Robobench: A Comprehensive Evaluation Benchmark for Multimodal Large Language Models as Embodied Brain
作者: Yulin Luo, Chun-Kai Fan, Menghang Dong, Jiayu Shi, Mengdi Zhao, Bo-Wen Zhang, Cheng Chi, Jiaming Liu, Gaole Dai, Rongyu Zhang, Ruichuan An, Kun Wu, Zhengping Che, Shaoxuan Xie, Guocai Yao, Zhongxia Zhao, Pengwei Wang, Guang Liu, Zhongyuan Wang, Tiejun Huang, Shanghang Zhang
分类: cs.RO, cs.CV
发布日期: 2025-10-20
💡 一句话要点
RoboBench:用于评估多模态大语言模型作为具身智能大脑的综合基准
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱三:空间感知与语义 (Perception & Semantics) 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 具身智能 多模态大语言模型 机器人操作 基准测试 认知能力评估
📋 核心要点
- 现有具身智能基准测试在评估高层次推理能力时,存在维度不完整和任务真实性不足的问题,无法全面评估认知能力。
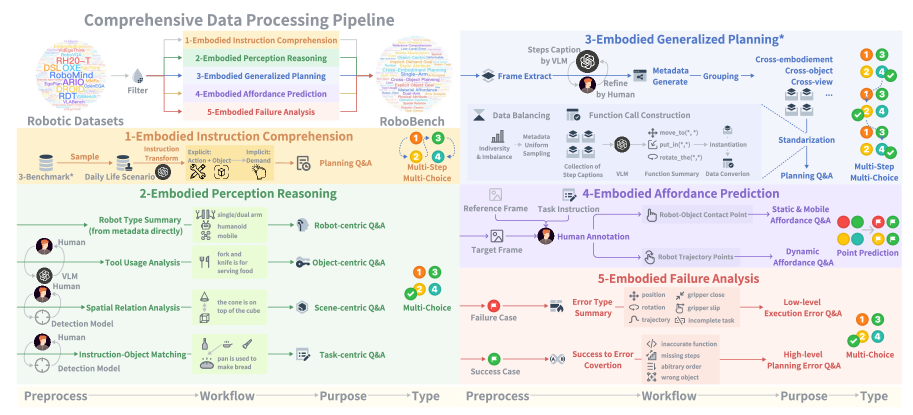
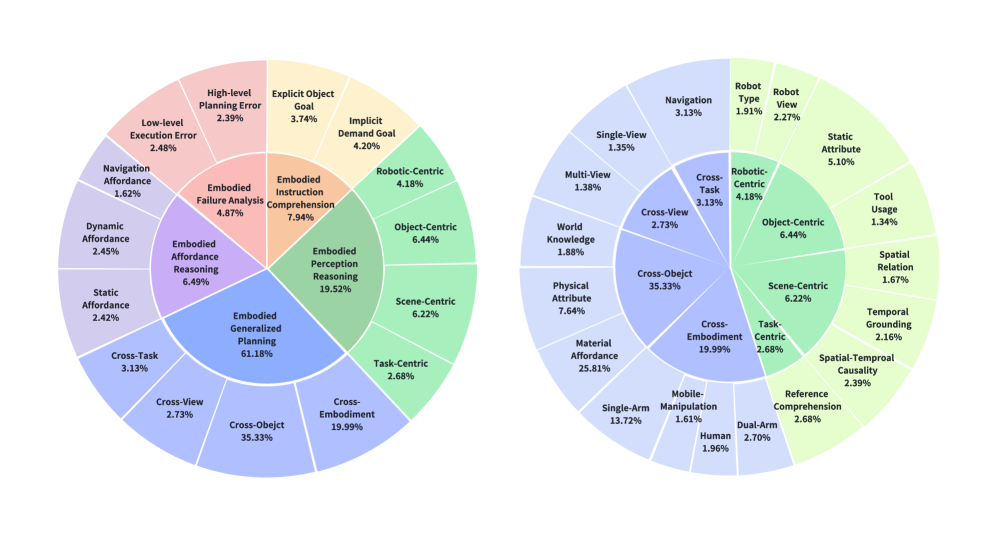
- RoboBench通过定义指令理解、感知推理、泛化规划等五个维度,系统评估多模态大语言模型作为具身智能大脑的能力。
- 实验表明,现有MLLM在隐式指令理解、时空推理等方面存在局限性,RoboBench为下一代具身MLLM的开发提供了指导。
📝 摘要(中文)
构建能够在动态、非结构化环境中感知、推理和行动的机器人仍然是一个核心挑战。最近的具身智能系统通常采用双系统范式,其中系统2处理高层次推理,而系统1执行低层次控制。本文将系统2称为具身智能大脑,强调其作为操作任务中推理和决策的认知核心作用。因此,对具身智能大脑进行系统评估至关重要。然而,现有的基准侧重于执行成功,或者当针对高层次推理时,存在维度不完整和任务真实性有限的问题,只能提供认知能力的局部视图。为了弥合这一差距,我们引入了RoboBench,一个系统地评估多模态大语言模型(MLLM)作为具身智能大脑的基准。受整个操作流程中关键作用的驱动,RoboBench定义了五个维度——指令理解、感知推理、泛化规划、可供性预测和失败分析——涵盖14种能力、25个任务和6092个QA对。为了确保真实性,我们从大规模真实机器人数据中整理了跨不同具身、属性丰富的对象和多视图场景的数据集。对于规划,RoboBench引入了一个评估框架,即MLLM-as-world-simulator。它通过模拟预测的计划是否可以实现关键的对象状态变化来评估具身可行性。对14个MLLM的实验揭示了根本的局限性:在隐式指令理解、时空推理、跨场景规划、细粒度可供性理解和执行失败诊断方面存在困难。RoboBench提供了一个全面的支架来量化高层次认知,并指导下一代具身MLLM的开发。
🔬 方法详解
问题定义:现有具身智能系统评估基准主要关注执行成功率,而忽略了对高层次认知能力的全面评估。即使针对高层次推理的基准,也存在维度不完整、任务不够真实的问题,无法充分反映具身智能大脑的认知能力。因此,需要一个更全面、更真实的基准来评估多模态大语言模型(MLLM)作为具身智能大脑的能力。
核心思路:RoboBench的核心思路是将MLLM视为具身智能的“大脑”,并从认知角度出发,系统地评估其在操作任务中的各项能力。通过定义五个关键维度(指令理解、感知推理、泛化规划、可供性预测和失败分析),RoboBench能够更全面地量化MLLM的高层次认知能力,并揭示其在具身智能应用中的局限性。
技术框架:RoboBench的评估框架包含以下主要模块:1) 数据集构建:收集包含不同具身、属性丰富的对象和多视图场景的大规模真实机器人数据。2) 任务定义:设计涵盖14种能力、25个任务的评估用例,并构建包含6092个QA对的问答数据集。3) 评估维度:定义指令理解、感知推理、泛化规划、可供性预测和失败分析五个维度,用于评估MLLM在不同认知方面的表现。4) 规划评估:引入MLLM-as-world-simulator框架,通过模拟预测的计划是否能实现关键对象状态变化来评估具身可行性。
关键创新:RoboBench的关键创新在于其全面性和真实性。它不仅考虑了执行结果,更关注MLLM在指令理解、感知推理等认知过程中的表现。此外,RoboBench使用了大规模真实机器人数据,并引入了MLLM-as-world-simulator框架,从而保证了评估的真实性和可靠性。
关键设计:RoboBench的关键设计包括:1) 五个评估维度的选择,这些维度涵盖了具身智能大脑在操作任务中的关键认知能力。2) 大规模真实机器人数据集的构建,保证了评估的真实性。3) MLLM-as-world-simulator框架的设计,能够评估规划的具身可行性。4) 针对每个任务设计的详细评估指标,能够量化MLLM在不同方面的表现。
