Decentralized Real-Time Planning for Multi-UAV Cooperative Manipulation via Imitation Learning
作者: Shantnav Agarwal, Javier Alonso-Mora, Sihao Sun
分类: cs.RO
发布日期: 2025-10-20
备注: Accepted by IEEE MRS 2025
💡 一句话要点
提出基于模仿学习的去中心化多无人机协同操作实时规划方法
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多无人机协同 去中心化控制 模仿学习 运动规划 物理信息神经网络
📋 核心要点
- 现有方法依赖集中控制或通信,难以应对实际应用中的挑战。
- 利用模仿学习训练去中心化策略,学生策略模仿集中式规划器。
- 实验验证了该方法在仿真和真实环境中的有效性,性能与集中式方法相当。
📝 摘要(中文)
现有的多无人机协同运输和操作悬挂负载的方法通常依赖于集中式控制架构或可靠的智能体间通信。本文提出了一种基于机器学习的去中心化运动规划方法,该方法在部分可观测性和无智能体间通信的情况下有效运行。我们的方法利用模仿学习,通过模仿具有全局观测权限的集中式运动规划器,为每个无人机训练一个去中心化的学生策略。学生策略使用物理信息神经网络生成平滑轨迹,保证运动中的导数关系。在训练过程中,学生策略利用教师策略生成的完整轨迹,从而提高样本效率。此外,每个学生策略都可以在标准笔记本电脑上在两小时内完成训练。我们在仿真和真实环境中验证了我们的方法,使其能够跟随灵活的参考轨迹,展示了与集中式方法相当的性能。
🔬 方法详解
问题定义:论文旨在解决多无人机协同操作悬挂负载时,对集中式控制架构和可靠的智能体间通信的依赖问题。现有方法的痛点在于,在实际应用中,通信可能受限或不可靠,集中式控制容易出现单点故障,难以保证系统的鲁棒性和可扩展性。
核心思路:论文的核心解决思路是采用去中心化的控制策略,每个无人机独立进行运动规划,无需与其他无人机进行实时通信。通过模仿学习,让每个无人机学习集中式规划器的行为,从而在局部观测下也能实现协同操作。这种设计降低了对通信的要求,提高了系统的鲁棒性。
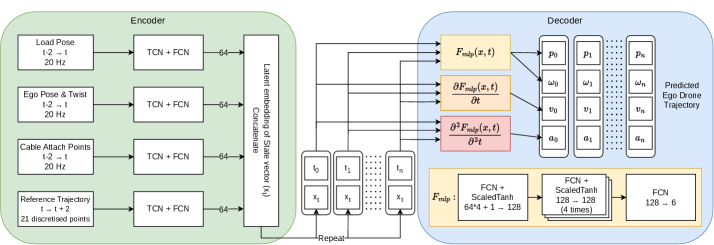
技术框架:整体框架包括两个阶段:教师策略训练和学生策略训练。首先,使用集中式运动规划器作为教师策略,生成全局最优的轨迹。然后,使用模仿学习,训练每个无人机的学生策略,使其能够模仿教师策略的行为。学生策略使用物理信息神经网络生成平滑轨迹,并考虑无人机的运动学和动力学约束。
关键创新:最重要的技术创新点是利用模仿学习训练去中心化的学生策略,从而在无需智能体间通信的情况下实现多无人机协同操作。与传统的集中式控制方法相比,该方法具有更好的鲁棒性和可扩展性。此外,使用物理信息神经网络保证了轨迹的平滑性和物理可行性。
关键设计:关键设计包括:1) 使用集中式运动规划器生成高质量的训练数据;2) 使用物理信息神经网络作为学生策略,保证轨迹的平滑性和物理可行性;3) 设计合适的损失函数,鼓励学生策略模仿教师策略的行为,并满足运动学和动力学约束;4) 采用课程学习策略,逐步增加任务的难度,提高学生策略的泛化能力。
🖼️ 关键图片

📊 实验亮点
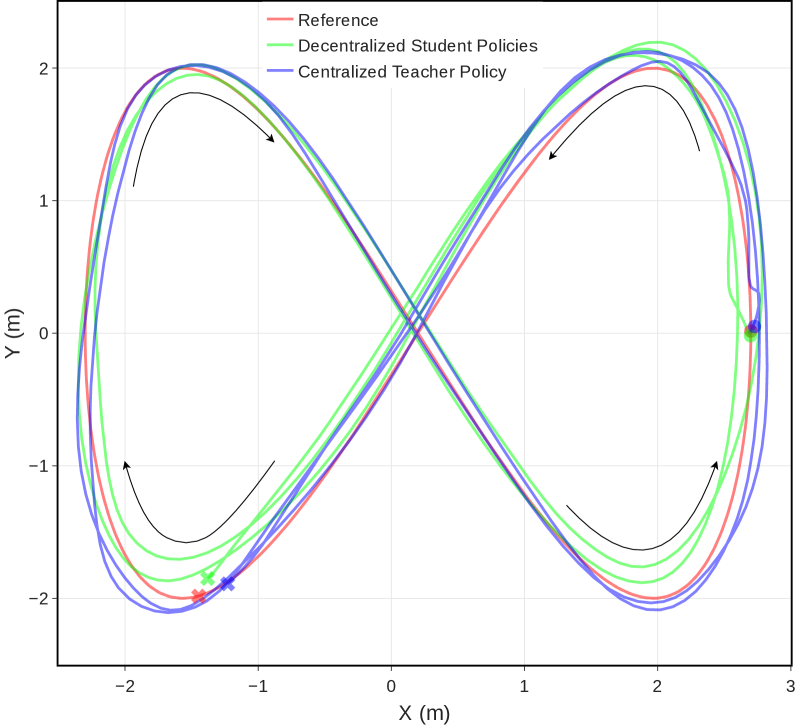
该方法在仿真和真实环境中进行了验证,结果表明,该方法能够使多无人机跟随灵活的参考轨迹,性能与集中式方法相当。更重要的是,每个学生策略都可以在标准笔记本电脑上在两小时内完成训练,这表明该方法具有较高的训练效率和实用性。实验结果验证了该方法在去中心化多无人机协同操作方面的有效性。
🎯 应用场景
该研究成果可应用于物流运输、建筑施工、灾害救援等领域,实现多无人机协同搬运重物或执行复杂任务。去中心化的控制策略降低了对通信基础设施的依赖,提高了系统的鲁棒性,使其更适合在复杂和动态的环境中部署。未来,该方法有望扩展到更多类型的多智能体系统,例如多机器人协同操作。
📄 摘要(原文)
Existing approaches for transporting and manipulating cable-suspended loads using multiple UAVs along reference trajectories typically rely on either centralized control architectures or reliable inter-agent communication. In this work, we propose a novel machine learning based method for decentralized kinodynamic planning that operates effectively under partial observability and without inter-agent communication. Our method leverages imitation learning to train a decentralized student policy for each UAV by imitating a centralized kinodynamic motion planner with access to privileged global observations. The student policy generates smooth trajectories using physics-informed neural networks that respect the derivative relationships in motion. During training, the student policies utilize the full trajectory generated by the teacher policy, leading to improved sample efficiency. Moreover, each student policy can be trained in under two hours on a standard laptop. We validate our method in both simulation and real-world environments to follow an agile reference trajectory, demonstrating performance comparable to that of centralized approaches.