SoftMimic: Learning Compliant Whole-body Control from Examples
作者: Gabriel B. Margolis, Michelle Wang, Nolan Fey, Pulkit Agrawal
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-20
备注: Website: https://gmargo11.github.io/softmimic/
💡 一句话要点
SoftMimic:从示例中学习柔顺的人形机器人全身控制策略
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting) 支柱八:物理动画 (Physics-based Animation)
关键词: 人形机器人 柔顺控制 模仿学习 强化学习 逆运动学
📋 核心要点
- 现有方法在人形机器人模仿学习中倾向于刚性控制,对偏差过度纠正,导致机器人脆弱且不安全。
- SoftMimic通过奖励策略匹配柔顺响应而非刚性跟踪,使机器人能够对外部扰动做出柔顺反应。
- 通过仿真和真实实验验证,SoftMimic实现了人形机器人与环境的安全有效交互,并能推广到不同任务。
📝 摘要(中文)
本文提出SoftMimic,一个从示例动作中学习人形机器人柔顺全身控制策略的框架。通过强化学习模仿人类动作可以使人形机器人快速学习新技能,但现有方法倾向于刚性控制,即积极纠正与参考动作的偏差,导致机器人在遇到意外接触时表现出脆弱和不安全的行为。相比之下,SoftMimic使机器人能够在保持平衡和姿势的同时,对外部力量做出柔顺的反应。我们的方法利用逆运动学求解器生成可行柔顺运动的增强数据集,并使用该数据集训练强化学习策略。通过奖励策略匹配柔顺响应而不是刚性跟踪参考运动,SoftMimic学会吸收扰动并从单个运动片段推广到各种任务。我们通过仿真和真实世界的实验验证了我们的方法,证明了与环境安全有效的交互。
🔬 方法详解
问题定义:现有的人形机器人模仿学习方法,特别是基于强化学习的方法,通常会学习到刚性的控制策略。这些策略会试图精确地跟踪参考动作,一旦机器人受到外部干扰,例如碰撞,就会立即进行剧烈的纠正,导致机器人不稳定甚至摔倒。因此,如何让人形机器人学习到柔顺的控制策略,使其能够像人类一样自然地应对外部干扰,是一个重要的挑战。
核心思路:SoftMimic的核心思路是,不再直接奖励机器人精确跟踪参考动作,而是奖励机器人对外部干扰做出合理的柔顺响应。这意味着机器人可以适当地偏离参考动作,以吸收外部力量,保持平衡和姿势。为了实现这一点,论文首先生成一个包含各种柔顺响应的增强数据集,然后使用强化学习训练一个能够模仿这些柔顺响应的策略。
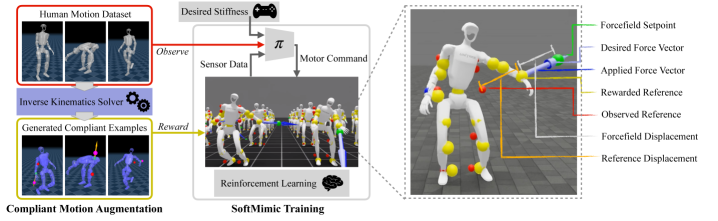
技术框架:SoftMimic的整体框架包括以下几个主要步骤:1) 数据增强:使用逆运动学求解器,基于原始的参考动作,生成一系列受到外部干扰后的可行柔顺运动。这些运动构成了增强数据集。2) 强化学习训练:使用增强数据集训练一个强化学习策略。该策略的目标是模仿增强数据集中的柔顺响应,而不是原始的参考动作。3) 策略部署:将训练好的策略部署到真实的机器人上,使其能够对外部干扰做出柔顺的反应。
关键创新:SoftMimic最重要的创新点在于,它改变了强化学习的目标函数,不再是精确跟踪参考动作,而是模仿柔顺响应。这种改变使得机器人能够学习到更加自然和安全的控制策略。此外,使用逆运动学求解器生成增强数据集也是一个重要的创新,它提供了一种有效的方法来生成各种可能的柔顺响应。
