MoS-VLA: A Vision-Language-Action Model with One-Shot Skill Adaptation
作者: Ruihan Zhao, Tyler Ingebrand, Sandeep Chinchali, Ufuk Topcu
分类: cs.RO
发布日期: 2025-10-18
💡 一句话要点
MoS-VLA:基于技能组合的VLA模型,实现机器人单样本技能迁移
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉语言动作模型 机器人学习 技能迁移 单样本学习 凸优化
📋 核心要点
- 现有VLA模型在面对新环境、新机器人或新任务时,泛化能力不足,难以直接应用。
- MoS-VLA将机器人策略表示为技能基函数的线性组合,通过优化组合系数实现技能迁移。
- 实验表明,MoS-VLA在未见数据集上降低了动作预测误差,并在真实机器人任务中成功应用。
📝 摘要(中文)
本文提出了一种名为混合技能视觉-语言-动作模型(MoS-VLA)的框架,旨在解决视觉-语言-动作(VLA)模型在新的环境、机器人形态或任务中部署时泛化能力不足的问题。MoS-VLA将机器人操作策略表示为一组学习到的基函数的线性组合,在Open X-Embodiment项目的数据集上联合学习这些基函数,从而产生结构化的技能空间。在测试时,适应新任务仅需一个专家演示。通过一个轻量级的凸优化问题推断相应的技能表示,该优化问题旨在最小化L1动作误差,无需梯度更新。这种无梯度适应方法开销极小,同时能够快速实例化新技能。实验结果表明,MoS-VLA在五个未见数据集中的五个数据集上实现了更低的动作预测误差,并在预训练VLA模型完全失败的模拟和真实机器人任务中取得了成功。
🔬 方法详解
问题定义:现有视觉-语言-动作(VLA)模型在预训练后,难以直接适应新的机器人环境、机器人形态或任务。主要痛点在于缺乏有效的技能迁移机制,需要大量的重新训练或微调才能适应新场景,计算成本高昂,泛化能力受限。
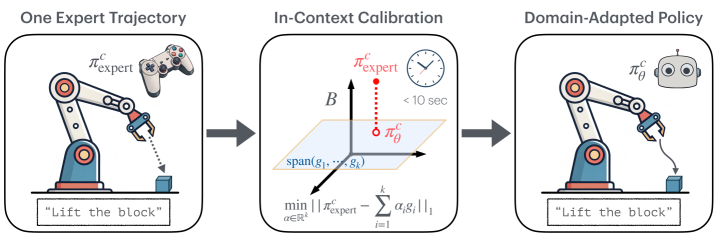
核心思路:MoS-VLA的核心思路是将复杂的机器人操作策略分解为一组预先学习好的、具有代表性的技能基函数的线性组合。通过学习这些基函数,模型能够构建一个结构化的技能空间。当需要适应新任务时,只需要确定这些基函数的组合权重,而无需从头开始学习新的策略。
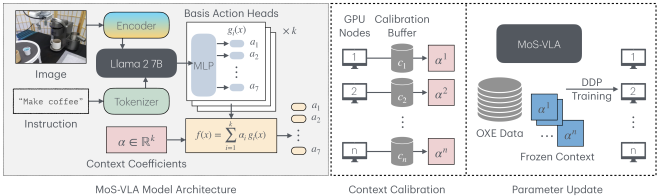
技术框架:MoS-VLA框架包含预训练和适应两个主要阶段。在预训练阶段,模型在大量机器人数据集上学习一组技能基函数。这些基函数共同构成一个技能空间。在适应阶段,给定一个新任务的单样本演示,模型通过凸优化方法,求解技能基函数的组合权重,使得组合后的动作序列尽可能接近演示动作。最终,模型使用学习到的技能组合权重来控制机器人在新任务中的行为。
关键创新:MoS-VLA的关键创新在于其基于技能组合的策略表示方法和无梯度的单样本适应机制。与传统的VLA模型相比,MoS-VLA不需要对整个模型进行微调,而是通过优化技能组合权重来实现快速适应。这种无梯度适应方法避免了复杂的梯度计算,降低了计算成本,提高了适应速度。
关键设计:MoS-VLA使用L1损失函数来衡量预测动作与演示动作之间的差异,并使用凸优化方法求解技能组合权重。选择L1损失函数是为了增强模型的鲁棒性,减少异常值的影响。技能基函数的数量是一个重要的超参数,需要根据具体任务进行调整。网络结构方面,MoS-VLA可以使用各种现有的VLA模型作为骨干网络,例如Transformer或RNN。
🖼️ 关键图片
📊 实验亮点
MoS-VLA在五个未见数据集上实现了更低的动作预测误差,证明了其良好的泛化能力。在模拟和真实机器人任务中,MoS-VLA成功完成了预训练VLA模型无法完成的任务。单样本适应机制使得MoS-VLA能够快速适应新任务,大大降低了技能学习的成本。实验结果表明,MoS-VLA是一种有效的机器人技能迁移方法。
🎯 应用场景
MoS-VLA具有广泛的应用前景,例如在智能制造、家庭服务机器人、医疗机器人等领域。它可以帮助机器人在不同环境中快速学习新的操作技能,提高机器人的灵活性和适应性。该研究的实际价值在于降低了机器人技能学习的成本,加速了机器人在现实世界中的部署。未来,MoS-VLA可以进一步扩展到更复杂的任务和环境,实现更高级别的机器人自主性。
📄 摘要(原文)
Vision-Language-Action (VLA) models trained on large robot datasets promise general-purpose, robust control across diverse domains and embodiments. However, existing approaches often fail out-of-the-box when deployed in novel environments, embodiments, or tasks. We introduce Mixture of Skills VLA (MoS-VLA), a framework that represents robot manipulation policies as linear combinations of a finite set of learned basis functions. During pretraining, MoS-VLA jointly learns these basis functions across datasets from the Open X-Embodiment project, producing a structured skill space. At test time, adapting to a new task requires only a single expert demonstration. The corresponding skill representation is then inferred via a lightweight convex optimization problem that minimizes the L1 action error, without requiring gradient updates. This gradient-free adaptation incurs minimal overhead while enabling rapid instantiation of new skills. Empirically, MoS-VLA achieves lower action-prediction error on five out of five unseen datasets and succeeds in both simulation and real-robot tasks where a pretrained VLA model fails outright. Project page: mos-vla.github.io/