Humanoid Goalkeeper: Learning from Position Conditioned Task-Motion Constraints
作者: Junli Ren, Junfeng Long, Tao Huang, Huayi Wang, Zirui Wang, Feiyu Jia, Wentao Zhang, Jingbo Wang, Ping Luo, Jiangmiao Pang
分类: cs.RO
发布日期: 2025-10-20
💡 一句话要点
提出基于位置条件任务-运动约束的人形机器人守门员强化学习框架
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 人形机器人 强化学习 运动控制 对抗学习 人类运动先验
📋 核心要点
- 人形机器人守门员面临生成自然运动和覆盖更大范围的挑战,现有方法依赖遥操作或固定运动跟踪。
- 该方法通过强化学习训练端到端策略,并利用对抗方案将人类运动先验融入训练,实现自主和类人运动。
- 真实实验表明,人形机器人能成功拦截快速移动的球,并在逃逸和抓取等任务中表现出泛化能力。
📝 摘要(中文)
本文提出了一种用于真实场景中人形机器人自主守门员的强化学习框架。与四足机器人相比,人形机器人守门员面临两个关键挑战:生成自然、类人的全身运动,以及在相同反应时间内覆盖更广的防守范围。不同于依赖单独遥操作或固定运动跟踪的现有方法,本文方法学习一个端到端的强化学习策略,实现完全自主、高度动态和类人化的机器人-物体交互。为此,我们将多个基于感知输入的人类运动先验通过对抗方案集成到强化学习训练中。通过真实实验,验证了该方法的有效性,人形机器人成功地自主、敏捷且自然地拦截了快速移动的球。除了守门,我们还展示了该方法在逃逸和抓取等任务中的泛化能力。该工作为实现机器人与运动物体之间的高度动态交互提供了一种实用且可扩展的解决方案,推动了机器人领域朝着更具适应性和更逼真的行为发展。
🔬 方法详解
问题定义:现有的人形机器人守门员方法通常依赖于遥操作或预定义的固定运动模式,这限制了机器人的自主性和运动的自然性。此外,人形机器人相较于四足机器人,在保持平衡和快速响应方面面临更大的挑战,难以在有限的时间内覆盖更大的防守区域。因此,如何使人形机器人能够自主、自然且高效地完成守门任务是一个关键问题。
核心思路:本文的核心思路是将人类的运动先验知识融入到强化学习的训练过程中,从而引导机器人学习更加自然和高效的运动策略。通过对抗学习的方式,使机器人生成的运动尽可能地接近人类的运动模式,从而提高运动的自然性和流畅性。同时,利用强化学习的优势,使机器人能够自主地学习如何根据环境的变化做出最佳的决策。