关键设计:在数据增强阶段,论文使用逆运动学求解器来计算在受到外部干扰时,机器人关节应该如何运动才能保持平衡和姿势。在强化学习训练阶段,论文使用了一种基于Actor-Critic的算法,其中Actor网络负责生成机器人的动作,Critic网络负责评估这些动作的质量。奖励函数的设计至关重要,它不仅要奖励机器人保持平衡和姿势,还要奖励机器人对外部干扰做出合理的柔顺响应。具体的奖励函数包括平衡奖励、姿势奖励、柔顺性奖励等。
🖼️ 关键图片

📊 实验亮点
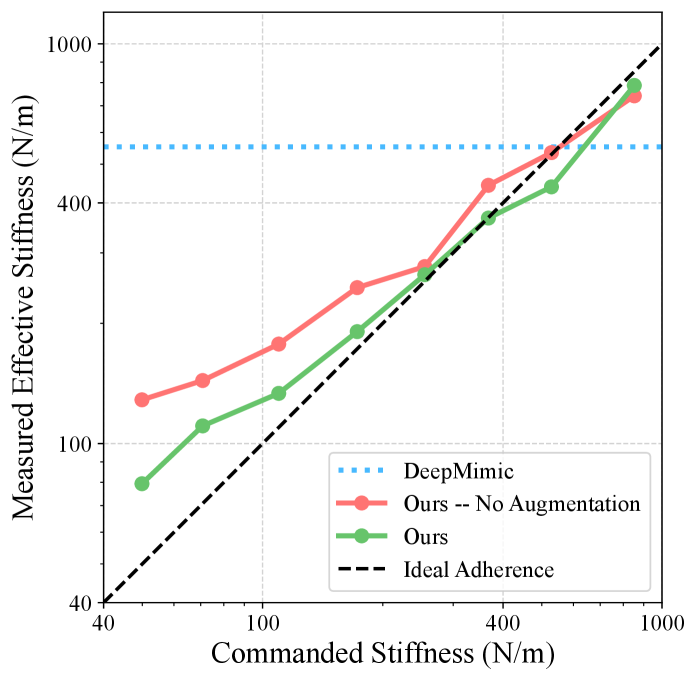
实验结果表明,SoftMimic能够有效地学习到柔顺的控制策略。在仿真环境中,SoftMimic能够成功地应对各种外部干扰,例如推搡、碰撞等,并且能够保持平衡和姿势。在真实机器人实验中,SoftMimic也表现出了良好的性能,能够安全地与人类进行互动。与传统的刚性控制策略相比,SoftMimic能够显著提高机器人的鲁棒性和安全性。
🎯 应用场景
SoftMimic具有广泛的应用前景,例如在人机协作、康复机器人、服务机器人等领域。它可以使机器人更加安全、自然地与人类互动,提高机器人的适应性和鲁棒性。未来的研究可以进一步探索如何将SoftMimic应用于更复杂的任务,例如双臂协调操作、复杂地形行走等,从而推动人形机器人技术的发展。
📄 摘要(原文)
We introduce SoftMimic, a framework for learning compliant whole-body control policies for humanoid robots from example motions. Imitating human motions with reinforcement learning allows humanoids to quickly learn new skills, but existing methods incentivize stiff control that aggressively corrects deviations from a reference motion, leading to brittle and unsafe behavior when the robot encounters unexpected contacts. In contrast, SoftMimic enables robots to respond compliantly to external forces while maintaining balance and posture. Our approach leverages an inverse kinematics solver to generate an augmented dataset of feasible compliant motions, which we use to train a reinforcement learning policy. By rewarding the policy for matching compliant responses rather than rigidly tracking the reference motion, SoftMimic learns to absorb disturbances and generalize to varied tasks from a single motion clip. We validate our method through simulations and real-world experiments, demonstrating safe and effective interaction with the environment.