DINO-CVA: A Multimodal Goal-Conditioned Vision-to-Action Model for Autonomous Catheter Navigation
作者: Pedram Fekri, Majid Roshanfar, Samuel Barbeau, Seyedfarzad Famouri, Thomas Looi, Dale Podolsky, Mehrdad Zadeh, Javad Dargahi
分类: cs.RO, cs.AI, cs.CV
发布日期: 2025-10-19
💡 一句话要点
DINO-CVA:用于自主导管导航的多模态目标条件视觉-动作模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 导管导航 多模态融合 行为克隆 目标条件 自主机器人
📋 核心要点
- 现有心脏导管手术依赖人工操作,机器人系统也多为跟随模式,导致医生疲劳和手术结果不稳定。
- DINO-CVA融合视觉信息和运动学数据,通过行为克隆学习专家策略,实现目标导向的自主导航。
- 实验表明,DINO-CVA能准确预测动作,性能与运动学基线相当,并能感知解剖环境。
📝 摘要(中文)
心脏导管插入术是微创介入治疗的基石,但仍然严重依赖手动操作。尽管机器人平台取得了进展,但现有系统主要采用跟随者模式,需要医生持续输入,缺乏智能自主性。这种依赖性导致操作者疲劳、更多辐射暴露以及手术结果的变异性。本文提出了DINO-CVA,一个多模态目标条件行为克隆框架,旨在实现自主导管导航。该模型将视觉观察和操纵杆运动学融合到联合嵌入空间中,从而实现具有视觉感知和运动学感知的策略。动作从专家演示中自回归预测,目标条件引导导航到指定目的地。设计了一个带有合成血管幻影的机器人实验装置来收集多模态数据集并评估性能。结果表明,DINO-CVA在预测动作方面实现了高精度,与仅使用运动学的基线性能相匹配,同时还将预测建立在解剖环境的基础上。这些发现确立了多模态、目标条件架构在导管导航中的可行性,代表着朝着减少操作者依赖性和提高基于导管的治疗可靠性的重要一步。
🔬 方法详解
问题定义:心脏导管手术依赖手动操作,现有机器人辅助系统智能化程度低,医生需要持续控制,导致疲劳和手术结果差异。因此,需要开发一种自主导航系统,减少医生干预,提高手术效率和一致性。
核心思路:DINO-CVA的核心思路是利用多模态信息(视觉和运动学)进行行为克隆,学习专家操作策略。通过融合视觉信息,使模型能够感知环境,从而在导航过程中做出更合理的决策。目标条件设定则允许模型根据预设目标自主规划路径。
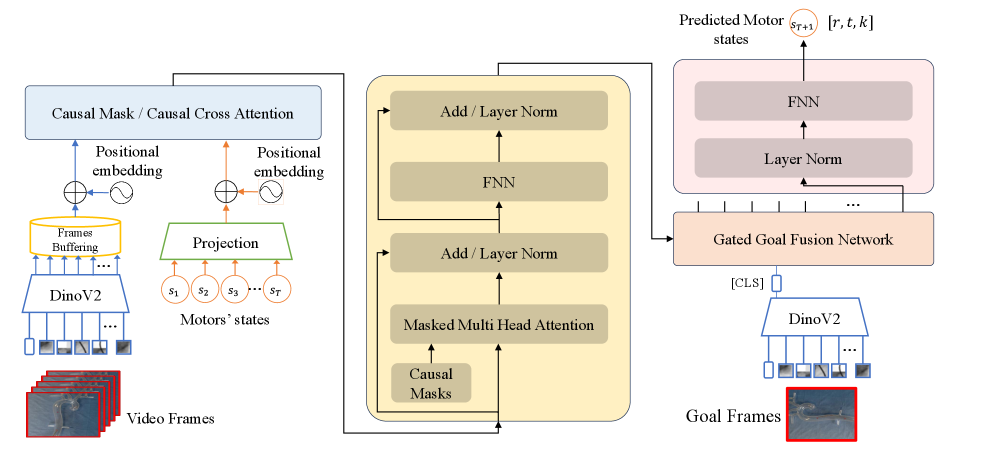
技术框架:DINO-CVA是一个多模态目标条件行为克隆框架。它包含以下主要模块:1) 多模态数据编码器:将视觉观察和操纵杆运动学数据编码到联合嵌入空间。2) 自回归动作预测器:基于编码后的嵌入和目标条件,自回归地预测动作序列。3) 目标条件模块:接收目标位置信息,并将其融入到动作预测过程中。整体流程是从专家演示数据中学习,然后利用学习到的策略在新的环境中进行自主导航。
关键创新:DINO-CVA的关键创新在于多模态融合和目标条件设定。传统方法通常只依赖运动学数据,而DINO-CVA通过融合视觉信息,使模型能够感知环境,从而做出更明智的决策。目标条件设定则允许模型根据预设目标自主规划路径,无需人工干预。
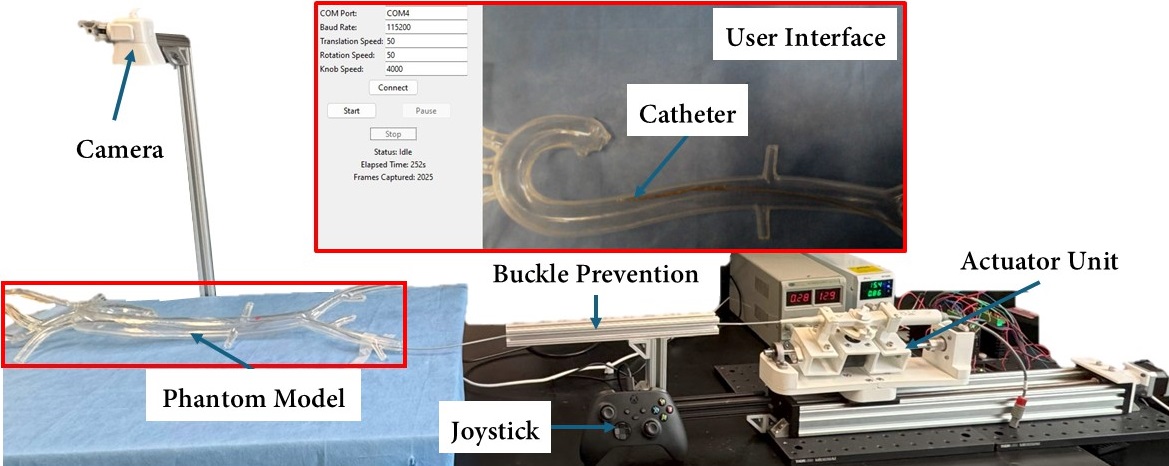
关键设计:DINO-CVA使用Transformer架构进行自回归动作预测。损失函数采用标准的行为克隆损失,即最小化预测动作与专家动作之间的差异。在实验中,作者设计了一个合成血管幻影,并使用机器人平台收集了多模态数据集。具体参数设置和网络结构细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