🖼️ 关键图片

📊 实验亮点
对14个MLLM的实验结果表明,现有模型在隐式指令理解、时空推理、跨场景规划、细粒度可供性理解和执行失败诊断等方面存在显著局限性。例如,模型难以理解隐含在自然语言指令中的意图,也难以进行跨场景的知识迁移和泛化。这些发现为未来具身智能MLLM的研究方向提供了重要参考。
🎯 应用场景
RoboBench可用于评估和改进多模态大语言模型在具身智能领域的应用,例如机器人操作、自动化装配、智能家居等。通过该基准,研究人员可以更好地了解MLLM的优势和局限性,从而开发出更智能、更可靠的具身智能系统,提升机器人在复杂环境中的适应性和自主性。
📄 摘要(原文)
Building robots that can perceive, reason, and act in dynamic, unstructured environments remains a core challenge. Recent embodied systems often adopt a dual-system paradigm, where System 2 handles high-level reasoning while System 1 executes low-level control. In this work, we refer to System 2 as the embodied brain, emphasizing its role as the cognitive core for reasoning and decision-making in manipulation tasks. Given this role, systematic evaluation of the embodied brain is essential. Yet existing benchmarks emphasize execution success, or when targeting high-level reasoning, suffer from incomplete dimensions and limited task realism, offering only a partial picture of cognitive capability. To bridge this gap, we introduce RoboBench, a benchmark that systematically evaluates multimodal large language models (MLLMs) as embodied brains. Motivated by the critical roles across the full manipulation pipeline, RoboBench defines five dimensions-instruction comprehension, perception reasoning, generalized planning, affordance prediction, and failure analysis-spanning 14 capabilities, 25 tasks, and 6092 QA pairs. To ensure realism, we curate datasets across diverse embodiments, attribute-rich objects, and multi-view scenes, drawing from large-scale real robotic data. For planning, RoboBench introduces an evaluation framework, MLLM-as-world-simulator. It evaluate embodied feasibility by simulating whether predicted plans can achieve critical object-state changes. Experiments on 14 MLLMs reveal fundamental limitations: difficulties with implicit instruction comprehension, spatiotemporal reasoning, cross-scenario planning, fine-grained affordance understanding, and execution failure diagnosis. RoboBench provides a comprehensive scaffold to quantify high-level cognition, and guide the development of next-generation embodied MLLMs. The project page is in https://robo-bench.github.io.