Efficient Vision-Language-Action Models for Embodied Manipulation: A Systematic Survey
作者: Weifan Guan, Qinghao Hu, Aosheng Li, Jian Cheng
分类: cs.RO, cs.AI, cs.LG
发布日期: 2025-10-20 (更新: 2025-10-23)
💡 一句话要点
综述高效视觉-语言-动作模型,解决具身操作中计算和内存瓶颈
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言-动作模型 具身智能 机器人控制 模型效率 边缘计算
📋 核心要点
- 现有VLA模型计算和内存需求巨大,难以在资源受限的边缘设备上实现实时控制。
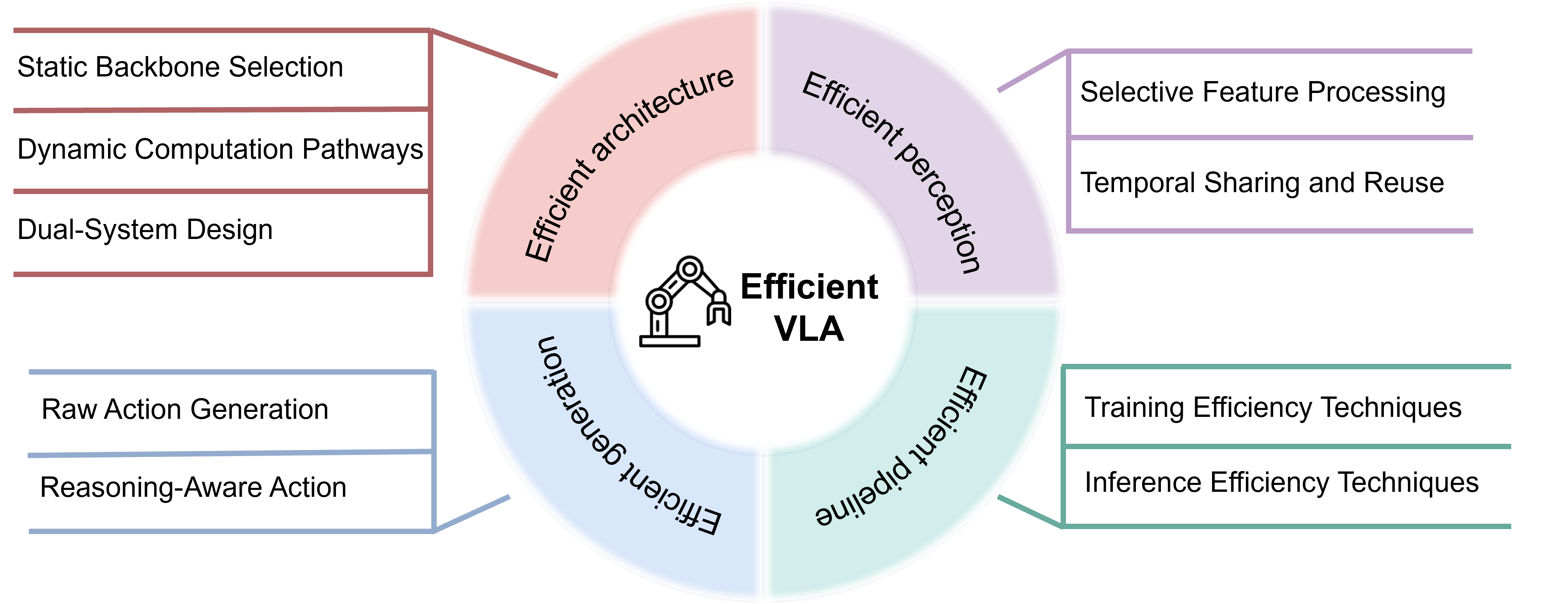
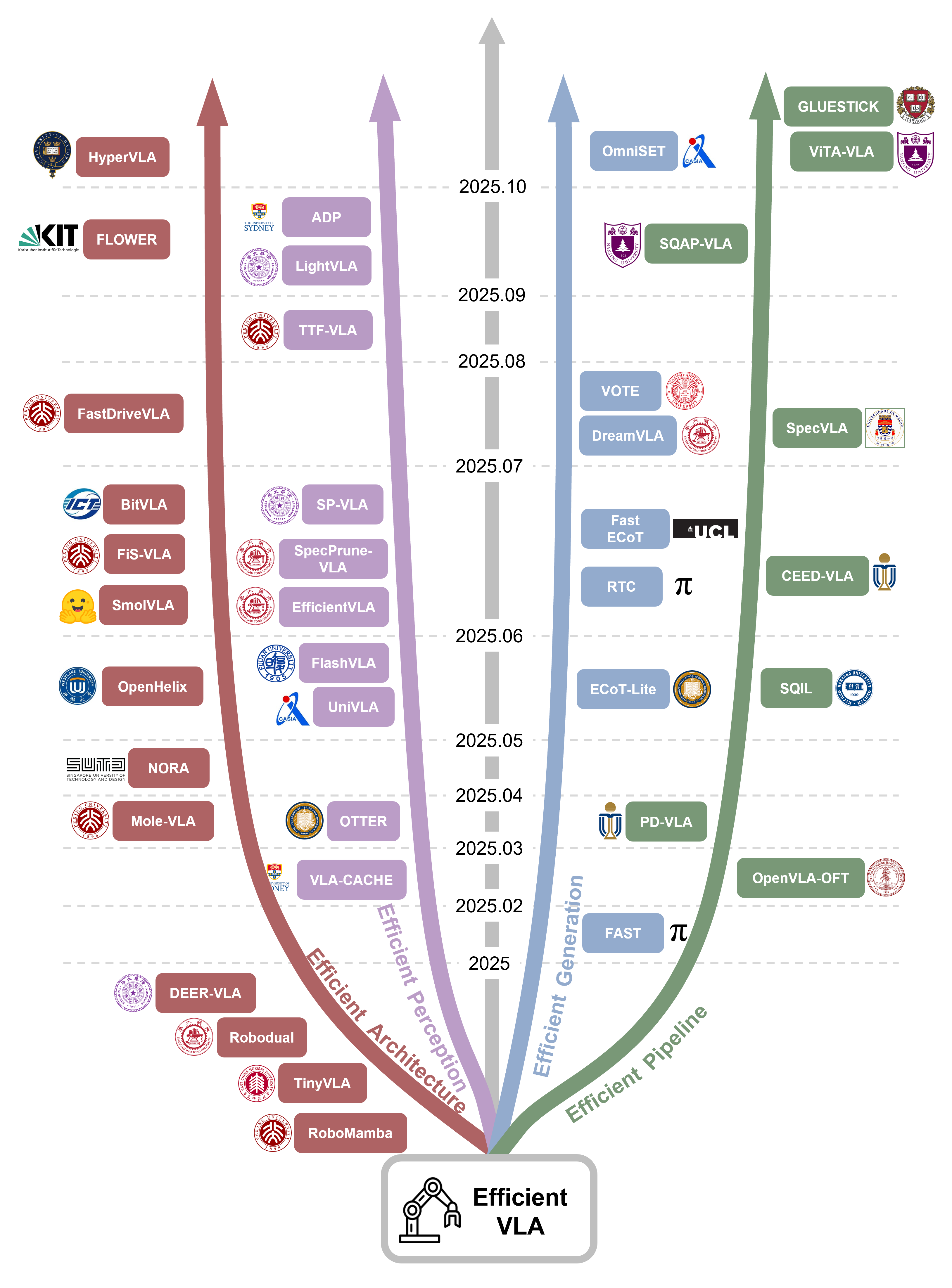
- 该综述系统性地分析了VLA模型效率提升方法,从模型架构、感知特征、动作生成和训练策略四个维度进行归类。
- 通过对现有技术的梳理和总结,为未来高效具身智能的研究方向提供了指导和参考。
📝 摘要(中文)
视觉-语言-动作(VLA)模型通过将自然语言指令和视觉观察映射到机器人动作,扩展了视觉-语言模型在具身控制方面的应用。尽管VLA系统具有强大的能力,但由于其巨大的计算和内存需求,它们面临着严峻的挑战,这与车载移动机械臂等边缘平台需要实时性能的约束相冲突。解决这种矛盾已成为近期研究的中心。鉴于在更高效和可扩展的VLA系统方面日益增长的努力,本综述系统地回顾了提高VLA效率的方法,重点是减少延迟、内存占用以及训练和推理成本。我们将现有解决方案分为四个维度:模型架构、感知特征、动作生成和训练/推理策略,总结了每个类别中的代表性技术。最后,我们讨论了未来的趋势和开放的挑战,强调了推进高效具身智能的方向。