DINO-CVA在合成血管幻影实验中表现出色,能够准确预测导管动作,与仅使用运动学信息的基线方法性能相当,同时还能感知解剖环境。这表明DINO-CVA在导管导航方面具有可行性,为实现自主导管手术奠定了基础。具体的性能指标和提升幅度未在摘要中给出,属于未知信息。
🎯 应用场景
DINO-CVA有望应用于心脏导管手术、血管介入治疗等领域,实现导管的自主导航和精准定位,减少医生操作负担,降低辐射暴露,提高手术效率和一致性。该技术还可扩展到其他医疗机器人应用,例如内窥镜检查、微创手术等,具有广阔的应用前景。
📄 摘要(原文)
Cardiac catheterization remains a cornerstone of minimally invasive interventions, yet it continues to rely heavily on manual operation. Despite advances in robotic platforms, existing systems are predominantly follow-leader in nature, requiring continuous physician input and lacking intelligent autonomy. This dependency contributes to operator fatigue, more radiation exposure, and variability in procedural outcomes. This work moves towards autonomous catheter navigation by introducing DINO-CVA, a multimodal goal-conditioned behavior cloning framework. The proposed model fuses visual observations and joystick kinematics into a joint embedding space, enabling policies that are both vision-aware and kinematic-aware. Actions are predicted autoregressively from expert demonstrations, with goal conditioning guiding navigation toward specified destinations. A robotic experimental setup with a synthetic vascular phantom was designed to collect multimodal datasets and evaluate performance. Results show that DINO-CVA achieves high accuracy in predicting actions, matching the performance of a kinematics-only baseline while additionally grounding predictions in the anatomical environment. These findings establish the feasibility of multimodal, goal-conditioned architectures for catheter navigation, representing an important step toward reducing operator dependency and improving the reliability of catheterbased therapies.