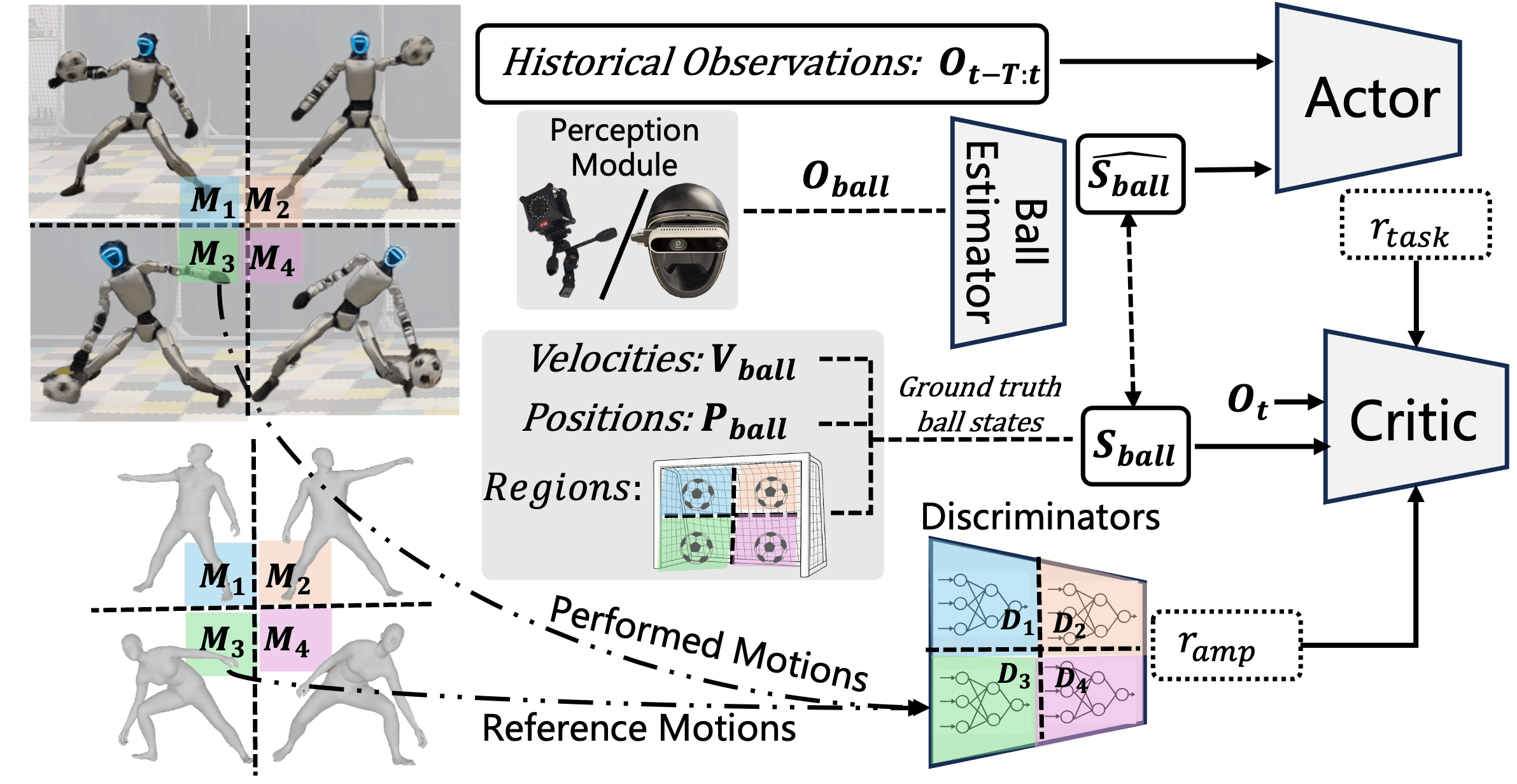
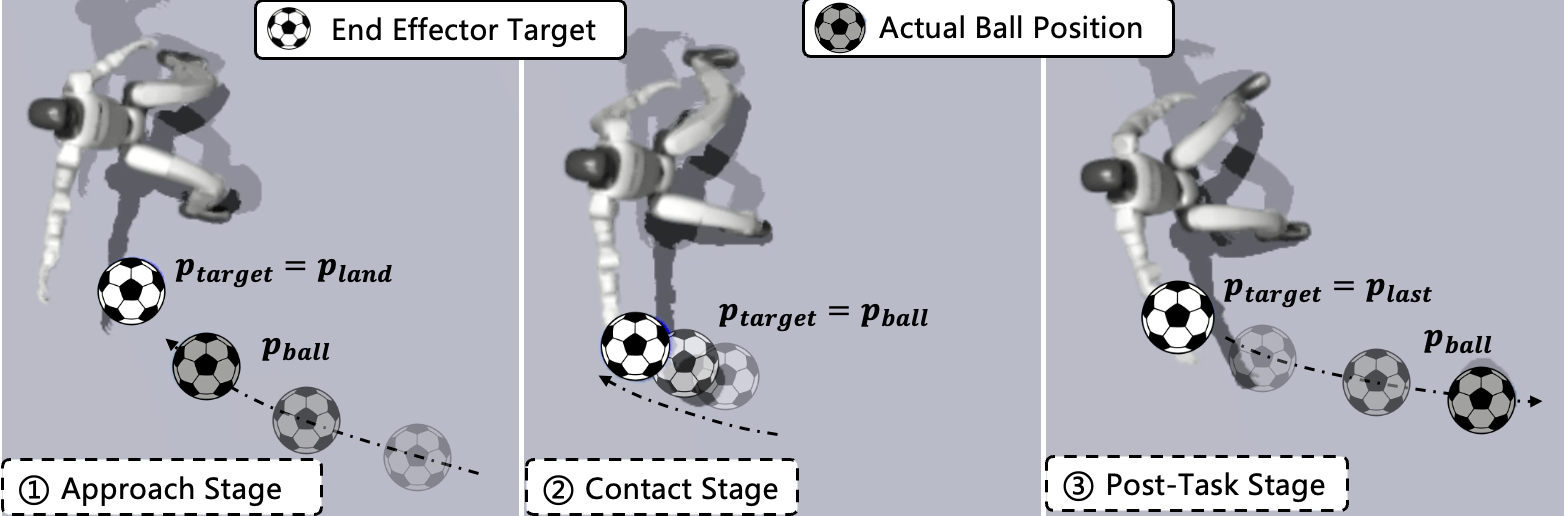
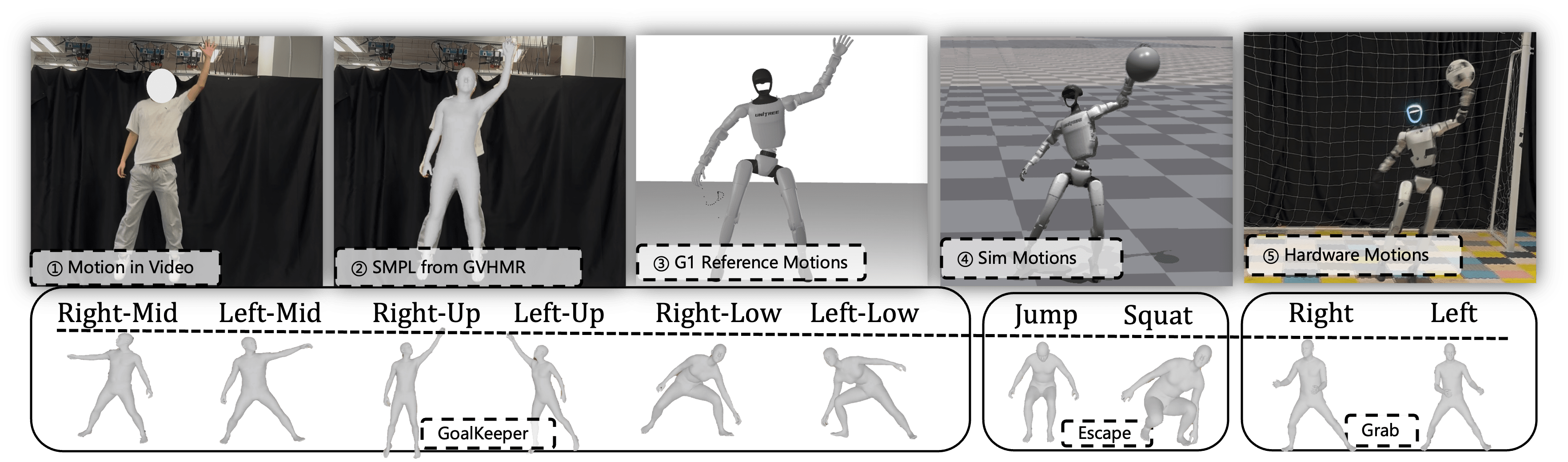
技术框架:该框架主要包含以下几个模块:1) 感知模块:用于获取环境信息,例如球的位置和速度;2) 运动生成模块:基于强化学习策略生成机器人的运动指令;3) 运动控制模块:将运动指令转化为机器人的关节控制信号;4) 人类运动先验模块:提供人类运动数据,用于指导强化学习的训练;5) 对抗学习模块:用于评估机器人生成的运动与人类运动的相似度,并指导策略的优化。整体流程是:感知模块获取环境信息,运动生成模块根据策略生成运动指令,运动控制模块执行指令,对抗学习模块评估运动质量并更新策略。
关键创新:该论文的关键创新在于将人类运动先验知识以一种可控的方式融入到强化学习的训练过程中。通过对抗学习,可以有效地约束机器人的运动空间,使其生成的运动更加自然和类人。此外,该方法采用端到端的学习方式,避免了传统方法中需要手动设计运动模式的繁琐过程,提高了机器人的自主性和适应性。
关键设计:在对抗学习模块中,使用了判别器来区分机器人生成的运动和人类的运动。判别器的输入是机器人的关节角度和角速度等信息,输出是运动属于人类运动的概率。强化学习的目标是最大化机器人在守门任务中的奖励,同时最小化判别器区分机器人运动和人类运动的能力。损失函数包括守门任务的奖励、对抗损失和正则化项。网络结构采用了多层感知机,用于策略的表示和判别器的训练。
🖼️ 关键图片
📊 实验亮点
在真实实验中,人形机器人成功地拦截了快速移动的球,展示了其自主、敏捷和自然的运动能力。实验结果表明,该方法能够有效地提高机器人的守门成功率和运动的自然性。此外,该方法还在逃逸和抓取等任务中表现出良好的泛化能力,证明了其在复杂环境中的适应性。
🎯 应用场景
该研究成果可应用于人形机器人在复杂环境中的运动控制,例如服务型机器人、救援机器人和体育机器人等。通过学习人类的运动模式,机器人可以更好地与人类进行交互,完成各种任务。此外,该方法还可以推广到其他类型的机器人,例如四足机器人和轮式机器人,从而提高机器人的自主性和适应性。
📄 摘要(原文)
We present a reinforcement learning framework for autonomous goalkeeping with humanoid robots in real-world scenarios. While prior work has demonstrated similar capabilities on quadrupedal platforms, humanoid goalkeeping introduces two critical challenges: (1) generating natural, human-like whole-body motions, and (2) covering a wider guarding range with an equivalent response time. Unlike existing approaches that rely on separate teleoperation or fixed motion tracking for whole-body control, our method learns a single end-to-end RL policy, enabling fully autonomous, highly dynamic, and human-like robot-object interactions. To achieve this, we integrate multiple human motion priors conditioned on perceptual inputs into the RL training via an adversarial scheme. We demonstrate the effectiveness of our method through real-world experiments, where the humanoid robot successfully performs agile, autonomous, and naturalistic interceptions of fast-moving balls. In addition to goalkeeping, we demonstrate the generalization of our approach through tasks such as ball escaping and grabbing. Our work presents a practical and scalable solution for enabling highly dynamic interactions between robots and moving objects, advancing the field toward more adaptive and lifelike robotic behaviors.