🔬 方法详解
问题定义:论文旨在解决视觉-语言-动作(VLA)模型在具身操作中面临的效率问题。现有VLA模型通常需要大量的计算资源和内存,这使得它们难以部署在资源受限的边缘设备上,例如车载移动机械臂。因此,如何在保证性能的前提下,降低VLA模型的延迟、内存占用以及训练和推理成本,是当前研究面临的主要挑战。
核心思路:论文的核心思路是对现有VLA模型的效率提升方法进行系统性的分类和总结。通过分析不同方法在模型架构、感知特征、动作生成和训练/推理策略等方面的特点,为研究人员提供一个全面的视角,从而更好地理解和选择适合特定应用场景的优化方案。
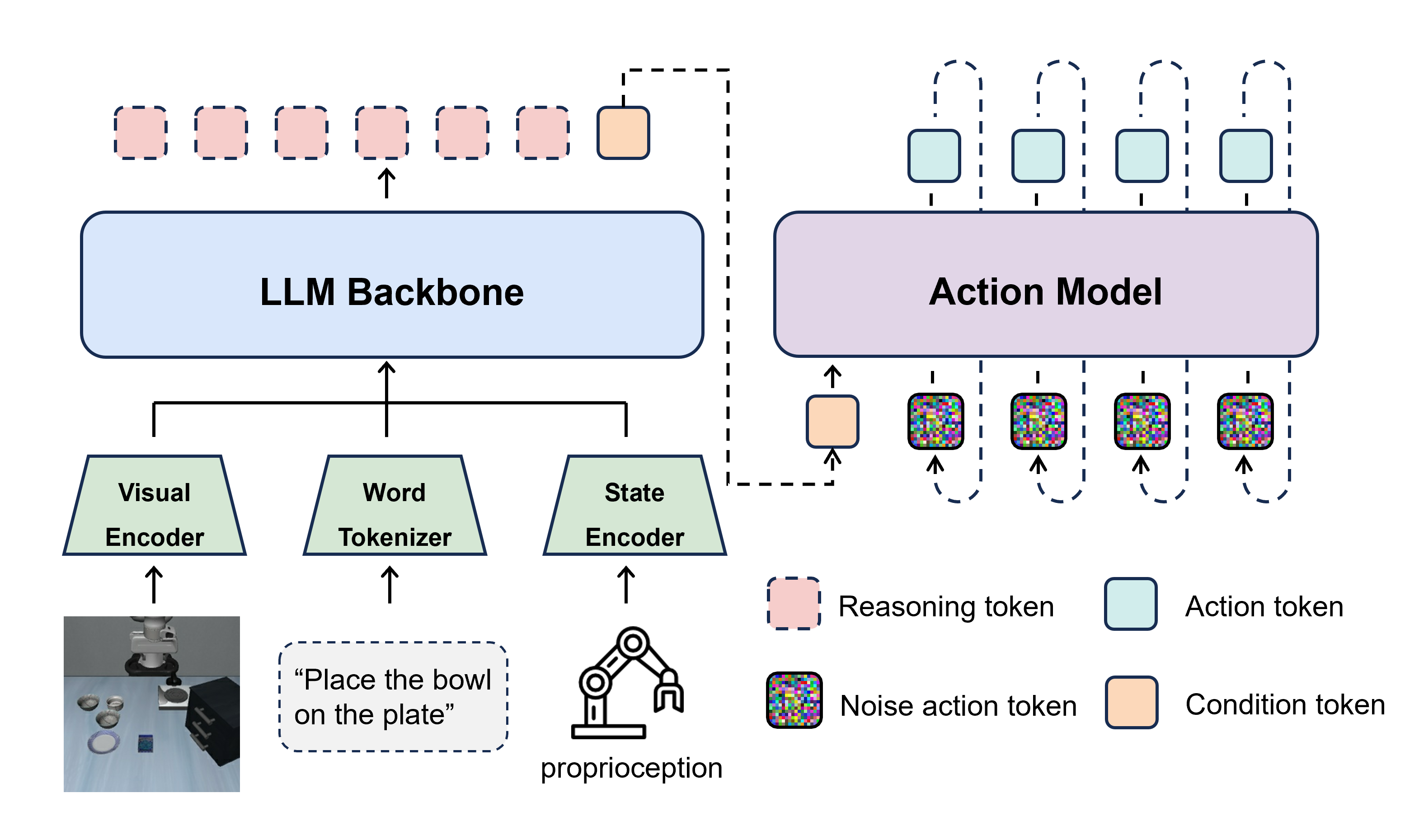
技术框架:该综述论文的技术框架主要包括以下几个部分:首先,对VLA模型的基本概念和应用场景进行介绍;其次,将现有的效率提升方法分为四个维度:模型架构、感知特征、动作生成和训练/推理策略;然后,对每个维度下的代表性技术进行详细的分析和比较;最后,对未来的研究方向和开放性问题进行展望。
关键创新:该综述的关键创新在于其系统性和全面性。它不仅对现有的VLA模型效率提升方法进行了全面的梳理,而且还从多个维度对这些方法进行了深入的分析和比较。这使得研究人员能够更好地理解不同方法的优缺点,从而更好地选择和应用这些方法。与以往的综述相比,该论文更加关注实际应用中的效率问题,并为未来的研究方向提供了更具体的指导。
