (MoT)-based vision-language-action (VLA) model that integrates fast-slow unified reasoning with behavior policy learning. MoTVLA preserves the general intelligence of pre-trained VLMs (serving as the generalist) for tasks such as perception, scene understanding, and semantic planning, while incorporating a domain expert, a second transformer that shares knowledge with the pretrained VLM, to generate domain-specific fast reasoning (e.g., robot motion decomposition), thereby improving policy execution efficiency. By conditioning the action expert on decomposed motion instructions, MoTVLA can learn diverse behaviors and substantially improve language steerability. Extensive evaluations across natural language processing benchmarks, robotic simulation environments, and real-world experiments confirm the superiority of MoTVLA in both fast-slow reasoning and manipulation task performance.