Quality Over Quantity: Curating Contact-Based Robot Datasets Improves Learning
作者: Hrishikesh Sathyanarayan, Victor Vantilborgh, Ian Abraham
分类: cs.RO
发布日期: 2025-10-20
💡 一句话要点
提出基于接触感知的机器人数据集筛选方法,提升机器人学习效率与确定性
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 机器人学习 数据集筛选 接触感知 Fisher信息 数据质量
📋 核心要点
- 现有机器人学习方法依赖大量数据,但未充分考虑数据质量,尤其是在接触交互场景下。
- 论文提出基于接触感知的Fisher信息度量,用于评估和筛选接触数据,选择信息量大的子集。
- 实验表明,使用筛选后的数据集能加速学习,提高学习的确定性,并优于使用全部数据集。
📝 摘要(中文)
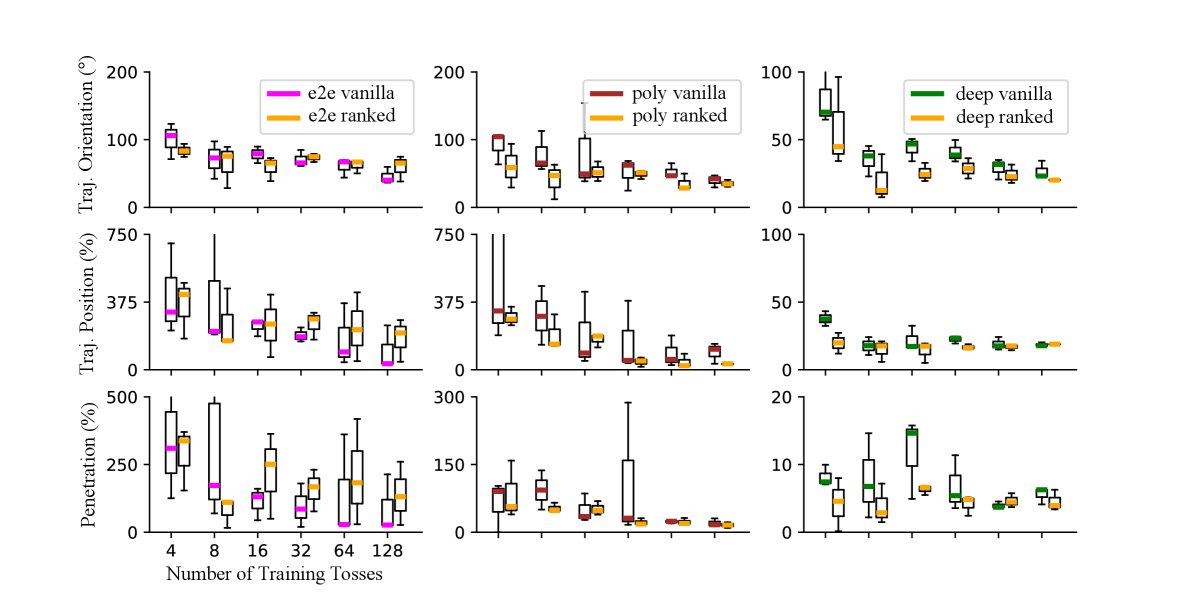
本文研究了数据集的效用,以及更多的数据或“正确”的数据对于机器人学习更有利。特别地,我们有兴趣量化基于接触的数据的效用,因为接触包含机器人学习的重要信息。我们的方法推导了一个接触感知的目标函数,用于从姿势和接触数据中学习物体动力学和形状。我们表明,接触感知的Fisher信息度量可以用于根据数据对于学习的信息量来对接触数据进行排序和筛选。此外,我们发现基于此排序选择缩减的数据集可以改善学习任务,同时也使学习成为一个确定性过程。有趣的是,我们的结果表明,更多的数据不一定有利,而是更少但信息量大的数据可以加速学习,尤其取决于接触交互。最后,我们展示了我们的度量如何用于为基于接触的机器人学习提供数据筛选的初步指导。
🔬 方法详解
问题定义:机器人学习通常需要大量数据,但在接触交互场景下,并非所有数据都同等重要。现有方法往往忽略数据质量,导致学习效率低下,甚至引入噪声。该论文旨在解决如何从接触数据集中选择最具信息量的子集,以提高学习效率和确定性的问题。
核心思路:论文的核心思路是利用接触感知的Fisher信息度量来评估数据的“信息量”。Fisher信息度量可以反映数据对模型参数估计的贡献程度。通过计算每个数据样本的Fisher信息,可以对数据集进行排序,并选择信息量最大的子集。这样可以避免使用冗余或噪声数据,从而提高学习效率和确定性。
技术框架:该方法主要包含以下几个步骤:1) 从机器人与环境的交互中收集包含姿势和接触信息的数据集;2) 定义一个接触感知的目标函数,用于学习物体动力学和形状;3) 计算每个数据样本的接触感知的Fisher信息度量;4) 根据Fisher信息度量对数据集进行排序;5) 选择信息量最大的数据子集用于训练模型。
关键创新:该论文的关键创新在于提出了接触感知的Fisher信息度量,并将其应用于机器人数据集的筛选。与传统的数据选择方法相比,该方法能够更有效地选择与接触交互相关的最具信息量的数据,从而提高学习效率和确定性。
关键设计:论文的关键设计包括:1) 目标函数的设计,需要能够有效地捕捉物体动力学和形状信息;2) Fisher信息度量的计算方法,需要能够准确反映数据对模型参数估计的贡献程度;3) 数据子集选择策略,需要在保证数据信息量的同时,尽可能减少数据量。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用基于接触感知的Fisher信息度量筛选后的数据集,能够显著提高机器人学习的效率和确定性。相比于使用全部数据集,使用筛选后的数据集可以加速学习过程,并获得更高的模型精度。此外,实验还证明了更多的数据并不一定意味着更好的性能,高质量的数据比大量冗余数据更有价值。
🎯 应用场景
该研究成果可应用于各种需要机器人与环境进行接触交互的场景,例如物体抓取、装配、操作等。通过筛选高质量的接触数据,可以显著提高机器人的学习效率和泛化能力,降低开发成本,并提升机器人在复杂环境中的适应性。未来,该方法有望推广到其他类型的数据集和机器人学习任务中。
📄 摘要(原文)
In this paper, we investigate the utility of datasets and whether more data or the 'right' data is advantageous for robot learning. In particular, we are interested on quantifying the utility of contact-based data as contact holds significant information for robot learning. Our approach derives a contact-aware objective function for learning object dynamics and shape from pose and contact data. We show that the contact-aware Fisher-information metric can be used to rank and curate contact-data based on how informative data is for learning. In addition, we find that selecting a reduced dataset based on this ranking improves the learning task while also making learning a deterministic process. Interestingly, our results show that more data is not necessarily advantageous, and rather, less but informative data can accelerate learning, especially depending on the contact interactions. Last, we show how our metric can be used to provide initial guidance on data curation for contact-based robot learning.