关键设计:论文的关键设计在于其对VLA模型效率提升方法的分类方式。将现有方法分为模型架构、感知特征、动作生成和训练/推理策略四个维度,能够更清晰地展示不同方法之间的关系和差异。此外,论文还对每个维度下的代表性技术进行了详细的分析和比较,包括其原理、优缺点以及适用场景。这些分析和比较能够帮助研究人员更好地理解不同方法的特点,从而更好地选择和应用这些方法。
🖼️ 关键图片
📊 实验亮点
该综述系统地总结了VLA模型效率提升的现有方法,并将其归纳为四个维度。通过对每个维度下代表性技术的分析,为研究人员提供了全面的参考。此外,论文还指出了未来研究的潜在方向,例如模型压缩、知识蒸馏和硬件加速等,为后续研究提供了指导。
🎯 应用场景
该研究成果可应用于机器人自主导航、智能制造、家庭服务等领域。通过提升VLA模型的效率,可以使机器人能够在资源受限的环境下,更好地理解人类指令,并执行复杂的具身操作任务。这有助于提高机器人的智能化水平和应用范围,促进人机协作的进一步发展。
📄 摘要(原文)
Vision-Language-Action (VLA) models extend vision-language models to embodied control by mapping natural-language instructions and visual observations to robot actions. Despite their capabilities, VLA systems face significant challenges due to their massive computational and memory demands, which conflict with the constraints of edge platforms such as on-board mobile manipulators that require real-time performance. Addressing this tension has become a central focus of recent research. In light of the growing efforts toward more efficient and scalable VLA systems, this survey provides a systematic review of approaches for improving VLA efficiency, with an emphasis on reducing latency, memory footprint, and training and inference costs. We categorize existing solutions into four dimensions: model architecture, perception feature, action generation, and training/inference strategies, summarizing representative techniques within each category. Finally, we discuss future trends and open challenges, highlighting directions for advancing efficient embodied intelligence.