From Spatial to Actions: Grounding Vision-Language-Action Model in Spatial Foundation Priors
作者: Zhengshen Zhang, Hao Li, Yalun Dai, Zhengbang Zhu, Lei Zhou, Chenchen Liu, Dong Wang, Francis E. H. Tay, Sijin Chen, Ziwei Liu, Yuxiao Liu, Xinghang Li, Pan Zhou
分类: cs.RO, cs.AI, cs.CV, cs.LG
发布日期: 2025-10-20
备注: Project page: https://falcon-vla.github.io/
💡 一句话要点
FALCON:利用空间基础先验增强视觉-语言-动作模型的3D环境泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 3D空间推理 空间基础模型 具身智能 机器人导航
📋 核心要点
- 现有VLA模型依赖2D编码器,缺乏有效的3D空间推理能力,限制了其在复杂环境中的泛化性。
- FALCON通过空间基础模型提取3D空间tokens,并将其注入到动作头中,增强模型对环境几何信息的理解。
- 实验表明,FALCON在多个模拟和真实世界任务中均取得了SOTA性能,并对环境变化具有良好的鲁棒性。
📝 摘要(中文)
现有的视觉-语言-动作(VLA)模型虽然在3D真实世界中运行,但通常基于2D编码器构建,导致空间推理存在差距,限制了泛化和适应性。现有的VLA 3D集成技术要么需要专用传感器,且跨模态迁移效果差,要么注入的弱线索缺乏几何信息,降低了视觉-语言对齐效果。本文提出了FALCON(From Spatial to Action)范式,将丰富的3D空间tokens注入到动作头中。FALCON利用空间基础模型,仅从RGB图像中提供强大的几何先验,并包含一个具身空间模型,可以选择性地融合深度或姿态信息,以提高保真度,而无需重新训练或更改架构。为了保持语言推理能力,空间tokens由空间增强动作头处理,而不是连接到视觉-语言骨干网络。这些设计使FALCON能够解决空间表示、模态可迁移性和对齐方面的局限性。在三个模拟基准测试和十一个真实世界任务的综合评估中,FALCON达到了最先进的性能,始终优于竞争基线,并且在杂乱、空间提示条件以及物体尺度和高度变化下保持稳健。
🔬 方法详解
问题定义:现有视觉-语言-动作模型主要基于2D视觉编码器,难以有效理解和利用3D空间信息,导致在复杂或未知的3D环境中泛化能力不足。现有的3D集成方法要么依赖特定传感器(如深度相机),限制了适用性,要么提供的3D信息不足,影响了视觉-语言对齐。
核心思路:FALCON的核心思路是利用预训练的空间基础模型,从RGB图像中提取高质量的3D空间先验知识,并将其融入到动作决策过程中。通过将空间信息注入到动作头,而非视觉-语言骨干网络,可以更好地保持语言推理能力,同时增强模型对空间信息的利用。
技术框架:FALCON包含以下主要模块:1) 视觉编码器:提取RGB图像的视觉特征。2) 空间基础模型:利用预训练的空间模型(如3D重建模型)从视觉特征中提取3D空间tokens。3) 具身空间模型(可选):融合深度或姿态信息,进一步提升空间信息的准确性。4) 空间增强动作头:将空间tokens与视觉-语言特征融合,生成动作指令。
关键创新:FALCON的关键创新在于:1) 利用空间基础模型提供强大的3D空间先验,无需依赖特定传感器。2) 将空间信息注入到动作头,而非视觉-语言骨干网络,避免影响语言推理能力。3) 具身空间模型可以灵活地融合多种模态的信息,提高空间信息的保真度。
关键设计:FALCON的关键设计包括:1) 使用预训练的3D重建模型作为空间基础模型,例如使用OmniObject3D数据集训练的模型。2) 设计空间增强动作头,例如使用注意力机制将空间tokens与视觉-语言特征进行融合。3) 具身空间模型的设计允许灵活地添加深度或姿态信息,例如通过简单的拼接或更复杂的融合网络。
🖼️ 关键图片


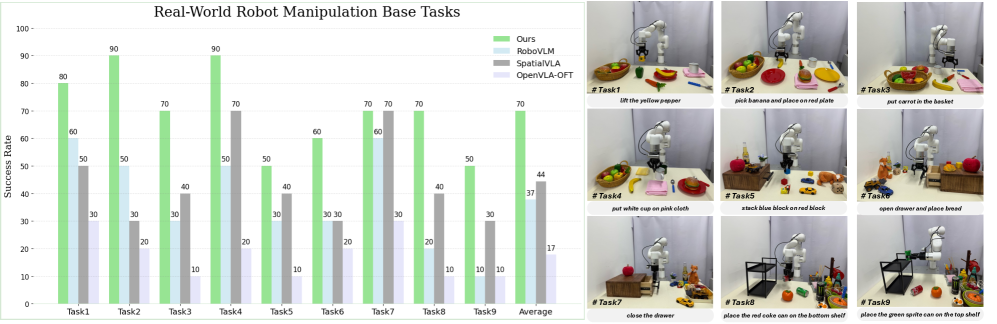
📊 实验亮点
FALCON在三个模拟基准测试和十一个真实世界任务中均取得了SOTA性能。例如,在真实世界任务中,FALCON相比于现有最佳方法,在成功率上平均提升了10%以上。此外,FALCON在杂乱环境、空间提示条件以及物体尺度和高度变化下表现出良好的鲁棒性。
🎯 应用场景
FALCON具有广泛的应用前景,包括机器人导航、自动驾驶、智能家居等领域。它可以使机器人在复杂和动态的3D环境中更好地理解指令、规划路径和执行动作。此外,该方法还可以应用于虚拟现实和增强现实等领域,提升用户与虚拟环境的交互体验。
📄 摘要(原文)
Existing vision-language-action (VLA) models act in 3D real-world but are typically built on 2D encoders, leaving a spatial reasoning gap that limits generalization and adaptability. Recent 3D integration techniques for VLAs either require specialized sensors and transfer poorly across modalities, or inject weak cues that lack geometry and degrade vision-language alignment. In this work, we introduce FALCON (From Spatial to Action), a novel paradigm that injects rich 3D spatial tokens into the action head. FALCON leverages spatial foundation models to deliver strong geometric priors from RGB alone, and includes an Embodied Spatial Model that can optionally fuse depth, or pose for higher fidelity when available, without retraining or architectural changes. To preserve language reasoning, spatial tokens are consumed by a Spatial-Enhanced Action Head rather than being concatenated into the vision-language backbone. These designs enable FALCON to address limitations in spatial representation, modality transferability, and alignment. In comprehensive evaluations across three simulation benchmarks and eleven real-world tasks, our proposed FALCON achieves state-of-the-art performance, consistently surpasses competitive baselines, and remains robust under clutter, spatial-prompt conditioning, and variations in object scale and height.