Bridging Embodiment Gaps: Deploying Vision-Language-Action Models on Soft Robots
作者: Haochen Su, Cristian Meo, Francesco Stella, Andrea Peirone, Kai Junge, Josie Hughes
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-20
备注: Accepted by NeurIPS 2025 SpaVLE workshop. 4 pages, 2 figures(in main paper, excluding references and supplements)
💡 一句话要点
在软体机器人上部署视觉-语言-动作模型,弥合具身差距
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 软体机器人 具身智能 人机交互 微调
📋 核心要点
- 现有VLA模型部署受限于传统刚性机器人,缺乏在非结构化环境中安全交互的能力。
- 通过在软体机器人上部署VLA模型,并进行针对性的微调,弥合刚性和柔性机器人之间的具身差距。
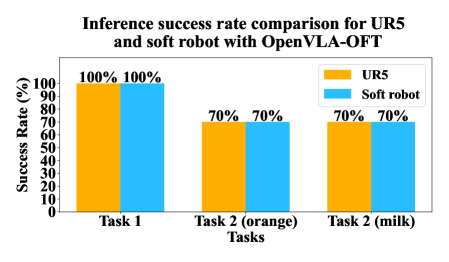
- 实验表明,经过微调的VLA模型能够使软体机器人达到与刚性机器人相当的性能,实现安全人机交互。
📝 摘要(中文)
本文探讨了在软体连续体机器人上部署视觉-语言-动作(VLA)模型,以实现安全自主的人机交互。VLA模型作为一种语言引导的通用控制框架,在真实机器人上具有应用潜力。然而,由于刚性机器人自身的局限性以及基于学习的控制方法的不确定性,安全交互能力仍有欠缺。本文通过对两种先进的VLA模型(OpenVLA-OFT和$π_0$)进行结构化的微调和部署,并在代表性的操作任务中进行评估,结果表明,开箱即用的策略由于具身不匹配而失效,但通过有针对性的微调,软体机器人的性能可以与刚性机器人相媲美。研究结果强调了微调在弥合具身差距方面的必要性,并证明了将VLA模型与软体机器人相结合,能够在人机共享环境中实现安全灵活的具身智能。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型主要应用于刚性机器人,难以直接迁移到软体机器人上。软体机器人具有高自由度、非线性等特点,导致VLA模型在刚性机器人上学习到的策略无法有效适应软体机器人的控制。此外,刚性机器人在与环境交互时存在潜在的安全风险,而软体机器人在这方面具有优势,但需要VLA模型能够充分利用软体机器人的特性。
核心思路:本文的核心思路是通过对VLA模型进行微调,使其适应软体机器人的具身特性。具体来说,利用软体机器人的视觉和运动数据,对预训练的VLA模型进行有监督的训练,从而使模型能够更好地理解软体机器人的状态空间和动作空间,并生成相应的控制策略。这种方法旨在弥合刚性机器人和软体机器人之间的具身差距,使VLA模型能够在软体机器人上实现安全、灵活的控制。
技术框架:该研究的整体框架包括以下几个主要步骤:1) 选择合适的VLA模型(OpenVLA-OFT和$π_0$);2) 收集软体机器人的视觉和运动数据;3) 利用收集到的数据对VLA模型进行微调;4) 在代表性的操作任务中评估微调后的VLA模型的性能。框架的关键在于微调过程,通过优化VLA模型的参数,使其能够更好地适应软体机器人的动力学特性。
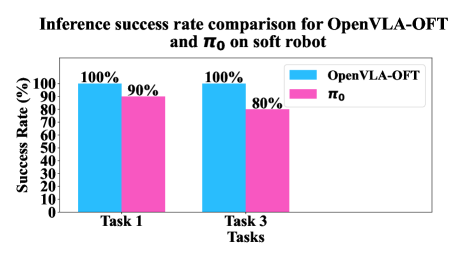
关键创新:该研究的关键创新在于将VLA模型成功部署到软体机器人上,并验证了通过微调可以有效弥合刚性和柔性机器人之间的具身差距。以往的研究主要集中在刚性机器人上,而本文首次探索了VLA模型在软体机器人上的应用,并提出了针对软体机器人的微调方法。这为VLA模型在更广泛的机器人应用场景中部署提供了新的思路。
关键设计:在微调过程中,使用了有监督学习的方法,利用软体机器人的视觉和运动数据作为训练样本。损失函数的设计需要考虑软体机器人的特殊性,例如,可以引入正则化项来约束模型的输出,使其更加平滑和稳定。此外,网络结构的选择也需要根据软体机器人的特点进行调整,例如,可以采用循环神经网络(RNN)来处理软体机器人的时序数据。
🖼️ 关键图片

📊 实验亮点
实验结果表明,未经微调的VLA模型在软体机器人上表现不佳,但经过针对性的微调后,软体机器人的性能可以与刚性机器人相媲美。具体来说,在操作任务中,微调后的软体机器人能够成功完成任务,并且具有较高的安全性和鲁棒性。这验证了微调在弥合具身差距方面的有效性,并证明了VLA模型在软体机器人上的应用潜力。
🎯 应用场景
该研究成果可应用于人机协作、医疗康复、柔性制造等领域。软体机器人结合VLA模型,能够安全地与人类进行交互,完成精细的操作任务。例如,在医疗领域,软体机器人可以辅助医生进行手术,提供更加精准和安全的医疗服务。在柔性制造领域,软体机器人可以适应不同的工作环境,完成各种复杂的装配任务。未来,该技术有望推动机器人技术在更多领域的应用。
📄 摘要(原文)
Robotic systems are increasingly expected to operate in human-centered, unstructured environments where safety, adaptability, and generalization are essential. Vision-Language-Action (VLA) models have been proposed as a language guided generalized control framework for real robots. However, their deployment has been limited to conventional serial link manipulators. Coupled by their rigidity and unpredictability of learning based control, the ability to safely interact with the environment is missing yet critical. In this work, we present the deployment of a VLA model on a soft continuum manipulator to demonstrate autonomous safe human-robot interaction. We present a structured finetuning and deployment pipeline evaluating two state-of-the-art VLA models (OpenVLA-OFT and $π_0$) across representative manipulation tasks, and show while out-of-the-box policies fail due to embodiment mismatch, through targeted finetuning the soft robot performs equally to the rigid counterpart. Our findings highlight the necessity of finetuning for bridging embodiment gaps, and demonstrate that coupling VLA models with soft robots enables safe and flexible embodied AI in human-shared environments.